Java, XML, and Databases
By Mario Aquino, OCI Software Engineer
October 2002
Introduction
XML and its supporting technologies XML Schema and XSL Transformation provide very powerful mechanisms to describe, validate, and transform data. Using these technologies, applications can be made to communicate and share data with other systems, regardless of platform incompatibilities. This article focuses on the process of automatically generating XML instance documents as well as XML Schemas by querying the contents and structure of database tables using Java's JDBC Metadata capabilities and XSL Stylesheets.
Motivation
A common (though awkward) way to create XML objects is by writing a method equivalent to toXML() inside of a value object class so that instances can write out their state to an XML representation. Typically in this approach, a query is made to a database to retrieve a number of rows of data. The result set returned by the database is used to create instances of value objects that temporarily store the data internally, then convert their state into an XML document. This code may look may look something like this:
- import org.w3c.dom.*;
- import javax.xml.parsers.*;
- public class ValueObject {
- private String someData;
- private int someNumber;
- ...
- //Standard accessor methods...
- public String getSomeData() {
- return someData;
- }
- ...
- //Standard mutator method...
- public void setSomeData(String somedata) {
- someData = somedata;
- }
- ...
- //And the toXML() method
- public org.w3c.dom.Document toXML() {
- Document doc = null;
- try {
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- DocumentBuilder db = dbf.newDocumentBuilder();
- Document doc = db..newDocument();
- Element root = doc.createElement("ValueObject");
- doc.appendChild(root);
- Element node = doc.createElement("someData");
- root.appendChild(node);
- Text value = doc.createTextNode(someData);
- node.appendChild(value);
- ...//And so on for all the fields
- } catch (Exception e) {
- //Bad form, but just for demonstration!
- }
- return doc;
- }
- }
Then, there has to be another class that queries the database and retrieves data from the ResultSet returned by the query. This class has to know both the names and datatypes of the columns in the database as well as the names of the mutator methods on the ValueObject class. Briefly, the code in this class looks something like this:
- ...//Assuming the class uses a Statement object to get the results from the DB
- ResultSet rs = stmt.executeQuery(someSQLString);
- List collection = new ArrayList(); //Collection to hold all the ValueObjects
- ValueObject vo = null;
- while(rs.next()) {
- vo = new ValueObject();
- vo.setSomeData(rs.getString("SOME_DATA_COLUMN_NAME"));
- vo.setSomeNumber(rs.getInteger("SOME_NUMBER_COLUMN_NAME"));
- ...//Continue for all the columns that the result set returns
- collection.add(vo);
- }
- //Then eventually some code will get the contents of the ValueObject as
- //a Document object
- Document doc = someValueObjectInstance.toXML();
All this is too much work just to get some data into an XML document (regardless of where it is going) not to mention all the dependencies that are introduced by explicitly referring to table column names and object mutator methods. A much better approach is through the use of metadata interfaces that are part of Java's JDBC API to retrieve the names and datatypes of the columns returned in a ResultSet and use that information to build XML instance documents on the fly. Before getting into the details of dynamically generated XML documents, a brief review of database concepts and an examination of two of the JDBC metadata interfaces is in order.
Databases and Metadata
Many if not all relational database products follow a model of data structures or entities defined as tables with a fixed number of named columns, each of which responsible for storing data of a particular type. Additionally, relationships between columns in the tables can usually be indicated throught the use of primary and foreign keys; primary keys representing columns in a table that are required to contain unique values or combinations of values and foreign keys representing columns in a table that contain a reference value that is uniquely defined in another table in the database. Using primary and foreign keys, databases are able to maintain "referential integrity" for the data items they store, that is, they can enforce relationships that define business requirements inherent to the data. All these details comprise the "metadata" that defines the structure of database tables.
The diagram below depicts tables that are part of a database called "Regatta". This database stores records that represent the results of sail boat races.
