January 15, 2003 - By Steve Totten, OCI Partner and Principal Software Engineer
Middleware News Brief (MNB) features news and technical information about Open Source middleware technologies.
INTRODUCTION
CORBA is used in a wide variety of application domains, including aerospace and defense, banking and finance, telecommunications, manufacturing, healthcare, and even multimedia and entertainment [http://www.corba.org/success.htm]. CORBA's inherent benefits, such as location transparency, platform portability, network transparency, and language independence are important factors in its wide-ranging success.
Unfortunately, traditional CORBA-based middleware often cannot meet the demanding quality of service (QoS) needs of certain specialized applications. Many applications require the middleware on which they are built to be predictable and reliable. Traditional CORBA, which provides only "best effort" semantics, is not sufficient for the QoS needs of such applications. In many applications, a "correct" answer, if delivered too late, is considered a failure. Likewise, such systems must continue to function even in the presence of faults.
Two relatively recent OMG specifications that address many of the QoS needs of such applications include Real-time (RT) CORBA and Fault Tolerant (FT) CORBA.
RT CORBA [formal/02-08-02] defines standard interfaces and QoS policies that allow applications to configure and control processor resources, communication resources, and memory resources.
FT CORBA [formal/02-12-02, Chapter 23] defines interfaces, QoS policies, and services to enhance the reliability of CORBA applications.
The October 2002 Middleware News Brief described the RT CORBA specification. In this article, we introduce Fault Tolerant CORBA and describe the architecture set forth in the FT CORBA specification.
Future articles on FT CORBA will introduce the feature objectives for the initial FT CORBA release of The ACE ORB (TAO) and report on progress as these features are implemented.
GOALS OF FT CORBA
The FT CORBA specification defines an architecture, a set of services, and associated fault tolerance mechanisms that constitute a framework for resilient, highly-available, distributed software systems. Through application of this framework, applications can attain a degree of reliability beyond what can be achieved through traditional server redundancy.
FT CORBA is suitable for a wide range of applications, from large-scale business enterprise applications (such as billing, customer management, and financial asset management systems) to mid-scale applications (such as telecommunications and warehousing applications) to distributed, embedded, real-time applications (such as medical equipment control and monitoring systems).
Similar to other CORBA-based services and ORB features, FT CORBA defines mechanisms, including policies and properties, that application developers can use to adapt FT CORBA to their specific needs on a case-by-case basis.
FT CORBA is intended for use by applications that actively participate in achieving fault tolerance as well as applications that rely almost exclusively on FT CORBA's services and supporting features. Applications cannot, however, remain completely unaware. Applications must collaborate with FT CORBA by realizing certain interfaces in the following ways:
- By realizing interfaces used to monitor objects and detect faults
- By defining FT properties to be applied to CORBA objects
- By choosing operational styles that control distribution of responsibility between the application and FT CORBA
For many applications, the degree of reliability attained is directly related to the extent of the application's participation in achieving its FT goals.
In practice, many fault tolerant systems are deployed on fault tolerant infrastructures, including specialized operating systems, redundant or fault resilient communications systems, and fault tolerant processors.
A system's deployment environment is generally beyond the scope of FT CORBA, although it does discuss the relationship between FT CORBA and security domains and the use of gateways. Even so, FT CORBA is not a replacement for fault tolerant infrastructure. Rather, FT CORBA complements fault tolerant infrastructures by defining fault tolerant mechanisms for compliant ORBs and services that support the development and operation of fault tolerant software systems.
The FT CORBA specification does not attempt to meet all the availability and reliability requirements of the wide spectrum of today's CORBA-based applications. In particular, the specification does not define protocols required to achieve interoperability among different ORB implementations. The specification therefore recognizes that proprietary extensions may be needed to satisfy the needs of specific kinds of applications. Thus, the specification will likely evolve as developers gain experience through its implementation and application.
Moreover, the specification clearly states that extensions based upon experience gained via the implementation and use of FT CORBA's features in their present form may lead to greater interoperability and fault tolerance.
CHARACTERISTICS OF FT CORBA
FT CORBA is founded upon:
- Entity redundancy
- Fault detection
- And fault recovery
Entity Redundancy
Entity redundancy is achieved via replication of CORBA objects. A replicated object is implemented by a set of distinct CORBA objects called an object group, each of which realizes a common interface.
The members of an object group are referenced using an Interoperable Object Group Reference (IOGR). Clients remain unaware of a replicated object's nature and invoke operations on the object group as if it were a single CORBA object.
