
MPI and DDS (Not?) So Different
January 09, 2012 · By Charles Calkins, OCI Senior Software Engineer
Topics: MPI, DDS
INTRODUCTION
There are a number of frameworks, middleware, and libraries for distributed computing that have emerged since the 1990s. Two of these are Message Passing Interface (MPI) [1], and the Data Distribution Service (DDS) for Real-Time Systems [2]. On the surface, these have distinct, incompatible models of computation. An MPI computation consists of message passing between a fairly rigid set of processes each of which is identified by number, while DDS provides a decoupling between publishers and subscribers of structured data. Although these differences are fundamental, DDS quality of service policies and other features can help to bridge the gap.
MESSAGE PASSING INTERFACE (MPI)
As parallel processing systems developed in the 1980s and early 1990s, the need for a communications standard developed, as existing systems were proprietary, and methodologies and tools were incompatible. Beginning in 1992 [3], a series of meetings, discussions, and working groups were held, leading to the release of version 1.0 of the MPI-1 standard in June 1994. MPI-1 (now at revision 1.3) specifies a static collection of communicating processes, but MPI-2, released in 1998, allows for dynamic process creation as well as parallel I/O. While MPI-2, now at version 2.2 (released 2009), is the currently available standard as of this writing, MPI-3 is currently being drafted, and includes features such as persistence and fault-tolerance [4].
An MPI computation consists of a set of processes, each identified numerically by its rank. By default, a set of N processes is numbered 0 to N-1. It is common for the process of rank 0 to be considered differently than the other processes. For instance, it may be responsible for console I/O, or to act as the master, in a master/worker-style computation, where it distributes tasks to workers and collects completed results.
Two styles of communication are available. Both blocking and nonblocking point-to-point communication, from one process to another, is performed by the sender specifying the rank number of the process that is to receive the message. Collective communication, where messages are sent between a group of (or all) processes, are performed by functions which scatter or gather data to or from processes, as well as by providing data reduction and other operations. Message transmission over TCP is common, but various MPI implementations also provide support for special-purpose, high-speed networks, such as Myrinet [5] and InfiniBand [6]. Message delivery is assumed to be reliable, so no control over quality of service policies for messaging is necessary.
Process failure in MPI-2 is not handled gracefully — the default behavior is to abort all processes in the computation if one fails. Even if MPI is configured such that errors are not automatically fatal, after an error the state of the MPI system is undefined, and may be unusable [2, §8.3].
A typical use for MPI is to distribute a numerical computation across a series of compute nodes, where each node runs essentially the same computation on its own subset of data (SIMD data parallelism [7]). While algorithms can be written by hand, a number of numerical libraries, for computations such as linear algebra and the solving of partial differential equations, are already available that use MPI for parallelization [8].
DATA DISTRIBUTION SERVICE (DDS) FOR REAL-TIME SYSTEMS
Discussions between Real-Time Innovations and the Thales Group began in 2001 on a data distribution specification, version 1.0 of which was approved by the Object Management Group (OMG) in 2003. Version 1.2 (Jan 1, 2007) is the current standard and 1.3 is currently under development [9].
A DDS system consists of publishers and subscribers, within a communication boundary called a domain. A publisher, through the use of a data writer, sends a data sample of a given topic. A subscriber, via a data reader, receives the published topic. Data structures that represent topics consist of the same data types that are supported by the Common Object Request Broker Architecture (CORBA), another OMG standard.
Publishers and subscribers do not have direct knowledge of each other, although a publisher can know how many subscribers are currently subscribing to its published topic, and subscribers can know how many publishers are actively publishing to it.
All sample writes are essentially broadcasted — data samples are sent to all subscribers that are associated with the publisher that publishes the sample. Quality of service policies are available which can tailor the communication, however, such as to establish criteria for the rate of publication or reception, filter samples to be received, and to make already-published samples available to late-joining subscribers. While DDS supports different network types for data transmission, certain quality of service policies are only available for particular transports. For instance, guaranteed delivery, by setting the Reliability quality of service policy to RELIABLE, is not applicable unless the underlying transport itself provides guaranteed reliability.
Failure is handled gracefully — publishers and subscribers can dynamically come and go during system execution.
Typical uses of DDS are to stream data from data sources such as physical sensors, or stock market data feeds, where the DDS topic consists of, say, a sensor ID and its reading, or a stock ticker name and its price. DDS is also used for event processing, such as to signal when trading has been opened in a stock exchange.
MPI COMMUNICATION
While MPI and DDS are different in organization and purpose, a system based on DDS can be created that provides similar behavior to one based on MPI. In order to develop such a system, we first must look at a few properties of MPI in detail. For a complete discussion of MPI, please consult one of the many on-line references such as [10], [11] or [12], or books including [13] and [14].
OUT OF ORDER MESSAGES
Point-to-point communication in MPI is performed through the functions MPI_Send() and MPI_Recv(), and their non-blocking equivalents, MPI_Isend() and MPI_Irecv(). As point-to-point messages may arrive at a given MPI process in an arbitrary order, especially when multiple senders are sending to a particular receiver, MPI provides a means of selecting which particular message to accept at any given time. A message sent with MPI_Send() includes an integral tag value which can be used to categorize the message type. For instance, two messages may be sent, where the first message is the length of the array that will be sent in the second message. The recipient must accept the array length message before the array itself. The recipient calls MPI_Recv() once with the same tag as the array length message, and MPI_Recv() again, but with the tag of the array message, after a buffer of a suitable size, based on the array length, has been allocated. If message order is not important, the constant MPI_ANY_TAG can be used to accept any message. Similarly, a recipient may wish to accept a message from a particular sender. The rank of the sender can also be provided to MPI_Recv(), or the constant MPI_ANY_SOURCE used to allow messages from any sender to be accepted.
This can be demonstrated with the following two examples.
Example 1
In the first case, a message with tag 19 is sent from the process with rank 0 to the process with rank 1, followed by a message with tag 99, also to the process with rank 1. The process with rank 1 accepts the message with tag 99 first and echoes it back to the process with rank 0, and then accepts the message with tag 19, and echoes it back to the process with rank 0.
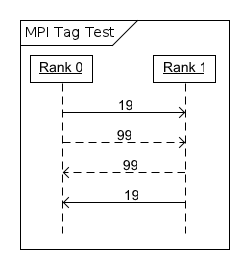
Figure 1. Example 1, Tag Test
The implementation for this example is as follows. These examples, available in the code archive associated with this article, have been tested with OpenMPI 1.5.4 [15].
First, a call to MPI_Init() must be made as the first MPI function executed in order to initialize the MPI process.
// MPITag/MPITag.cpp
#include <mpi.h>
#include <iostream>
int main(int argc, char *argv[]) {
int size, rank;
MPI_Init(&argc, &argv);Next, it is typical for a process to determine its current rank out of the total number of processes in order to execute rank-based behavior. MPI_COMM_WORLD is a communicator that represents all processes in the system, and will be described later in the article.
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);We now can send and receive messages. The process with rank 0 sends a single integer to the process with rank 1, with a message that has tag 19. It then sends a similiar message, but with tag 99. It then waits to receive two messages from the process with rank 1, first with tag 99 and then with tag 19.