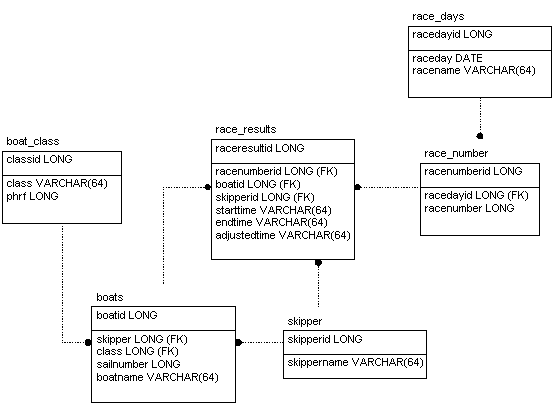
The tables each define their columns with a name and a datatype. As well, primary keys appear in the top most area of the rectangles and the columns that represent foreign keys have (FK) next to their datatypes. Finally, dotted lines are drawn between some of the tables to identify the foreign key relationships; the closed end of the dotted lines rests on the table that defines a foreign key column that refers to a primary key column in the table at the other end of the line.
Database Metadata
Java's JDBC API provides several interfaces that support the retrieval of data stored in a database. The API also includes interfaces that can gather details about a database itself, the kinds of operations it supports, as well as information about the tables it contains. One such interface is appropriately named DatabaseMetaData. This interface can be used to find out everything about a database from the number and names of schemas it includes, to the tables defined in those schemas, to the columns contained in the tables, to the relationships those columns may have with columns in other tables elsewhere in the database.
With its ability to discover the entire structure of a database, this interface can be used to create XML Schemas for the purposes of mapping entities defined in a database to structures that exist in an XML document. XML Schemas declare the structures and their relationships that are allowed in an XML interface much like a database schema. An XML Schema can be used to validate XML instance documents that claim to adhere to the rules defined the schema. Document description and definition are most important when two systems need to share data via XML interfaces. XML Schemas that back the data structures exchanged by interfacing systems can be used to validate the data as it passes from the sending to the receiving system.
Result Set Metadata
The JDBC API also provides an interface to discover metadata details about rows returned in result sets. The ResultSetMetaData interface provides information about each of the columns in a ResultSet including the column names, data types, precision, nullability, searchability, etc. The utility of this as well as the DatabaseMetaData interface can be realized through the creation of tools that dynamically generate XML documents from database result sets or from the very details of the entities managed by the database itself.
Implementation
With relatively little effort, it is possible to see just how valuable interfaces that provide metadata about databases and result sets can be. Below is some code that takes a ResultSet and, using the ResultSetMetaData interface, creates an XML document from its contents.
- import java.sql.*;
- import javax.xml.parsers.*;
- import org.w3c.dom.*;
- ...
- public Document convertRSToDocument(ResultSet rs) {
- Document doc = null;
-
- try {
- ResultSetMetaData rsmd = rs.getMetaData();
-
- //Get an array of columns from the RSMetaData
- String[] columns = new String[rsmd.getColumnCount()];
- for (int i = 0; i < columns.length; i++) {
- //The set of column names begins with '1' rather than '0'
- columns[i] = rsmd.getColumnName(i + 1);
- }
-
- //Get an array of the types of each RS column from the RSMetaData
- int[] columnTypes = new int[columns.length];
- for (int i = 0; i < columnTypes.length; i++) {
- //The set of column types also begins with '1' rather than '0'
- columnTypes[i] = rsmd.getColumnType(i + 1);
- }
-
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
- DocumentBuilder db = dbf.newDocumentBuilder();
- doc = db.newDocument();
-
- Element root = doc.createElement("ResultSet");
- doc.appendChild(root);
-
- Text text = null;
- //We are now ready to loop through the ResultSet. For each row found,
- //we add new elements that are named after the columns in the ResultSet,
- //have an attribute that mentions the formal (SQL) type of the result, and
- //hold the value for the column in each row
- while (rs.next()) {
- Element row = doc.createElement("row");
- root.appendChild(row);
-
- //Each row has a fixed set of columns, loop through each
- //column, testing against the type of the column as indicated in the
- //ResultSetMetaData interface.