A replicated object's IOGR is:
- Created when the group is created
- Maintained as the group's membership changes over time
- Destroyed when the replicated object is deleted
An object group can be created and managed entirely by the FT CORBA infrastructure.
Fault Detection and Recovery
FT CORBA defines components to monitor replicated objects and report faults, such as a crashed replica, a crashed host, and so forth. Faults are reported to a notification service, which in turn distributes fault reports to participating FT CORBA components and other interested parties.
Mechanisms are also defined to support recovery of a FT application.
FT CORBA defines certain essential features that are inherent to the ORB itself. In this respect, a feature is considered inherent to the ORB if its operation is transparent to the application following configuration and/or initialization of the ORB.
Some features, for example, can be realized via portable interceptors, which requires installation of the interceptors and therefore may require participation by the application. However, an interceptor's operation is transparent after installation and so qualifies as inherent to the ORB.
FT CORBA services that support the creation and management of object groups, the detection of faults, and the distribution of fault reports – referred to collectively as the infrastructure – must themselves be inherently fault tolerant.
Other than an explicit requirement that these services cannot be dependent upon any external component or service that is not fault tolerant, the specification does not address mechanisms or techniques by which these services achieve the requisite fault tolerance; this is left to the ORB implementer. However, it seems clear that FT CORBA's infrastructure should also be characterized by redundancy, fault detection, and fault recovery.
FT CORBA FEATURES
This section summarizes FT CORBA's most prominent features:
- Object Replication. Discusses the replication of CORBA objects
- Replication Manager. Describes the component used to create and manage replicated objects
- Fault Detector and Fault Notifier. Summarizes the fault detection and reporting architecture and participating components.
OBJECT REPLICATION
A replicated object is realized as a group of CORBA objects, each having the same interface. Each member of an object group, referred to as a replica, has a unique IOR.
An IOGR is formed by aggregating the IORs of an object group's constituent replicas into a single reference.
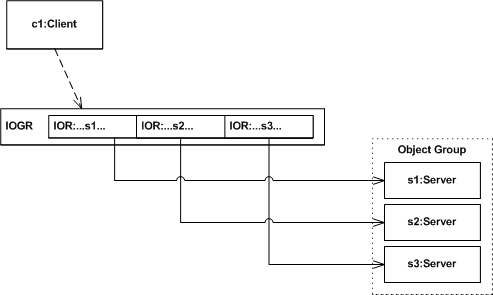
Figure 1. Object Group and IOGR
An object group's nature is transparent to its clients. A client obtains and uses an IOGR in the same manner as it would an IOR, so it remains unaware that the target object is, in fact, a replicated CORBA object.
The existence of multiple CORBA objects that can respond to a given request sets the stage for achieving fault tolerance through redundancy. In the event that one replica becomes faulty, another replica can assume the failed replica's responsibilities.
Of course, in addition to addressing the members of an object group transparently, mechanisms to keep an object group's members in a consistent state are also required. FT CORBA defines various replication styles that fall into essentially three categories:
- Stateless
- Passive
- Active
The differences between these styles are the points at which an object groups' members achieve a consistent state and the mechanisms used to achieve consistency.
Stateless Replication
The stateless replication style is suitable for CORBA objects that don't maintain context information between invocations. For such objects, each invocation either carries all information required to complete the request or sufficient information so that the requisite context can be derived or obtained from some external source. Stateless replicas remain consistent with one another since they have no persistent context. Thus, no mechanisms are required to keep the replicas consistent.
Passive Replication
The passive replication style is appropriate for objects that maintain at least some context information between invocations. An object group that employs a passive replication style designates a single replica as the primary and all other replicas as backups. All invocations are processed by the primary replica, and consistency between the primary replica and its backups is achieved via a checkpoint logging and recovery mechanism.
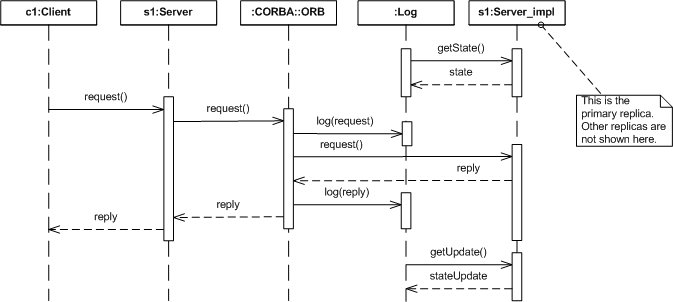
Figure 2. Passive Replication Style
When a client issues a request to a replicated object employing the passive replication style, the request is forwarded to the primary replica (the IOGR contains service context information that distinguishes the primary replica's IOR.). The ORB (in this diagram, the client and server ORBs are represented as a single object) logs the request and then invokes the target object. The target object processes the request and returns a reply. The server ORB then logs the reply and returns it to the client.