MPI_Status status;
int i=0;
if (rank == 0) {
// send 19 first, then 99
std::cout << "send 19" << std::endl;
MPI_Send(&i, 1, MPI_INT, 1, 19, MPI_COMM_WORLD);
std::cout << "send 99" << std::endl;
MPI_Send(&i, 1, MPI_INT, 1, 99, MPI_COMM_WORLD);
MPI_Recv(&i, 1, MPI_INT, 1, 99, MPI_COMM_WORLD, &status);
std::cout << "receive 99" << std::endl;
MPI_Recv(&i, 1, MPI_INT, 1, 19, MPI_COMM_WORLD, &status);
std::cout << "receive 19" << std::endl;
}As all processes run the same code, an if statement is used to determine which process is which, by rank. Here, the process with rank 1 waits for a message from the process with rank 0 that has tag 99, and echoes it back. It then waits for one with tag 19, and then echoes it back as well.
else if (rank == 1) {
MPI_Recv(&i, 1, MPI_INT, 0, 99, MPI_COMM_WORLD, &status);
MPI_Send(&i, 1, MPI_INT, 0, 99, MPI_COMM_WORLD);
MPI_Recv(&i, 1, MPI_INT, 0, 19, MPI_COMM_WORLD, &status);
MPI_Send(&i, 1, MPI_INT, 0, 19, MPI_COMM_WORLD);
}Finally, MPI_Finalize() is called to clean up MPI resources before the process exits.
MPI_Finalize();
return 0;
}Example 2
The second case of selecting messages by sender can be demonstrated with this arrangement of processes.
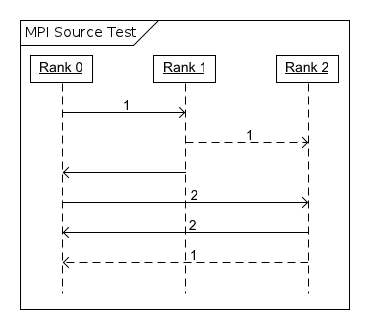
Figure 2. Example 2, Source
The process with rank 0 sends the value 1 to the process with rank 1, waits for a reply, sends the value 2 to the process with rank 2, and then waits for two replies from that process. The process with rank 1 acts as an intermediary, sending the value 1 to both the process with rank 2 and rank 0. This ensures that the process with rank 2 will receive the value 1, before the process with rank 0 is signaled to send the value 2 to the process with rank 2. The process with rank 2 then accepts two messages, first from the process with rank 0 (and sends its value to the process with rank 0), and from the process with rank 1, (and sends its value to the process with rank 0). The process with rank 0 receives the value 2, and then the value 1, from the process with rank 2, demonstrating that the messages were accepted in the opposite order that they were sent.
COLLECTIVE COMMUNICATION
In addition to sending a message to a process with a specific rank, collective communication is also available. MPI_Bcast() will send a message to all processes, while methods such as MPI_Scatter(), MPI_Gather() and MPI_Reduce() provide for a more abstract means for sending and receive data from processes.
Unlike point-to-point communication, all processes must be executing the same collective communication operation — there is no chance for out-of-order messages to be received. For example, the following code shows a message broadcast:
// MPIBroadcast/MPIBroadcast.cpp
#include <mpi.h>
#include <iostream>
int main(int argc, char *argv[]) {
int rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int i=0;
if (rank == 0) i=42;
MPI_Bcast(&i, 1, MPI_INT, 0, MPI_COMM_WORLD);
// i is now 42 in all processes
MPI_Finalize();
return 0;
}Here, the value of the variable in the process with rank 0 (as specified by the parameter 0 in the call to MPI_Bcast()) is sent to all other processes. The other collective communication functions either work this way, where a root process that acts as the source of data is specified, or where no root is needed as data is sent to or from all processes.
COMMUNICATION AND PROCESS TOPOLOGY
In addition to communicating with individual processes in a point-to-point manner, and to all processes in a collective manner, MPI is also able to define groups of processes, as well as a more structured way to address them.
Up to this point, the MPI_COMM_WORLD communicator has been used. A communicator represents a collection of processes that can communicate, and MPI_COMM_WORLD is predefined by the system to represent all processes in the current computation. If the computation is composed of N processes, processes are numbered sequentially from 0 to N-1.
Through the MPI_Group_*() and MPI_Comm_*() function families, custom groups and communicators can be built. For instance, a communicator representing processes that calculate a single row of a matrix could be created, and a broadcast over that communicator would broadcast to only that set of processes.
As many mathematical problems are solved over a rectangular array, MPI provides the MPI_Cart_create() function to create a communicator using all of the processes in MPI_COMM_WORLD arranged in an N-dimensional grid. The function MPI_Cart_rank() is used to find the rank of a process that corresponds to a given grid vertex.

While the exact mapping of processors to rank numbers is determined by MPI, the diagram above shows a potential assignment. In this arrangement, a process at grid position (i,j) corresponds to the process with rank j*W+i, where W is sqrt(N) for N processes. Here, a given grid position has 8 neighboring points at positions (i±1, j±1), but, by considering a more restricted assignment of neighbors, the same mapping can also be used for a hexagonal grid, as shown below.
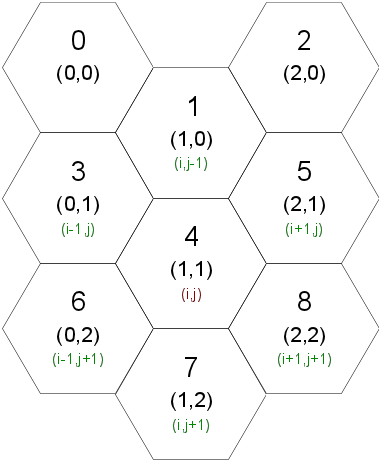
Figure 4. Hex
DDS AS MPI
As we have seen, in order to use DDS in a manner similar to that of MPI, we must support both point-to-point and collective communication, and be able to create subsets (groups) of processes that can be addressed in specific ways. This is possible by the use of DDS quality of service policies and other features, as will be shown below.
To illustrate DDS communication as MPI, consider a ring of N processes, numbered 0 to N-1. For each process p:
- p = 0: Send the value 1 to the process with rank 1, and wait for the value from the process with rank N-1.
- p ≠ 0: Wait for a value from the process with rank p-1, add 1 to it, and send the new value to the process with rank ((p+1) mod N).
When complete, process 0 will receive a value equal to N. For N=5, this can be shown in the following diagram:
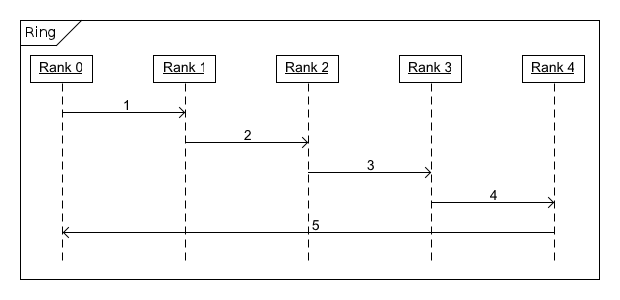
Figure 5. Ring Diagram
Using MPI, the implementation is as follows:
// MPIRing/MPIRing.cpp
#include <mpi.h>
#include <assert.h>
int main(int argc, char *argv[]) {
int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Status status;
if (rank == 0) {
int i = 1, j = 0; // initially 1 for the master
MPI_Send(&i, 1, MPI_INT, 1, 99, MPI_COMM_WORLD);
MPI_Recv(&j, 1, MPI_INT, size-1, 99, MPI_COMM_WORLD, &status);
assert(j == size);
}
else {
int i = 0;
MPI_Recv(&i, 1, MPI_INT, rank-1, 99, MPI_COMM_WORLD, &status);
i++; // +1 for the worker
MPI_Send(&i, 1, MPI_INT, (rank+1)%size, 99,
MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}As we wish to compare performance, we augment the example with two command-line parameters: -i to indicate the number of trips around the ring, and -n to specify the number of integers to send in each message. As with the original example, only the first integer of the array is meaningful, but varying the array length allows varying message sizes also be profiled. Finally, ACE is used to provide a timing measurement for the total time that messages are sent around the ring.