- for (int i = 0; i < columns.length; i++) {
- Element elem = doc.createElement(columns[i]);
- row.appendChild(elem);
-
- switch (columnTypes[i]) {
- case Types.BIGINT:
- long bint = rs.getLong(i + 1);
- //Add a 'type' attribute to the element. This may be
- //useful in identifying how the data should be handled
- //if it is read from the Document later on
- elem.setAttribute("type", "BigInt");
- text = doc.createTextNode(Long.toString(bint));
- break;
- case Types.BOOLEAN:
- boolean bool = rs.getBoolean(i + 1);
- elem.setAttribute("type", "boolean");
- text = doc.createTextNode(Boolean.toString(bool));
- break;
- case Types.DATE:
- ...//And so on for all the types defined in java.sql.Types
- case Types.LONGVARCHAR:
- case Types.VARCHAR:
- String str = rs.getString(i + 1);
- elem.setAttribute("type", "Varchar");
- if (str == null) {
- //Add a null attribute to the element to represent null
- //value in the database
- elem.setAttribute("null", "true");
- str = "";
- }
- text = (Text)doc.createCDATASection(str);
- break;
- default:
- //log here because we didn't figure out
- //what this thing was
- log.warn("Unknown element type found!!!");
- log.warn("Column = " + columns[i]);
- elem.setAttribute("type", "Unknown");
- text = doc.createTextNode("");
- break;
- }
- elem.appendChild(text);
- }
- }
-
- } catch (SQLException sqle) {
- //Handle the exception in some way
- } catch (ParserConfigurationException pce) {
- //Handle the exception in some way
- }
- return doc;
- }
Compared to the first approach described in this article, this method provides a much easier way of building an XML document from data that resides in a database. Using the Regatta database as an example, lets create an XML document containing race results for all boats in the "J-24" boat class using the method above:
- <?xml version="1.0" encoding="UTF-8"?>
- <ResultSet>
- <row>
- <raceday type="Date">2002-09-15</raceday>
- <racenumber type="integer">1</racenumber>
- <boatname type="Varchar"><![CDATA[Gertrude]]></boatname>
- <name type="Varchar"><![CDATA[Jane Seamore]]></name>
- <starttime type="Varchar"><![CDATA[09:00:01]]></starttime>
- <endtime type="Varchar"><![CDATA[12:00:01]]></endtime>
- <adjustedtime type="Varchar"><![CDATA[3:0:0]]></adjustedtime>
- <class type="Varchar"><![CDATA[J 24]]></class>
- </row>
- <row>
- <raceday type="Date">2002-06-16</raceday>
- <racenumber type="integer">1</racenumber>
- <boatname type="Varchar"><![CDATA[Big Bess]]></boatname>
- <name type="Varchar"><![CDATA[Peter Tosh]]></name>
- <starttime type="Varchar"><![CDATA[08:00:01]]></starttime>
- <endtime type="Varchar"><![CDATA[12:12:12]]></endtime>
- <adjustedtime type="Varchar"><![CDATA[4:12:11]]></adjustedtime>
- <class type="Varchar"><![CDATA[J 24]]></class>
- </row>
- <row>
- <raceday type="Date">2002-09-15</raceday>
- <racenumber type="integer">1</racenumber>
- <boatname type="Varchar"><![CDATA[Lucky Slew]]></boatname>
- <name type="Varchar"><![CDATA[Harvey Wallbanger]]></name>
- <starttime type="Varchar"><![CDATA[09:00:01]]></starttime>
- <endtime type="Varchar"><![CDATA[14:41:00]]></endtime>
- <adjustedtime type="Varchar"><![CDATA[5:40:59]]></adjustedtime>
- <class type="Varchar"><![CDATA[J 24]]></class>
- </row>
- <row>
- <raceday type="Date">2002-09-15</raceday>
- <racenumber type="integer">1</racenumber>
- <boatname type="Varchar"><![CDATA[Monkey Business]]></boatname>
- <name type="Varchar"><![CDATA[Gary Hart]]></name>
- <starttime type="Varchar"><![CDATA[09:00:01]]></starttime>
- <endtime type="Varchar"><![CDATA[14:09:00]]></endtime>
- <adjustedtime type="Varchar"><![CDATA[5:8:59]]></adjustedtime>
- <class type="Varchar"><![CDATA[J 24]]></class>
- </row>
- </ResultSet>
With the data in XML format, there are now a great number of things that can be done depending on whether the data is ready to be consumed or if it needs to be transformed to fit a different organizational model. If the data does need to be rearranged, the Document could be passed to an XSL Stylesheet to transform its content into a more meaningful format.