Periodically, the logging mechanism requests the primary's state (in the preceding diagram, this precedes the client's request), which is a complete representation of the primary's context. This information is added to the log.
The logging mechanism may also request periodic state updates (in the preceding diagram, this occurs after the client's request has been processed), a partial representation of the primary's context, to add to the log. If the primary replica becomes faulty, one of the backup replicas is designated as primary and information from the log is used to bring the new primary to the appropriate state.
Active Replication
The active replication style is also appropriate for objects that maintain context information between invocations. An object group that employs an active replication style doesn't distinguish between primary and backup replicas. All requests are processed by all replicas.
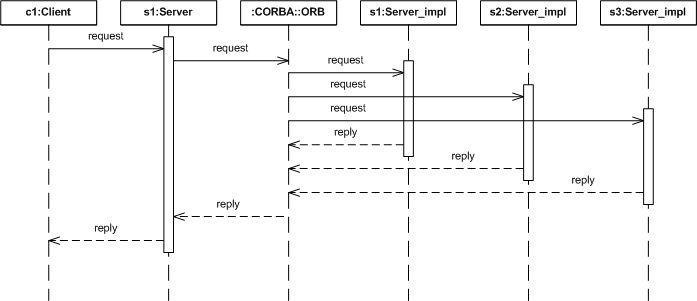
Figure 3. Active Replication Style
In an active replication style, the object group's replicas remain in a consistent state because each replica processes each request. The ORB suppresses duplicate replies so that the client receives only a single reply to its request.
The specification contains some guidelines that suggest which replication style is most appropriate for a particular application. A discussion of application characteristics and the tradeoffs when choosing a replication style is beyond the scope of this article.
An FT CORBA compliant ORB must provide some basic fault-tolerance mechanisms to enable:
- Construction, parsing, and manipulation of IOGRs
- Automatic and transparent reinvocation of failed requests.
- Detection and handling of duplicate requests and replies that can occur due to the replication style or during a failure recovery.
- Detection and resolution of requests that were made with respect to an out-of-date IOGR.
- Construction, parsing, and manipulation of IOGRs
REPLICATION MANAGER
The replication manager is perhaps the most visible of FT CORBA's infrastructure components. Fault tolerant services interact with the replication manager to create object groups, manage an object group's properties, control an object group's membership, and so forth. The replication manager is also solely responsible for the creation and maintenance of IOGRs.
The replication manager's operations are defined by three separate interfaces:
- Property Manager. Defines operations for setting properties, such as replication style, at several levels: by group, by type, or by default.
- Object Group Manager. Defines operations to add and remove members of an object group, change the primary member of an object group (for passive replication styles only), specify or get the locations of object group members, and get the current object group reference and object group identifier.
- Generic Factory. Defines operations for creating and destroying objects. The replication manager's realization of these interfaces affects the creation and destruction of object groups. These operations are also realized by application-specific object factories to create and destroy replicas as object groups are created and maintained.
A fault tolerant service can allow the replication manager to populate and maintain an object group using properties and policies set by the application, or it can take a more active part. The following diagram depicts a service that has delegated responsibility to the replication manager.
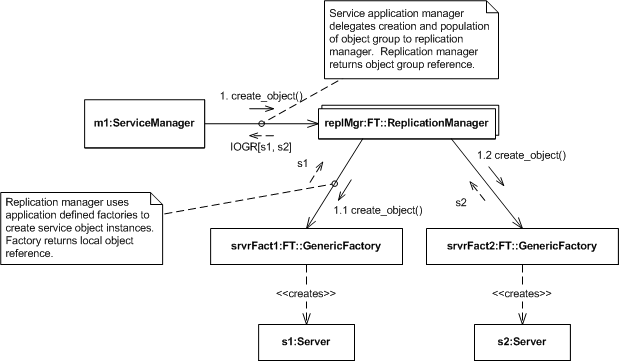
Figure 4. Infrastructure Controlled Object Group Creation
- The service manager, an application component that controls the fault-tolerant service's deployment, requests that the replication manager create an object group.