ACE is also used to parse the command line for -i and -n.
// MPIRingTest/MPIRingTest.cpp
#include <mpi.h>
#include <assert.h>
#include <iostream>
#include <vector>
#include <ace/Arg_Shifter.h>
#include <ace/Profile_Timer.h>
bool GetArg(int &argc, ACE_TCHAR *argv[], const ACE_TCHAR *arg,
int &value) {
bool foundArg = false;
ACE_Arg_Shifter arg_shifter(argc, argv);
while (arg_shifter.is_anything_left()) {
const ACE_TCHAR *currentArg = 0;
if ((currentArg = arg_shifter.get_the_parameter(arg)) != 0) {
value = ACE_OS::atoi(currentArg);
arg_shifter.consume_arg();
foundArg = true;
}
else
arg_shifter.ignore_arg();
}
return foundArg;
}The augmented ring test is as follows:
int main(int argc, char *argv[]) {
int numIterations = 1, numIntegers = 1;
GetArg(argc, argv, ACE_TEXT("-i"), numIterations);
GetArg(argc, argv, ACE_TEXT("-n"), numIntegers);
int size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
std::vector<int> buffer;
buffer.resize(numIntegers);
MPI_Status status;
if (rank==0) {
ACE_Profile_Timer timer;
timer.start();
for (int iter = 0; iter < numIterations; iter++) {
buffer[0] = 1; // initially 1 for the master
MPI_Send(&buffer[0], numIntegers, MPI_INT, 1, 99,
MPI_COMM_WORLD);
MPI_Recv(&buffer[0], numIntegers, MPI_INT, size-1, 99,
MPI_COMM_WORLD, &status);
assert(buffer[0] == size);
}
timer.stop();
ACE_Profile_Timer::ACE_Elapsed_Time et;
timer.elapsed_time(et);
std::cout << "Total elapsed time for " << numIterations <<
" iteration(s) and " << numIntegers << " integer(s): " <<
et.real_time << "s, time per iteration: " <<
((et.real_time / double (numIterations)) * 1000000) <<
"us" << std::endl;
}
else {
for (int iter = 0; iter < numIterations; iter++) {
MPI_Recv(&buffer[0], numIntegers, MPI_INT, rank-1, 99,
MPI_COMM_WORLD, &status);
buffer[0]++; // +1 for the worker
MPI_Send(&buffer[0], numIntegers, MPI_INT,
(rank+1)%size, 99, MPI_COMM_WORLD);
}
}
MPI_Finalize();
return 0;
}We wish to create a similar test using DDS. We will use OCI's open-source implementation of DDS, OpenDDS [16]. To recap, we must implement the following features:
- Initialization and cleanup, to mirror
MPI_Init()andMPI_Finalize(). - Processes identified by a numeric identifier (rank).
- Point-to-point communication to a specific process identified by rank, accepting messages by specific source or tag as they may have arrived out of order, to emulate
MPI_Send()andMPI_Recv(). - Collective communication to all processes, or to a subset of processes based on topology, for
MPI_Bcast()and related functions.
Assigning a rank to a process is straightforward by passing it on the command line — a script can start the processes analogous to the manner in which mpirun does to start an MPI computation. We will demonstrate three different ways to accomplish the remaining items above, using various capabilities of DDS: content-filtered topics, the PARTITION quality of service policy, and the use of query conditions and instances.
MPI allows a buffer of data to be sent from a sender to a recipient, identified with a numeric tag value. For the first two examples, content-filtered topics and use of PARTITION, we will define a DDS sample structure, MessageByRank, where DDS instances are defined based on the rank of the message recipient. We also provide the sender's rank and message tag (both of type long) and the message data itself, of type sequence.
// DDSMPILib/MPIMessage.idl
module MPIMessage {
typedef sequence<octet> OctetSequence;
#pragma DCPS_DATA_TYPE "MPIMessage::MessageByRank"
#pragma DCPS_DATA_KEY "MPIMessage::MessageByRank recipientRank"
struct MessageByRank {
OctetSequence data;
long senderRank;
long recipientRank;
long tag;
};CONTENT-FILTERED TOPIC
Our first example implements MPI-like behavior in DDS by the use of a content-filtered topic (CFT). Code that is specific to this example will be placed in the class DDSMPI_CFT. Code common to the use of the MessageByRank structure will be placed in class DDSMPIBase_ByRank, which DDSMPI_CFT inherits from. Code common to all three examples will be placed in class DDSMPIBase, which DDSMPIBase_ByRank inherits from.
We first must initialize DDS, so we start by implementing Initialize(), as a parallel to MPI_Init(). To implement Initialize(), we first perform initialization that is required by both the CFT and PARTITION methods.
// DDSMPILib/DDSMPI_CFT.cpp
void DDSMPI_CFT::Initialize(int &argc, ACE_TCHAR *argv[]) {
BeginByRankInitialize(argc, argv);Common to both methods is the registering of the MessageByRank type, and creating a topic for it.
// DDSMPILib/DDSMPIBase_ByRank.cpp
void DDSMPIBase_ByRank::BeginByRankInitialize(int &argc,
ACE_TCHAR *argv[]) {
BaseInitialize(argc, argv);
MPIMessage::MessageByRankTypeSupport_var ts =
new MPIMessage::MessageByRankTypeSupportImpl;
if (ts->register_type(_dp, "") != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase_ByRank::BeginByRankInitialize(): reigster_type() failed");
CORBA::String_var type_name = ts->get_type_name();
_topic = _dp->create_topic("MPITopic", type_name, TOPIC_QOS_DEFAULT,
0, OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _topic)
throw DDSException(_rank,
"DDSMPIBase_ByRank::BeginByRankInitialize(): create_topic() failed");
}We also need to perform initialization common to all three methods —
Common to both methods is the determination of the rank of the current process, the total number of processes (_size), and the creation of the DDS domain participant.
// DDSMPILib/DDSMPIBase.cpp
void DDSMPIBase::BeginCommonInitialize(int &argc,
ACE_TCHAR *argv[]) {
// OBTAIN RANK AND SIZE
if (!GetArg(argc, argv, ACE_TEXT("-r"), _rank))
_rank = 0;
if (!GetArg(argc, argv, ACE_TEXT("-s"), _size))
_size = 1;
if (_rank>=_size)
throw DDSException("Rank must be less than size");
// CREATE THE DOMAIN PARTICIPANT AND TOPIC
_dp = _dpf->create_participant(42, PARTICIPANT_QOS_DEFAULT, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _dp)
throw DDSException(_rank,
"DDSMPIBase::BaseInitialize(): create_participant() failed");
}Continuing DDSMPI_CFT::Initialize(), we create the publisher and its associated data writer.