Creating an XML Schema to match the organization of the database is made using the DatabaseMetaData interface and through the use of the ResultSet to Document conversion method. The code example below shows how a few calls to the DatabaseMetaData interface reveal all the details about the structures and relationships defined in the database schema.
- public Document getDBMetadataAsDocument(String catalog, String schemaPattern,
- String tableNamePattern, String[] types)
- {
- Document doc = null;
- DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
-
- try {
- DocumentBuilder db = dbf.newDocumentBuilder();
- doc = db.newDocument();
- Element root = doc.createElement("root");
- doc.appendChild(root);
-
- DatabaseMetaData dbmd = conn.getMetaData();
- //Retrieve a list of the tables belonging to the catalog and
- //database schema indicated in the call to this method
- ResultSet rs = dbmd.getTables(catalog, schemaPattern, tableNamePattern, types);
- Element tables = doc.createElement("tables");
- root.appendChild(tables);
-
- //All the details about the returned tables are now added to
- //the main document
- tables.appendChild(
- doc.importNode(
- convertRSToDocument(rs).getDocumentElement(),
- true));
- //Our document now has all the tables in the database. For each
- //table, we need to get the rest of the metadata.
- //To get the table names, we need to query the document for any
- //elements called 'TABLE_NAME'. These came from the call that was just made.
- NodeList nodes = doc.getElementsByTagName("TABLE_NAME");
- String[] tableNames = new String[nodes.getLength()];
- for (int i = 0; i < nodes.getLength(); i++) {
- tableNames[i] = nodes.item(i).getFirstChild().getNodeValue();
- }
-
- for (int i = 0; i < tableNames.length; i++) {
- //Getting table columns...
- rs = dbmd.getColumns(catalog, schemaPattern, tableNames[i], null);
- addResultsToNode(rs, root, "columns")
-
- //Getting primary keys...
- rs = dbmd.getPrimaryKeys(catalog, schemaPattern, tableNames[i]);
- addResultsToNode(rs, root, "primarykeys");
-
- //Getting foreign keys and where they point...
- rs = dbmd.getImportedKeys(catalog, schemaPattern, tableNames[i]);
- addResultsToNode(rs, root, "importedkeys");
-
- }
-
- //Change the DATA_TYPE elements to their SQL type names just for
- //aesthetics... They are actually returned as integers by the
- //DatabaseMetaData API
- nodes = doc.getElementsByTagName("DATA_TYPE");
- for (int i = 0; i < nodes.getLength(); i++) {
- int type = Integer.parseInt(
- nodes.item(i).getFirstChild().getNodeValue());
- switch(type) {
- case Types.ARRAY:
- nodes.item(i).getFirstChild().setNodeValue("Array");
- break;
- case Types.BIGINT:
- nodes.item(i).getFirstChild().setNodeValue("BigInt");
- break;
- case Types.BINARY:
- nodes.item(i).getFirstChild().setNodeValue("Binary");
- break;
- case Types.BIT:
- nodes.item(i).getFirstChild().setNodeValue("Bit");
- break;
- ...//And so on for all valid SQL types (Defined in java.sql.Types)
- case Types.VARCHAR:
- nodes.item(i).getFirstChild().setNodeValue("Varchar");
- break;
- default:
- nodes.item(i).getFirstChild().setNodeValue("Unknown");
- break;
- }
- }
-
- } catch (SQLException sqle) {
- //Handle the exception in some way
- } catch (ParserConfigurationException pce) {
- //Handle the exception in some way
- } catch (DOMException de) {