- Passed with the request are properties indicating the numbers and desired location of replicas, references to object factories that the replication manager will use when creating replicas, and so forth.
- In this example, these properties indicate that the FT CORBA infrastructure, i.e., the replication manager, should control the object group's membership.
- The replication manager invokes the local object factories specified by the application's request.
- The local factories create the desired objects and return object references to the replication manager.
- The replication manager constructs an IOGR containing the appropriate object references and returns it to the service manager.
In contrast, the following diagram depicts the service manager taking a more active part in creating an object group.
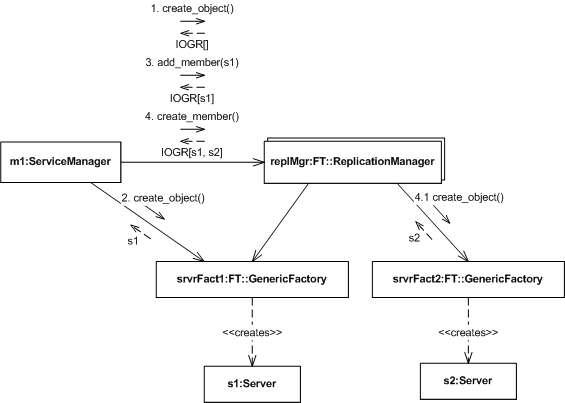
Figure 5. Application-Controlled Object Creation
- The application's service manager first requests that the replication manager create an object.
- In this case, the properties passed with the request indicate that the application will control the object group's membership.
- The replication manager establishes an object group without populating it and returns an empty IOGR.
- The service manager then invokes a local factory directly and instructs the replication manager to add the resulting replica to the object group.
- The replication manager updates the group's membership and returns the updated IOGR.
- Next, the service manager instructs the replication manager to create another member for the group.
- In response, the replication manager invokes the appropriate local factory, updates the group's membership, and again returns an updated IOGR.
FAULT DETECTOR AND FAULT NOTIFIER
FT CORBA's fault detection and notification architecture provides fault-tolerant systems with a range of deployment options. Simple fault tolerant systems can employ a basic two-tier structure while complex systems can employ multi-tier hierarchical arrangements.
The fault detector is the basic component for monitoring a fault-tolerant system's software components, processes, and processing nodes and reporting faults.
FT CORBA's fault notifier is based upon a subset of the COS Fault Notification Service [formal/02-08-04]. The fault notifier typically gathers faults from fault detectors. However, a fault notifier may also gather fault reports from application- or platform-specific fault detectors.
(At present, the FT CORBA specification defines a single monitoring style, the PULL monitoring style, in which a fault detector periodically issues a CORBA request to monitored objects and reports faults for those objects that fail to respond. The PUSH style, which is also common, depends upon application characteristics and so isn't supported.)
The following diagram depicts a fault notifier and a number of fault detectors employed in different roles.
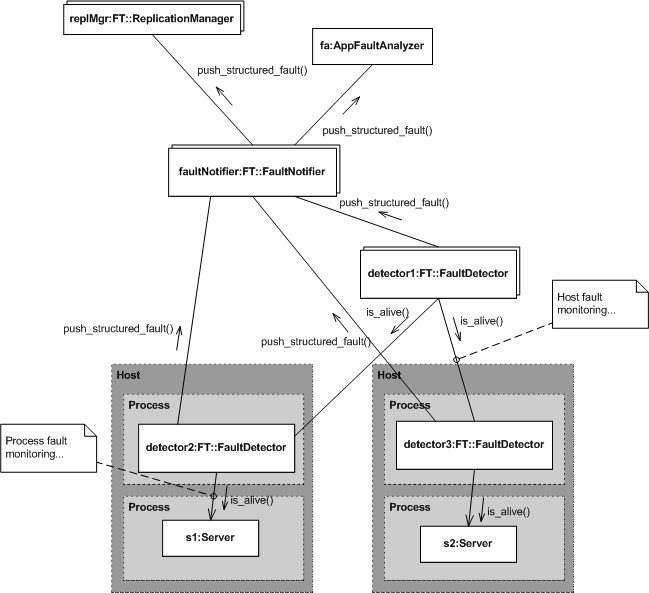
Figure 6. Fault Detection and Notification
A fault detector that's co-located on the same host as the object or objects it monitors, e.g., detector2 and detector3, is responsible for process-level fault detection. These fault detectors report a process fault when a monitored object fails to respond.