// CREATE THE PUBLISHER AND DATAWRITER
_pub = _dp->create_publisher(PUBLISHER_QOS_DEFAULT, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _pub)
throw DDSException(_rank,
"DDSMPI_CFT::Initialize(): create_publisher() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", _pub);
_mdw = MPIMessage::MessageByRankDataWriter::_narrow(
CreateDataWriter(_pub, _topic));
if (0 == _mdw)
throw DDSException(_rank,
"DDSMPI_CFT::Initialize(): writer _narrow() failed");A data writer is created with the default quality of service policy.
// DDSMPILib/DDSMPIBase.cpp
DDS::DataWriter_var DDSMPIBase::CreateDataWriter(
DDS::Publisher_ptr pub, DDS::Topic_ptr topic) {
DDS::DataWriterQos dw_qos;
pub->get_default_datawriter_qos(dw_qos);
DDS::DataWriter_var dw = pub->create_datawriter(topic, dw_qos,
0, OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == dw)
throw DDSException(_rank,
"DDSMPIBase::CreateDataWriter(): create_datawriter() failed");
return dw;
}Next, to improve performance, we store an instance handle corresponding to a sample sent to each recipient, plus one more that represents sending to all recipients (broadcast via the constant DDSMPI_BROADCAST, defined as -1).
// CREATE AN INSTANCE HANDLE FOR EACH RECIPIENT
MPIMessage::MessageByRank sample;
for (int i=0; i<=_size; i++) {
// _instances[_size] is broadcast
sample.recipientRank = (i==_size) ? DDSMPI_BROADCAST : i;
_instances.push_back(_mdw->register_instance(sample));
}Next, we create a subscriber, and a content-filtered topic for its data reader to subscribe to. The content-filtered topic is filtered based on the rank of the recipient — a given data reader subscribes only to data samples that match its own rank, or are sent to all recipients via a broadcast. Any process subset can also be specified in this manner — the filter can be crafted such that it includes only particular processes in a process group, so any communications topology can be supported.
// CREATE THE SUBSCRIBER
_sub = _dp->create_subscriber(SUBSCRIBER_QOS_DEFAULT, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _sub)
throw DDSException(_rank,
"DDSMPI_CFT::Initialize(): create_subscriber() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", _sub);
// CREATE THE CONTENT-FILTERED TOPIC
// FILTERED BY SUBSCRIBER RANK
std::ostringstream filter;
filter << "(recipientRank = " << _rank << ") OR (recipientRank = "
<< DDSMPI_BROADCAST << ")";
DDS::ContentFilteredTopic_var cft =
_dp->create_contentfilteredtopic("MPITopic-PerSubscriber",
_topic, filter.str().c_str(), DDS::StringSeq());
// CREATE THE DATAREADER
_mdr = MPIMessage::MessageByRankDataReader::_narrow(
CreateDataReader(_sub, cft));
if (0 == _mdr)
throw DDSException(_rank,
"DDSMPI_CFT::Initialize(): reader _narrow() failed");A data reader is created with the KEEP_ALL_HISTORY_QOS quality of service policy to ensure no data samples are lost.
// DDSMPILib/DDSMPIBase.cpp
DDS::DataReader_var DDSMPIBase::CreateDataReader(
DDS::Subscriber_ptr sub, DDS::TopicDescription_ptr topic) {
DDS::DataReaderQos dr_qos;
sub->get_default_datareader_qos(dr_qos);
dr_qos.history.kind = DDS::KEEP_ALL_HISTORY_QOS;
DDS::DataReader_var dr = sub->create_datareader(topic, dr_qos,
0, OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == dr)
throw DDSException(_rank,
"DDSMPIBase::CreateDataReader(): create_datareader() failed");
return dr;
}Since every process will execute Initialize(), every process has one data writer that publishes data samples, as well as one content-filtered data reader, to receive samples. This is shown, for three processes, in the diagram to the left — every data writer publishes to every data reader.
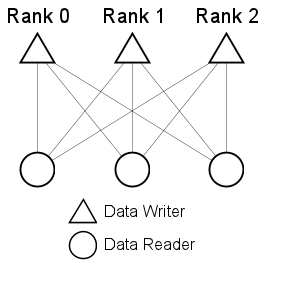
Figure 6. Rank
We conclude the implementation of DDSMPI_CFT::Initialize() by waiting until the given data writer is associated with the given number of subscribers, and then concluding the initialization process.
// WAIT FOR ASSOCIATIONS
WaitForPublicationCount(_mdw, _size);
EndByRankInitialize(_size); WaitForPublicationCount() blocks until the given data writer has been matched to the expected number of subscribers. For CFT, the data writer can publish to any other process, so the number of expected subscribers is equal to _size, the number of processes in the system. Blocking in this manner ensures that Initialize() does not terminate in the given process until all other processes are running and able to receive data.
// DDSMPILib/DDSMPIBase.cpp
void DDSMPIBase::WaitForPublicationCount(
::DDS::DataWriter_ptr mdw, int publicationCount) {
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
DDS::StatusCondition_var sc = mdw->get_statuscondition();
sc->set_enabled_statuses(DDS::PUBLICATION_MATCHED_STATUS);
DDS::WaitSet_var ws = new DDS::WaitSet;
ws->attach_condition(sc);
DDS::PublicationMatchedStatus status;
DDS::ConditionSeq active;
while (true) {
if (mdw->get_publication_matched_status(status) !=
DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase::WaitForPublicationCount(): get_publication_matched_status() failed");
if ((status.current_count == publicationCount))
break;
ws->wait(active, infinite);
}
ws->detach_condition(sc);
}Similarly, EndByRankInitialize() waits for an appropriate number of publishers for the given subscriber, and prepares a wait set to detect incoming data.
// DDSMPILib/DDSMPIBase_ByRank.cpp
void DDSMPIBase_ByRank::EndByRankInitialize(int subscriptionCount) {
WaitForSubscriptionCount(_mdr, subscriptionCount);
// CREATE A WAIT SET TO WAIT ON FOR ARRIVING SAMPLES
_dataAvailableStatus = _mdr->get_statuscondition();
_dataAvailableStatus->
set_enabled_statuses(DDS::DATA_AVAILABLE_STATUS);
_dataAvailable = new DDS::WaitSet;
_dataAvailable->attach_condition(_dataAvailableStatus);
}WaitForSubscriptionCount() does the opposite of WaitForPublicationCount() — given a data reader, it waits until the specified number of publishers are associated to publish to it.
// DDSMPILib/DDSMPIBase.cpp
void DDSMPIBase::WaitForSubscriptionCount(::DDS::DataReader_ptr mdr,
int subscriptionCount) {
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
DDS::ConditionSeq active;
DDS::StatusCondition_var sc = mdr->get_statuscondition();
sc->set_enabled_statuses(DDS::SUBSCRIPTION_MATCHED_STATUS);
DDS::WaitSet_var ws = new DDS::WaitSet;
ws->attach_condition(sc);
DDS::SubscriptionMatchedStatus sm_status;
while (true) {
if (mdr->get_subscription_matched_status(sm_status) !=
DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase::WaitForSubscriptionCount(): get_subscription_matched_status() failed");
if (sm_status.current_count == subscriptionCount)
break;
ws->wait(active, infinite);
}
ws->detach_condition(sc);
}With Initialize() complete, we can implement Send(). In comparison, Send() is almost trivial. The CFT version of Send() calls a common method to send a message using the data writer of the process.