- //Handle the exception in some way
- }
- return doc;
- }
-
- private void addResultsToNode(ResultSet rs, Node node, String elementName)
- throws DOMException
- {
- Document doc = null;
- if (node instanceof Document) {
- doc = (Document)node;
- } else {
- doc = node.getOwnerDocument();
- }
- Element elem = doc.createElement(elementName);
- node.appendChild(elem);
-
- //The call below does several things:
- //1) It converts the ResultSet that was retrieved earlier from a call to the
- //DatabaseMetaData into a Document object (using the convertRSToDocument()
- //method that appears above)
- //2) It imports (through a deep copy) all of the nodes from the new Document
- //object into the Document object of the node based into the call to this
- //method
- //3) It adds those newly imported nodes as children of a node to the
- //main document
- elem.appendChild(
- doc.importNode(
- convertRSToDocument(rs).getDocumentElement(),
- true));
- }
The method above creates a Document with details about the schema of a particular database. Using the Regatta database (from above), it is possible to see what this database metadata gathering method provides:
- <?xml version="1.0" encoding="UTF-8"?>
- <root>
- <tables>
- <ResultSet>
- <row>
- <TABLE_CAT type="Varchar" null="true"></TABLE_CAT>
- <TABLE_SCHEM type="Varchar" null="true"></TABLE_SCHEM>
- <TABLE_NAME type="Varchar"><![CDATA[boat_class]]></TABLE_NAME>
- <TABLE_TYPE type="Varchar"><![CDATA[TABLE]]></TABLE_TYPE>
- <REMARKS type="Varchar" null="true"></REMARKS>
- </row>
- <row>
- <TABLE_CAT type="Varchar" null="true"></TABLE_CAT>
- <TABLE_SCHEM type="Varchar" null="true"></TABLE_SCHEM>
- <TABLE_NAME type="Varchar"><![CDATA[boats]]></TABLE_NAME>
- <TABLE_TYPE type="Varchar"><![CDATA[TABLE]]></TABLE_TYPE>
- <REMARKS type="Varchar" null="true"></REMARKS>
- </row>
-
- <!--...And so on for the rest of the tables-->
This is what the column nodes look like:
- <columns>
- <ResultSet>
- <row>
- <TABLE_CAT type="Varchar" null="true"></TABLE_CAT>
- <TABLE_SCHEM type="Varchar" null="true"></TABLE_SCHEM>
- <TABLE_NAME type="Varchar"><![CDATA[boat_class]]></TABLE_NAME>
- <COLUMN_NAME type="Varchar"><![CDATA[classid]]></COLUMN_NAME>
- <DATA_TYPE type="TinyInt">Integer</DATA_TYPE>
- <TYPE_NAME type="Varchar"><![CDATA[int4]]></TYPE_NAME>
- <COLUMN_SIZE type="integer">4</COLUMN_SIZE>
- <BUFFER_LENGTH type="Varchar" null="true"></BUFFER_LENGTH>
- <DECIMAL_DIGITS type="integer">0</DECIMAL_DIGITS>
- <NUM_PREC_RADIX type="integer">10</NUM_PREC_RADIX>
- <NULLABLE type="integer">0</NULLABLE>
- <REMARKS type="Varchar" null="true"></REMARKS>
- <COLUMN_DEF type="Varchar"><![CDATA[nextval('"boat_class_classid_seq"'::text)]]></COLUMN_DEF>
- <SQL_DATA_TYPE type="integer">0</SQL_DATA_TYPE>
- <SQL_DATETIME_SUB type="integer">0</SQL_DATETIME_SUB>
- <CHAR_OCTET_LENGTH type="Varchar"><![CDATA[4]]></CHAR_OCTET_LENGTH>
- <ORDINAL_POSITION type="integer">1</ORDINAL_POSITION>
- <IS_NULLABLE type="Varchar"><![CDATA[NO]]></IS_NULLABLE>
- </row>
-
- <!--...And so on for the rest of the columns-->
The primary key nodes look like this:
- <primarykeys>
- <ResultSet>
- <row>
- <table_cat type="Unknown"></table_cat>
- <table_schem type="Unknown"></table_schem>
- <table_name type="Varchar"><![CDATA[boat_class]]></table_name>
- <column_name type="Varchar"><![CDATA[classid]]></column_name>