Host-level fault detection is the responsibility of fault detectors that monitor other fault detectors, e.g., detector1. A host fault is reported when a fault detector fails to respond.
Of course, a fault detector that monitors other fault detectors is not co-located with the objects it monitors. System-level faults are determined by an application specific fault analyzer, which acts as a push consumer of the fault notifier, based upon reported faults.
The fault notifier can support an arbitrary number of fault detectors and clients because it is based upon the COS Notification Service.
Fault detectors report faults by assuming the role of push supplier with respect to the fault notifier. This allows application-specific fault detectors to participate using a standardized interface.
Components interested in receiving fault reports assume the role of push consumer with respect to the fault notifier. This allows an application to provide its own fault-analysis capability, represented here by the fault analyzer
The replication manager acts upon reported faults, creating new replicas when needed, designating the primary replica for an object group employing a passive replication style, updating IOGRs, etc., when an object group's membership is controlled by the FT CORBA infrastructure.
The application must provide a specific fault analyzer when an object group's membership is controlled by the application. Moreover, an application should provide a fault analyzer to perform application-specific analysis of reported faults.
Fault analyzers may perform a variety of functions, including identifying and analyzing related faults to identify a common root cause, aggregating multiple faults into a single fault report, filtering selected faults under certain circumstances, and so forth.
The fault notifier filters faults for distribution to clients according to the various consumers' specifications. Consumers specify filtering constraints using the Extended Trader Constraint Language, which is part of the COS Notification Service.
DISTRIBUTION OF RESPONSIBILITY
Responsibility for realizing fault tolerance is distributed among the FT CORBA infrastructure and the application. This section describes what role the application plays in implementing fault tolerance and what role is played by the infrastructure.
APPLICATION'S ROLE
The application is required to provide concrete object factories that implement the Generic Factory interface. Instances of these factories are distributed across hosts on which application service objects will exist. The replication manager, and in some cases the application itself, uses these object factories to create members of an object group.
Monitored application objects are required to implement the PullMonitorable interface used by fault detectors to detect when a replica has failed. This simple interface has a single operation, is_alive, that the fault detectors use to periodically check that a replica is still responsive.
Applications may provide other forms of fault detection (e.g., process, network or host fault detectors) if desired and may integrate these with FT CORBA via the fault notifier.
Applications may also employ a fault analyzer, which can register with the fault notifier to receive fault notifications. As described above, an application-specific fault analyzer is important for application-controlled object groups and to provide sophisticated fault analysis.
The application is also responsible for setting policies to achieve the desired distribution of responsibility between the application and the FT CORBA infrastructure. For example, when creating an object group, the application sets properties to control the group's membership style and consistency style, each of which may be infrastructure-controlled or application-controlled.
FT CORBA'S ROLE
The FT CORBA infrastructure is responsible for invoking the concrete factories when appropriate, such as when creating replicas during the creation of an object group.
The infrastructure also must provide the replication manager service and make its object reference available to the application via the CORBA::ORB::resolve_initial_references operation with the ObjectId "ReplicationManager."
As described previously, the replication manager is responsible for implementing the Property Manager, Object Group Manager, and Generic Factory interfaces.
The FT CORBA infrastructure is required to provide reliable infrastructure components, which means components such as the replication manager, fault notifier, and fault detectors must themselves be replicated and monitored.
The infrastructure must support multi-level fault detection and reporting, and must allow applications to participate in fault detection, fault notification, and fault analysis by providing their own fault detectors and analyzers.
Finally, the infrastructure must provide other inherent fault tolerance mechanisms, such as transparent reinvocation, most recent object group reference, and checkpoint logging and recovery.
STATE OF FT CORBA
As stated previously, FT CORBA defines an architecture, services, and mechanisms for building CORBA applications with a degree of reliability beyond what can be achieved through traditional server redundancy. However, there are limitations with FT CORBA that must be considered when evaluating whether it is suitable for a given application.
- Legacy ORBs. Even clients implemented with a non-FT-CORBA ORB can invoke operations on an object group via an IOGR but will not realize the benefits of certain inherent fault-tolerance mechanisms, such as transparent reinvocation and most recent object group reference consistency checking.
- Deterministic behavior. To guarantee strong replica consistency, all replicas in an object group must be created and initialized to the same exact state, must process all requests in the same exact order, and must all arrive at exactly the same state upon completing each request. This requirement may impose limitations on what the application can do while processing each request. For example, if processing the request requires inputs from another source, these inputs must be exactly the same for every replica or some replicas might arrive at inconsistent results.