// DDSMPILib/DDSMPI_CFT.cpp
void DDSMPI_CFT::Send(void *buf, int count, int dest, int tag) {
CommonByRankSend(_mdw, buf, count, dest, tag);
}The common send method copies the data to send into the sample buffer, sets the other message properties, and calls write() on the supplied data writer. An appropriate sample instance is passed to write() based on the destination process's rank, or if the message is a broadcast.
// DDSMPILib/DDSMPIBase_ByRank.cpp
void DDSMPIBase_ByRank::CommonByRankSend(
MPIMessage::MessageByRankDataWriter_ptr mdw, void *buf,
int count, int dest, int tag) {
MPIMessage::MessageByRank sample;
sample.senderRank = _rank;
sample.recipientRank = dest;
sample.tag = tag;
sample.data.length(count);
CORBA::Octet *ptr = (CORBA::Octet *)buf;
for (int i=0; i<count; i++)
sample.data[i] = ptr[i];
if (mdw->write(sample, _instances[(dest == DDSMPI_BROADCAST)
? _size : dest]) != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase_ByRank::CommonByRankSend(): mdw->write() failed");
}Recv() is identical between the CFT and PARTITION methods. It is somewhat complex as it must buffer messages if an incoming message does not match the desired source or tag criteria. Also, specifying a given source or tag is not required — MPI_ANY_SOURCE or MPI_ANY_TAG can be used as wildcards. A similar behavior is implemented here with the constants DDSMPI_ANY_SOURCE and DDSMPI_ANY_TAG.
First, Recv() checks to see if any waiting message matches the criteria for reception. If one is found, it is returned.
// DDSMPILib/DDSMPIBase_ByRank.cpp
void DDSMPIBase_ByRank::Recv(void *buf, int count, int source, int tag,
int &actualSource, int &actualTag) {
// source could be DDSMPI_ANY_SOURCE for a match
// tag could be DDSMPI_ANY_TAG for a match
CORBA::Octet *ptr = (CORBA::Octet *)buf;
// first, check if any pending messages match the criteria
// if so, remove and use
for (std::list<MPIMessage::MessageByRank>::iterator it =
_messages.begin(); it != _messages.end(); it++) {
if ( ((source == DDSMPI_ANY_SOURCE) ||
(source == it->senderRank)) &&
((tag == DDSMPI_ANY_TAG) || (tag == it->tag))) {
actualSource = it->senderRank;
actualTag = it->tag;
for (int i=0; i<count; i++)
ptr[i] = it->data[i];
_messages.erase(it);
return;
}
}If a message was not found, wait() on the dataAvailable WaitSet is called to block until a message arrives.
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
DDS::ConditionSeq conditions;
MPIMessage::MessageByRankSeq messageSeq;
DDS::SampleInfoSeq infoSeq;
while (true) {
// if no pending message matched, block waiting for a sample
conditions.length(0);
if (DDS::RETCODE_OK !=
_dataAvailable->wait(conditions, infinite))
throw DDSException(_rank,
"DDSMPIBase_ByRank::Recv(): _dataAvailable->wait() failed");When a message arrives, take() is called on the data reader, and, if valid, the message fields are compared to the desired criteria. If the message matches, it is returned, else it is queued, and the function loops and waits for another message to arrive.
// receive the sample
DDS::ReturnCode_t ret = _mdr->take(messageSeq, infoSeq, 1,
DDS::ANY_SAMPLE_STATE, DDS::ANY_VIEW_STATE,
DDS::ANY_INSTANCE_STATE);
if (ret != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase_ByRank::Recv(): _mdr->take() should have returned data");
if (!infoSeq[0].valid_data)
continue; // wasn't a valid data sample, so try again
// if the source and tag match, accept the message and exit
if ( ((source == DDSMPI_ANY_SOURCE) ||
(source == messageSeq[0].senderRank)) &&
((tag == DDSMPI_ANY_TAG) || (tag == messageSeq[0].tag))) {
actualSource = messageSeq[0].senderRank;
actualTag = messageSeq[0].tag;
for (int i=0; i<count; i++)
ptr[i] = messageSeq[0].data[i];
return;
}
// not a match, so queue it, and continue to wait
_messages.push_back(messageSeq[0]);
}
}The last function needed for CFT is Shutdown(), to terminate the system. We first wait until all messages have been acknowledged by their receivers, and then perform a shutdown process that is common to both the CFT and PARTITION methods.
// DDSMPILib/DDSMPI_CFT.cpp
void DDSMPI_CFT::Shutdown() {
// wait until all messages have been acknowledged
DDS::Duration_t fivesec = {5, 0};
_mdw->wait_for_acknowledgments(fivesec);
BeginByRankShutdown();The common shutdown destroys the data reader.
// DDSMPILib/DDSMPIBase_ByRank.cpp
void DDSMPIBase_ByRank::BeginByRankShutdown() {
// delete the datareader
if (_sub->delete_datareader(_mdr) != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPIBase_ByRank::BeginByRankShutdown(): _sub->delete_datareader() failed");
_mdr = 0;
}The implementation of DDSMPI_CFT::Shutdown() continues by waiting for all associations to be removed from the data writer. As each data reader is destroyed, the publication count is reduced — once all data readers are destroyed, then the publication count reaches 0. Each registered instance used for writing can then be unregistered, and then one last common function to complete the shutdown is called.
WaitForPublicationCount(_mdw, 0);
// delete the remaining entities and shut down
MPIMessage::MessageByRank sample;
for (int i=0; i<=_size; i++) {
sample.recipientRank = (i==_size) ? DDSMPI_BROADCAST : i;
_mdw->unregister_instance(sample, _instances[i]);
}
_instances.clear();
BaseShutdown();
}At this point, the computation is complete, and the DDS domain participant and any remaining DDS entities can be destroyed.
// DDSMPILib/DDSMPIBase.cpp
void DDSMPIBase::BaseShutdown() {
if (0 != _dp) {
_dp->delete_contained_entities();
_dpf->delete_participant(_dp);
_dp = 0;
}
}PARTITION
With the content-filtered method complete, we can now consider the PARTITION method. DDSMPI_Partition also inherits from DDSMPIBase_ByRank and shares the common code that it implements.
Once again, we begin with Initialize(). With CFT, we modified the data reader to filter what was received by it. In PARTITION, we create one publisher, and corresponding data writer, for each process in the system, plus an additional one to publish broadcast messages. Rather than using the default quality of service, the partition name of a pariticular publisher, as part of the PARTITION quality of service policy, is set to the rank of the process it will publish to, or to DDSMPI_BROADCAST (-1), as appropriate.