- <key_seq type="TinyInt">1</key_seq>
- <pk_name type="Varchar"><![CDATA[boat_class_pk]]></pk_name>
- </row>
- </ResultSet>
- </primarykeys>
And the foreign key nodes (referred to as importedkeys in the API) look like this:
- <importedkeys>
- <ResultSet>
- <row>
- <PKTABLE_CAT type="Varchar" null="true"></PKTABLE_CAT>
- <PKTABLE_SCHEM type="Varchar" null="true"></PKTABLE_SCHEM>
- <PKTABLE_NAME type="Varchar"><![CDATA[boat_class]]></PKTABLE_NAME>
- <PKCOLUMN_NAME type="Varchar"><![CDATA[classid]]></PKCOLUMN_NAME>
- <FKTABLE_CAT type="Varchar" null="true"></FKTABLE_CAT>
- <FKTABLE_SCHEM type="Varchar" null="true"></FKTABLE_SCHEM>
- <FKTABLE_NAME type="Varchar"><![CDATA[boats]]></FKTABLE_NAME>
- <FKCOLUMN_NAME type="Varchar"><![CDATA[class]]></FKCOLUMN_NAME>
- <KEY_SEQ type="TinyInt">0</KEY_SEQ>
- <UPDATE_RULE type="TinyInt">3</UPDATE_RULE>
- <DELETE_RULE type="TinyInt">3</DELETE_RULE>
- <FK_NAME type="Varchar"><![CDATA[boats_class_fk]]></FK_NAME>
- <PK_NAME type="Varchar"><![CDATA[boat_class_pk]]></PK_NAME>
- <DEFERRABILITY type="TinyInt">7</DEFERRABILITY>
- </row>
-
- <!--...And so on for the rest of the foreign keys-->
While the data in this format seems useful, what is really desired is an XML Schema that reflects the structures and relationships defined within the database. To get the XML document (partially displayed above) into XML Schema format, an XSL Stylesheet is needed to transform and reorganize the data into a notation that follows XML Schema language. As it turns out, the stylesheet to create the XML Schema from this document is surprisingly simple:
- <?xml version="1.0" encoding="UTF-8"?>
- <xsl:stylesheet version="1.0"
- xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
- xmlns:xs="http://www.w3.org/2001/XMLSchema">
- <xsl:output method="xml" indent="yes" encoding="UTF-8" version="1.0"></xsl:output>
-
- <xsl:template match="/">
- <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
- <xsl:apply-templates select="//tables//TABLE_NAME"></xsl:apply>
- </xs:schema>
- </xsl:template>
-
- <xsl:template match="TABLE_NAME">
- <xsl:variable name="tableName" select="."></xsl:variable>
- <xs:element>
- <xsl:attribute name="name"><xsl:value-of select="$tableName"></xsl:value></xsl:attribute>
- <xs:complexType>
- <xs:sequence>
- <xsl:apply-templates select="//columns//COLUMN_NAME[preceding-sibling::TABLE_NAME=$tableName]"></xsl:apply>
- </xs:sequence>
- </xs:complexType>
- <xsl:apply-templates select="//primarykeys//pk_name[preceding-sibling::table_name=$tableName]"></xsl:apply>
- <xsl:apply-templates select="//importedkeys//FK_NAME[preceding-sibling::FKTABLE_NAME=$tableName]"></xsl:apply>
- </xs:element>
- </xsl:template>
-
- <xsl:template match="COLUMN_NAME">
- <xsl:variable name="columnName" select="."></xsl:variable>
- <xsl:variable name="datatype" select="$columnName/following-sibling::DATA_TYPE"></xsl:variable>
- <xs:element>
- <xsl:attribute name="name"><xsl:value-of select="$columnName"></xsl:value></xsl:attribute>
- <xsl:choose>
- <xsl:when test="$datatype='Varchar'">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="{$datatype/following-sibling::COLUMN_SIZE}"></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xsl:when>
- <xsl:otherwise>
- <xsl:attribute name="type">
- <xsl:choose>
- <xsl:when test="$datatype='BigInt'">xs:long</xsl:when>