- Inability to handle certain types of faults. The FT CORBA specification does not address mechanisms to handle network partitioning faults (i.e., when the network is partitioned inadvertently such that objects on separate hosts cannot reach one another), commission faults (i.e., when an object produces incorrect results), and correlated faults (e.g., programming logic errors).
- Unpredictable failover and recovery. Real-time applications require predictable performance. Latencies introduced by FT CORBA's failover and recovery mechanisms may be unacceptable to such applications.
CURRENT RESEARCH
The Distributed Object Computing Group (DOC Group) is presently conducting research related to fault tolerant distributed systems with particular emphasis on fault-tolerant distributed real-time and embedded (DRE) systems. Two areas of research applicable to FT CORBA are reliable, multicast protocols and an alternative replication scheme.
Reliable multicast protocols, and especially totally-ordered reliable multicast protocols, may play a crucial supporting role in maintaining consistency among replicated objects. Passive replication styles depend upon a log of requests and replies, replica state snapshots, and replica state updates. This log can be housed on a fault tolerant, shared file system, in which case each replica must have direct access to that file system. The log can also be distributed such that each replica has a local copy of the log. Logging via a shared file is a simpler implementation problem but constrains scalability. A distributed log enhances scalability but may require a reliable multicast protocol to achieve.
The DOC Group has also been researching a new replication style, called SEMI_ACTIVE [CCJ-2002.pdf], which is a hybrid of the present passive and active replication styles.
- SEMI_ACTIVE replication is similar to the passive replication styles in that a single replica is designated as the primary and processes all client requests.
- It is similar to the active replication style in that all replicas achieve a consistent state at the end of each invocation.
Consistency is directed by the primary, and so SEMI_ACTIVE replication is supported only for application-controlled consistency.
An important advantage of SEMI_ACTIVE replication is that it offers a predictable fault recovery time and so makes it suitable for DRE systems. It also offers some additional fault detection capabilities because the members of an object group are organized such that each replica other than the primary is associated with and monitors one other replica. The replica associated with the primary assumes the primary role in the event the primary becomes faulty. Moreover, through its association with the primary, it can detect certain faults and automatically assume the role of primary.
A development project to extend The ACE ORB (TAO) to include FT CORBA features is presently being considered. This project, if undertaken, will continue the previous research into reliable multicast protocols and SEMI_ACTIVE replication. It will also make TAO a suitable platform for continuing research in the area of fault tolerant systems, including DRE systems, based upon a compliant CORBA ORB.
SUMMARY
To meet the wide ranging needs of applications across diverse domains, CORBA must provide applications with appropriate mechanisms, including policies, services, and inherent infrastructure capabilities, that can be used to promote predictability and reliability. In this article, we have seen how the Fault Tolerant CORBA specification provides applications with mechanisms that applications can use as a framework for building resilient, highly-available, distributed software systems.
We have described goals and characteristics of FT CORBA and the components of the FT CORBA architecture. We have seen how applications, as well as the FT CORBA infrastructure, must play a role in implementing fault tolerance. We have described the current state of FT CORBA, including its limitations. Finally, we have described current research in extending FT CORBA capabilities and have seen how TAO is being used as a platform for this research.
Watch for additional articles on FT CORBA as we introduce the feature objectives for the initial FT CORBA release of The ACE ORB (TAO) and report on progress as these features are implemented.
Acknowledgments
This article was co-written by Principal Software Engineer and Partner, Steve Totten, and Principal Software Engineer, Rob Martin.
REFERENCES
- [1] Aniruddha S. Gokhale, Balachandran Natarajan, Douglas C. Schmidt, and Joseph K. Cross, "Towards Dependable Real-time CORBA Middleware"
[CCJ-2002.pdf] - [2] Balachandran Natarajan, Aniruddha S. Gokhale, Shalini Yajnik, and Douglas C. Schmidt, "DOORS: Towards High-performance Fault Tolerant CORBA"
[DOA-2000.pdf] - [3] Object Management Group, CORBA/IIOP Specification version 3.0.2, formal/02-12-02
- [4] Object Management Group, Real-time CORBA Specification version 1.1, formal/02-08-02
- [5] Miguel Castro and Barbara Liskov, "Practical Byzantine Fault Tolerance"
[osdi99.html]