// DDSMPILib/DDSMPI_Partition.cpp
void DDSMPI_Partition::Initialize(int &argc, ACE_TCHAR *argv[]) {
BeginByRankInitialize(argc, argv);
// CREATE THE PUBLISHERS AND DATAWRITERS
DDS::StringSeq part;
DDS::PublisherQos pub_qos;
for (int i=0; i<=_size; i++) {
_dp->get_default_publisher_qos(pub_qos);
part.length(1);
std::ostringstream name;
name << ((i==_size) ? -1 : i);
part[0] = name.str().c_str();
pub_qos.partition.name = part;
DDS::Publisher_var pub = _dp->create_publisher(pub_qos, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == pub)
throw DDSException(_rank, "create_publisher() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", pub);
// array is _size+1 elements
// _pub[size] is the broadcast publisher
_pub.push_back(pub);
MPIMessage::MessageByRankDataWriter_var mdw =
MPIMessage::MessageByRankDataWriter::_narrow(
CreateDataWriter(pub, _topic));
if (0 == mdw)
throw DDSException(_rank, "writer _narrow() failed");
// array is _size+1 elements
// _mdw[size] is the broadcast writer
_mdw.push_back(mdw);
}As before, we register an instance for each process in the system. With CFT, only one data writer existed, so that one data writer was used for all instances. With PARTITION, the specific data writer that corresponds to the specific process (or broadcast) is used.
// CREATE AN INSTANCE HANDLE FOR EACH RECIPIENT
MPIMessage::MessageByRank sample;
for (int i=0; i<=_size; i++) {
// _instances[_size] is the broadcast instance
sample.recipientRank = (i==_size) ? DDSMPI_BROADCAST : i;
_instances.push_back(_mdw[i]->register_instance(sample));
}The subscriber also does not use the default quality of service, but a partition that consists of two names — its rank, and DDSMPI_BROADCAST (-1).
// CREATE THE SUBSCRIBER AND DATAREADER
DDS::SubscriberQos sub_qos;
_dp->get_default_subscriber_qos(sub_qos);
part.length(2);
std::ostringstream recipientRank;
recipientRank << _rank;
// receive samples for the particular rank of the subscriber
part[0] = recipientRank.str().c_str();
std::ostringstream broadcast;
broadcast << DDSMPI_BROADCAST;
// receive broadcast samples, too
part[1] = broadcast.str().c_str();
sub_qos.partition.name = part;
_sub = _dp->create_subscriber(sub_qos, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _sub)
throw DDSException(_rank, "create_subscriber() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", _sub);
_mdr = MPIMessage::MessageByRankDataReader::_narrow(
CreateDataReader(_sub, _topic));
if (0 == _mdr)
throw DDSException(_rank, "reader _narrow() failed");This partition assignment allows the data reader of the subscriber to associate with the following two types of publishers:
- The ones that publish to it by rank
- The ones that broadcast their samples to all processes in the system
This is shown in the diagram below. As we can change the filter with CFT, we can craft the partition names to represent any topology.

Figure 7. Partition
To complete Initialize(), we wait for the associations between the data readers and data writers to be made. From the perspective of the publishing process, each by-rank data writer has just one data reader — the process with the rank it is associated with, but the broadcast data writer associates with all data readers. From the perspective of the subscribing process, each data reader associates with two data writers from every process — its by-rank data writer, and the broadcast data writer.
// WAIT FOR ASSOCIATIONS
for (int i=0; i<=_size; i++)
// broadcast matches everyone, but rank matches just 1 subscriber
WaitForPublicationCount(_mdw[i], (i ==_size) ? _size : 1);
// every process has one publisher that matches the recipient rank
// and one for broadcast, so 2
EndByRankInitialize(2*_size);
}Send() is straightforward, although the specific data writer that corresponds to the destination must be used to send the data sample.
// DDSMPILib/DDSMPI_Partition.cpp
bool DDSMPI_Partition::Send(void *buf, int count, int dest, int tag) {
return CommonByRankSend(_mdw[(dest == DDSMPI_BROADCAST) ?
_size : dest], buf, count, dest, tag);
}Recv() is unchanged, and only Shutdown() is remaining to be implemented. It works as does Shutdown() in the CFT method, but processes each data writer individually.
// DDSMPILib/DDSMPI_Partition.cpp
void DDSMPI_Partition::Shutdown() {
// wait until all messages have been acknowledged
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
for (int i=0; i<=_size; i++)
_mdw[i]->wait_for_acknowledgments(infinite);
BeginByRankShutdown();
// wait until the datawriter has no publications
// (all other subscribers have deleted their datareader)
for (int i=0; i<=_size; i++)
WaitForPublicationCount(_mdw[i], 0);
// delete the remaining entities and shut down
MPIMessage::MessageByRank sample;
for (unsigned int i=0; i<_instances.size(); i++) {
sample.recipientRank = (i==_size) ? DDSMPI_BROADCAST : i;
_mdw[i]->unregister_instance(sample, _instances[i]);
}
_instances.clear();
BaseShutdown();
}This completes the implementation of the PARTITION method.
BY TAG
In this third method, we start with the same format for the DDS data sample, but we create instances based on the message tag field, instead of the recipient's rank.
// DDSMPILib/MPIMessage.idl
#pragma DCPS_DATA_TYPE "MPIMessage::MessageByTag"
#pragma DCPS_DATA_KEY "MPIMessage::MessageByTag tag"
struct MessageByTag {
OctetSequence data;
long senderRank;
long recipientRank;
long tag;
};DDSMPI_ByTag::Initialize() begins similarly to the other Initialize() methods by executing the common initialization and setting up the type and topic. Here, the topic is named MPI_COMM_WORLD, as communication topologies can be represented by different topics. Rather than the filtering as presented earlier, topics can be created which represent process collections. As only those publishers and subscribers that communicate using a given topic are associated, no runtime filtering is needed, speeding communication. For this example, we will still use just the one topic, however.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::Initialize(int &argc, ACE_TCHAR *argv[]) {
BaseInitialize(argc, argv);
// topic represents a communicator, so, for now,
// use one topic to represent MPI_COMM_WORLD
MPIMessage::MessageByTagTypeSupport_var ts =
new MPIMessage::MessageByTagTypeSupportImpl;
if (ts->register_type(_dp, "") != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): reigster_type() failed");
CORBA::String_var type_name = ts->get_type_name();
_topic = _dp->create_topic("MPI_COMM_WORLD", type_name,
TOPIC_QOS_DEFAULT, 0, OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _topic)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): create_topic() failed");We create one publisher with a PARTITION set to match the process rank, and its associated data writer.
// create one publisher with the partition set as its rank
DDS::StringSeq part;
DDS::PublisherQos pub_qos;
_dp->get_default_publisher_qos(pub_qos);
part.length(1);
std::ostringstream name;
name << _rank;
part[0] = name.str().c_str();
pub_qos.partition.name = part;
_pub = _dp->create_publisher(pub_qos, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == _pub)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): create_publisher() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", _pub);
_mdw = MPIMessage::MessageByTagDataWriter::_narrow(
CreateDataWriter(_pub, _topic));
if (0 == _mdw)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): writer _narrow() failed");In the CFT and PARTITION methods, we filtered on the recipient's rank. In this method, we create a PARTITION to filter on the sender's rank, and create a subscriber and data reader — that is, there is one subscriber and data reader in a given process corresponding to the publisher in every process. One additional subscriber is also created per process — one with a PARTITION that includes a wildcard to match any sender, allowing a message to be received from MPI_ANY_SOURCE.