- <xsl:when test="$datatype='Boolean'">xs:boolean</xsl:when>
- <xsl:when test="$datatype='Date'">xs:date</xsl:when>
- <xsl:when test="$datatype='Timestamp'">xs:dateTime</xsl:when>
- <xsl:when test="$datatype='Double'">xs:double</xsl:when>
- <xsl:when test="$datatype='Float'">xs:float</xsl:when>
- <xsl:when test="$datatype='Integer'">xs:int</xsl:when>
- <xsl:when test="$datatype='Time'">xs:time</xsl:when>
- <xsl:when test="$datatype='TinyInt'">xs:short</xsl:when>
- <xsl:otherwise>xs:any</xsl:otherwise>
- </xsl:choose>
- </xsl:attribute>
- </xsl:otherwise>
- </xsl:choose>
- </xs:element>
- </xsl:template>
-
- <xsl:template match="pk_name">
- <xsl:variable name="primaryKey" select="."></xsl:variable>
- <xs:key>
- <xsl:attribute name="name"><xsl:value-of select="$primaryKey"></xsl:value></xsl:attribute>
- <xs:selector>
- <xsl:attribute name="xpath">.</xsl:attribute>
- </xs:selector>
- <xs:field>
- <xsl:attribute name="xpath">
- <xsl:value-of select="$primaryKey/preceding-sibling::column_name"></xsl:value>
- </xsl:attribute>
- </xs:field>
- </xs:key>
- </xsl:template>
-
- <xsl:template match="FK_NAME">
- <xsl:variable name="foreignKey" select="."></xsl:variable>
- <xs:keyref>
- <xsl:attribute name="name">
- <xsl:value-of select="$foreignKey"></xsl:value>
- </xsl:attribute>
- <xsl:attribute name="refer">
- <xsl:value-of select="$foreignKey/following-sibling::PK_NAME"></xsl:value>
- </xsl:attribute>
- <xs:selector>
- <xsl:attribute name="xpath">.</xsl:attribute>
- </xs:selector>
- <xs:field>
- <xsl:attribute name="xpath">
- <xsl:value-of select="$foreignKey/preceding-sibling::FKCOLUMN_NAME"></xsl:value>
- </xsl:attribute>
- </xs:field>
- </xs:keyref>
- </xsl:template>
- </xsl:stylesheet>
The stylesheet goes top-down through the XML document, first getting table structures (elements with the name TABLE_NAME) and then getting each of their columns (COLUMN_NAME elements), datatypes (converted from their SQL types into corresponding XML Schema simple types), primary keys (pk_name elements) and any foreign keys (FK_NAME elements) the table may have.
The primary keys are represented (and enforced) within XML Schema language by <xs:key> elements. These elements define a name attribute (representing the name of the key) and have <xs:selector> and <xs:field> child elements, each having xpath attributes.
- The
<xs:key>element requires that its<xs:field>child be unique within the document and must not benil(i.e., it cannot be empty). - The
<xs:selector>element indicates the context node for which the key is defined. This behavior matches that of primary keys in a database.
Foreign keys in XML Schema (defined in <xs:keyref> elements) have a structure almost identical to their primary key counterparts (<xs:key> elements); all <xs:keyref> elements define the same attributes and child elements as the <xs:key> elements and additionally define an attribute named refer.
Like the <xs:key> elements, an <xs:keyref> element requires that it's <xs:field> element not be empty; however the value of the <xs:field> element must match exactly the value of the <xs:field> element defined for the <xs:key> element whose name is referred to in the <xs:keyref> refer attribute.
These structures enforce referential integrity between <xs:key> and <xs:keyref> elements much like databases do between primary and foreign keys.
The following is the XML Schema that is the final product of the XSL Stylesheet transformation:
- <?xml version="1.0" encoding="UTF-8"?>
- <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
- <xs:element name="boat_class">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="classid" type="xs:int" ></xs:element>
- <xs:element name="class">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- <xs:element name="phrf" type="xs:int" ></xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="boat_class_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="classid" ></xs:field>
- </xs:key>
- </xs:element>
- <xs:element name="boats">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="boatid" type="xs:int" ></xs:element>
- <xs:element name="skipper" type="xs:int" ></xs:element>
- <xs:element name="class" type="xs:int" ></xs:element>
- <xs:element name="sailnumber" type="xs:int" ></xs:element>
- <xs:element name="boatname">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="boats_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="boatid" ></xs:field>
- </xs:key>
- <xs:keyref name="boats_class_fk" refer="boat_class_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="class" ></xs:field>
- </xs:keyref>
- <xs:keyref name="boats_skipper_fk" refer="skipper_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="skipper" ></xs:field>
- </xs:keyref>
- </xs:element>
- <xs:element name="race_days">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="racedayid" type="xs:int" ></xs:element>
- <xs:element name="raceday" type="xs:date" ></xs:element>
- <xs:element name="racename">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="race_days_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="racedayid" ></xs:field>
- </xs:key>
- </xs:element>
- <xs:element name="race_number">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="racenumberid" type="xs:int" ></xs:element>
- <xs:element name="racedayid" type="xs:int" ></xs:element>
- <xs:element name="racenumber" type="xs:int" ></xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="race_number_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="racenumberid" ></xs:field>
- </xs:key>
- <xs:keyref name="race_number_racedayid_fk" refer="race_days_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="racedayid" ></xs:field>
- </xs:keyref>
- </xs:element>
- <xs:element name="race_results">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="raceresultid" type="xs:int" ></xs:element>
- <xs:element name="racenumberid" type="xs:int" ></xs:element>
- <xs:element name="boatid" type="xs:int" ></xs:element>
- <xs:element name="skipperid" type="xs:int" ></xs:element>
- <xs:element name="starttime">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- <xs:element name="endtime">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- <xs:element name="adjustedtime">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="race_results_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="raceresultid" ></xs:field>
- </xs:key>
- <xs:keyref name="race_results_boatid_fk" refer="boats_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="boatid" ></xs:field>
- </xs:keyref>
- <xs:keyref name="race_results_racenumberid_fk" refer="race_number_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="racenumberid" ></xs:field>
- </xs:keyref>
- <xs:keyref name="race_results_skipperid_fk" refer="skipper_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="skipperid" ></xs:field>
- </xs:keyref>
- </xs:element>
- <xs:element name="skipper">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="skipperid" type="xs:int" ></xs:element>
- <xs:element name="skippername">
- <xs:simpleType>
- <xs:restriction base="xs:string">
- <xs:maxLength value="64" ></xs:maxLength>
- </xs:restriction>
- </xs:simpleType>
- </xs:element>
- </xs:sequence>
- </xs:complexType>
- <xs:key name="skipper_pk">
- <xs:selector xpath="." ></xs:selector>
- <xs:field xpath="skipperid" ></xs:field>
- </xs:key>
- </xs:element>
- </xs:schema>
Summary
This article has shown how two of the metadata interfaces provided by Java's JDBC API can be used to convert ResultSets into XML instance documents and XML Schemas that match the structure and relationships expressed in a database. This is a very powerful capability because it highlights how easy it can be to transform data from one format into another. One common use of XML as a systems integration technology is the exchange of XML documents containing data that two applications are meant to share. Using the methods described above, it is possible to create not only XML documents from simple queries to a database, but also an XML Schema capable of validating both the structure and the format of the data described in the XML document. It should therefore be possible to replicate a database from one system to another, including the creation of database schema SQL files (which are just text files) reverse-engineered from the XML Schemas that describe them.
Resources
The source code for this article can be found here.
References
The following are links to sites that offer related or supplementary information based on the topic of this article.
- [1] JDBC Data Access API
http://java.sun.com/products/jdbc/ - [2] Extensible Stylesheet Language (XSL)
http://www.w3.org/Style/XSL/ - [3] XML Schema
http://www.w3.org/XML/Schema
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