DDS::SubscriberQos sub_qos;
for (int i=0; i<=_size; i++) {
_dp->get_default_subscriber_qos(sub_qos);
part.length(1);
std::ostringstream senderRank;
if (i==_size)
senderRank << "*";
else
senderRank << i;
// receive samples for the particular rank of the subscriber
part[0] = senderRank.str().c_str();
sub_qos.partition.name = part;
DDS::Subscriber_var sub = _dp->create_subscriber(sub_qos, 0,
OpenDDS::DCPS::DEFAULT_STATUS_MASK);
if (0 == sub)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): create_subscriber() failed");
OpenDDS::DCPS::TransportRegistry::instance()->
bind_config("c", sub);
_sub.push_back(sub);
MPIMessage::MessageByTagDataReader_var mdr =
MPIMessage::MessageByTagDataReader::_narrow(
CreateDataReader(sub, _topic));
if (0 == mdr)
throw DDSException(_rank,
"DDSMPI_ByTag::Initialize(): reader _narrow() failed");
// 0..size-1 is sender 0..size-1, size is any sender
_mdr.push_back(mdr);
// add an instance list for each reader
_readerInstances[i] = std::map<int, DDS::InstanceHandle_t>();
}As shown in the diagram below, this method is essentially the reverse of the CFT and PARTITION methods, with multiple subscribers, instead of multiple publishers, per process.
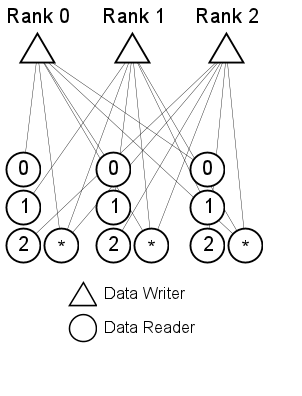
Figure 8. By Tag
DDSMPI_ByTag::Initialize() concludes by waiting for all associations to be established. Each data writer will match with two data readers per process — the one specific to it by rank number, and the one that matches all senders. Each data reader will match just the one publisher in each process, except for the wildcarded data reader that matches all senders.
// WAIT FOR ASSOCIATIONS
// matches both subscriber for the specific rank and
// "any sender", so 2 for each process
WaitForPublicationCount(_mdw, 2*_size);
for (int i=0; i<=_size; i++)
WaitForSubscriptionCount(_mdr[i], (i ==_size) ? _size : 1);
}DDSMPI_ByTag::Send() is similar to Send() in the other methods, but here, instance handles are used to improve performance when sending. Each writer contains a list of instance handles associtated with message tags. The first time a tag is encountered, a corresponding instance is registered for sending, and the handle saved for future use.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::Send(void *buf, int count, int dest, int tag) {
MPIMessage::MessageByTag sample;
sample.senderRank = _rank;
sample.recipientRank = dest;
sample.tag = tag;
sample.data.length(count);
CORBA::Octet *ptr = (CORBA::Octet *)buf;
for (int i=0; i<count; i++)
sample.data[i] = ptr[i];
DDS::InstanceHandle_t instance;
std::map<int, DDS::InstanceHandle_t>::iterator it =
_writerInstances.find(tag);
if (it != _writerInstances.end())
instance = it->second;
else {
MPIMessage::MessageByTag sample;
sample.tag = tag;
instance = _mdw->register_instance(sample);
_writerInstances[tag] = instance;
}
if (_mdw->write(sample, instance) != DDS::RETCODE_OK)
throw new DDSException(_rank,
"DDSMPI_ByTag::Send(): _mdw->write() failed");
}DDSMPI_ByTag::Recv(), while taking better advantage of DDS capabilities than DDSMPIBase_ByRank::Recv(), the entire receive process is actually more lines of code. Conceptually, it is simple — if the DDSMPI_ANY_SOURCE wildcard is used, then the message is accepted from the wildcard data reader, else it is accepted from the data reader particular to the specified sender.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::Recv(void *buf, int count, int source, int tag,
int &actualSource, int &actualTag) {
MPIMessage::MessageByTagSeq messageSeq;
int whichReader = (source == DDSMPI_ANY_SOURCE)?_size:source;
Take(tag, whichReader, messageSeq);
actualSource = messageSeq[0].senderRank;
actualTag = messageSeq[0].tag;
CORBA::Octet *ptr = (CORBA::Octet *)buf;
for (int i=0; i<count; i++)
ptr[i] = messageSeq[0].data[i];As the sample arrives twice — both to the wildcard data reader, and data reader for the specific sender, it must be accepted and discarded from the data reader that it wasn't accepted from previously.
// take the duplicated message from the other reader
MPIMessage::MessageByTagSeq discardSeq;
int otherReader = (source == DDSMPI_ANY_SOURCE)?actualSource:_size;
Take(tag, otherReader, discardSeq);
}As the tag can also be specified, or a wildcard used, accepting a data sample with Take() has two cases. The first handles the wildcard — the call to WaitOnDataAvailable() blocks until data is waiting on the specified data reader, and, when it arrives, the sample is taken and returned.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::Take(int tag, int whichReader,
MPIMessage::MessageByTagSeq &messageSeq) {
DDS::SampleInfoSeq infoSeq;
while (true) { // loop until get a valid data sample
if (tag == DDSMPI_ANY_TAG) {
// any tag - wait for data to arrive, then take()
WaitOnDataAvailable(whichReader);
if (_mdr[whichReader]->take(messageSeq, infoSeq, 1,
DDS::ANY_SAMPLE_STATE, DDS::ANY_VIEW_STATE,
DDS::ANY_INSTANCE_STATE) != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPI_ByTag::Take(): r->take() should have returned data");
}If a specific tag is desired, a check is made to see if an instance handle already exists that is associated with the tag. If it is, it is used in a call to take_instance(). It is possible, that, while waiting, a data sample may arrive at the data reader for a different instance (different tag). In this case, take_instance() returns DDS::RETCODE_NO_DATA and the code loops, again waiting for a new sample to arrive. The loop exits when data corresponding to the desired tag arrives, or an error occurs.
else {
// specific tag - look to see if an instance handle is
// already known for it
DDS::InstanceHandle_t instance;
std::map<int, DDS::InstanceHandle_t> &instancesByReader =
_readerInstances[whichReader];
std::map<int, DDS::InstanceHandle_t>::iterator it =
instancesByReader.find(tag);
if (it!=instancesByReader.end()) {
// have the instance handle - wait for any data on the
// reader, loop until data for the specific instance
// arrives
instance = it->second;
while (true) {
WaitOnDataAvailable(whichReader);
DDS::ReturnCode_t ret = _mdr[whichReader]->
take_instance(messageSeq, infoSeq, 1, instance,
DDS::ANY_SAMPLE_STATE, DDS::ANY_VIEW_STATE,
DDS::ANY_INSTANCE_STATE);
if (ret == DDS::RETCODE_OK)
break; // have data of the correct instance
// no data for that instance, so loop to try again
if (ret == DDS::RETCODE_NO_DATA)
continue;
// some other error occurred, so fail
throw DDSException(_rank,
"DDSMPI_ByTag::Take(): r->take_instance() failed");
}
}If an instance handle does not yet exist for the specific tag, one is created. A query condition is created to signal when data that matches the desired tag arrives, and that condition is waited on. When the wait succeeds, an instance corresponding to the tag has arrived, and lookup_instance() can retrieve it so it can be stored for future use. As we know data for the desired tag has arrived, a call to take_instance() will succeed.
else {
// don't have the instance handle - use a
// querycondition to wait for data on the
// instance to arrive, and remember the
// instance handle for the future
DDS::WaitSet_var ws = new DDS::WaitSet;
std::ostringstream q;
q << "tag = " << tag;
std::string query = q.str();
DDS::ReadCondition_var qc = _mdr[whichReader]->
create_querycondition(DDS::ANY_SAMPLE_STATE,
DDS::ANY_VIEW_STATE, DDS::ALIVE_INSTANCE_STATE,
query.c_str(), DDS::StringSeq());
if (!qc.in())
throw DDSException(_rank,
"DDSMPI_ByTag::WaitForData(): _mdr[whichReader]->create_querycondition() failed");
ws->attach_condition(qc);
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
DDS::ConditionSeq conditions;
conditions.length(0);
if (DDS::RETCODE_OK != ws->wait(conditions, infinite))
throw DDSException(_rank,
"DDSMPI_ByTag::WaitForData(): dataAvailable->wait() failed");
MPIMessage::MessageByTag sample;
sample.tag = tag;
instance = _mdr[whichReader]->lookup_instance(sample);
instancesByReader[tag] = instance;
if (_mdr[whichReader]->take_instance(messageSeq,
infoSeq, 1, instance, DDS::ANY_SAMPLE_STATE,
DDS::ANY_VIEW_STATE, DDS::ANY_INSTANCE_STATE) !=
DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPI_ByTag::Take(): r->take_instance() failed");
}
}The entire receive process is performed within a loop to ensure that a valid data sample has arrived. The loop will continue until valid data appears.
// exit the loop if the data was valid, else try again
if (infoSeq[0].valid_data)
break;
}
}Finally, waiting for data is performed by a using a WaitSet to trigger on DDS::DATA_AVAILABLE_STATUS becoming true for a data reader. WaitSets are cached to improve performance.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::WaitOnDataAvailable(int whichReader) {
DDS::WaitSet_var ws;
std::map<int, DDS::WaitSet_var>::iterator it =
_waitSets.find(whichReader);
if (it != _waitSets.end())
ws = it->second;
else {
ws = new DDS::WaitSet;
DDS::StatusCondition_var dataAvailableStatus =
_mdr[whichReader]->get_statuscondition();
dataAvailableStatus->
set_enabled_statuses(DDS::DATA_AVAILABLE_STATUS);
ws->attach_condition(dataAvailableStatus);
_statusConditions[whichReader] = dataAvailableStatus;
_waitSets[whichReader] = ws;
}
DDS::Duration_t infinite = {DDS::DURATION_INFINITE_SEC,
DDS::DURATION_INFINITE_NSEC};
DDS::ConditionSeq conditions;
conditions.length(0);
if (DDS::RETCODE_OK != ws->wait(conditions, infinite))
throw DDSException(_rank,
"DDSMPI_ByTag::WaitForData(): dataAvailable->wait() failed");
}Implementing DDSMPI_ByTag::Recv() in this manner eliminates the need for custom message filtering in favor of DDS's own behavior, but it does make the code to accomplish a receive more complex.
Lastly, we can implement DDSMPI_ByTag::Shutdown(). It is similar to the other Shutdown() methods in that it waits for samples to be received, deletes data readers, waits for associations to reach a count of 0, and then cleans up resources.
// DDSMPILib/DDSMPI_ByTag.cpp
void DDSMPI_ByTag::Shutdown() {
// wait until all messages have been acknowledged
DDS::Duration_t fivesec = {5, 0};
_mdw->wait_for_acknowledgments(fivesec);
// delete data readers
for (int i=0; i<=_size; i++) {
if (_sub[i]->delete_datareader(_mdr[i]) != DDS::RETCODE_OK)
throw DDSException(_rank,
"DDSMPI_ByTag::Shutdown(): _sub[i]->delete_datareader() failed");
}
_sub.clear();
// wait until the datawriter has no publications
// (all other subscribers have deleted their datareader)
WaitForPublicationCount(_mdw, 0);
// delete the remaining entities and shut down
MPIMessage::MessageByTag sample;
for (std::map<int, DDS::InstanceHandle_t>::iterator it =
_writerInstances.begin(); it!=_writerInstances.end(); it++) {
sample.tag = it->first;
_mdw->unregister_instance(sample, it->second);
}
_writerInstances.clear();
BaseShutdown();
}RING TEST
Now that the three methods are complete, we can now implement the ring test in a manner analagous to the MPI version.
// DDSMPI/DDSMPI.cpp
int RingTest(int argc, ACE_TCHAR *argv[], DDSMPIBase &m) {
m.Initialize(argc, argv);
int numIterations=1, numIntegers=1;
GetArg(argc, argv, ACE_TEXT("-i"), numIterations);
GetArg(argc, argv, ACE_TEXT("-n"), numIntegers);
int rank = m.GetRank();
int size = m.GetSize();
if (size<2) {
std::cout << "Must have a least 2 processes for this test" <<
std::endl;
m.Shutdown();
return 1;
}
std::vector<int> buffer;
buffer.resize(numIntegers);
int actualSource, actualTag;
if (m.GetRank() == 0) {
ACE_Profile_Timer timer;
timer.start();
for (int iter = 0; iter < numIterations; iter++) {
buffer[0] = 1; // initially 1 for the master
/*
MPI_Send(&buffer[0], numIntegers, MPI_INT, 1, 99,
MPI_COMM_WORLD);
MPI_Recv(&buffer[0], numIntegers, MPI_INT, size-1, 99,
MPI_COMM_WORLD, &status);
*/
m.Send(&buffer[0], numIntegers*sizeof(int), 1, 99);
m.Recv(&buffer[0], numIntegers*sizeof(int), size-1, 99,
actualSource, actualTag);
if (buffer[0]!=size) {
// correctness check
std::ostringstream msg;
msg << "Final count of " << buffer[0] <<
" does not match size of " << size;
throw DDSException(msg.str().c_str());
}
}
timer.stop();
ACE_Profile_Timer::ACE_Elapsed_Time et;
timer.elapsed_time(et);
std::cout << m.GetType() << ": Total elapsed time for " <<
numIterations << " iteration(s) and " << numIntegers <<
" integer(s): " << et.real_time <<
"s, time per iteration: " <<
((et.real_time / double (numIterations)) * 1000000) << "us"
<< std::endl;
}
else {
for (int iter = 0; iter < numIterations; iter++) {
/*
MPI_Recv(&i, numIntegers, MPI_INT, rank-1, 99,
MPI_COMM_WORLD, &status);
i++; // +1 for the worker
MPI_Send(&i, numIntegers, MPI_INT, (rank+1)%size, 99,
MPI_COMM_WORLD);
*/
m.Recv(&buffer[0], numIntegers*sizeof(int), rank-1, 99,
actualSource, actualTag);
buffer[0]++; // +1 for the worker
m.Send(&buffer[0], numIntegers*sizeof(int),
(rank+1)%size, 99);
}
}
m.Shutdown();
return 0;
}In order for the two methods to be compared, we can invoke the test with a small driver main().
// DDSMPI/DDSMPI.cpp
int ACE_TMAIN(int argc, ACE_TCHAR *argv[]) {
try {
int argc2 = argc;
int argc3 = argc;
ACE_TCHAR **argv2 = new ACE_TCHAR *[argc];
ACE_TCHAR **argv3 = new ACE_TCHAR *[argc];
for (int i=0; i<argc; i++) {
argv2[i] = ACE_OS::strdup(argv[i]);
argv3[i] = ACE_OS::strdup(argv[i]);
}
DDSInitialize(argc, argv);
DDSMPI_CFT cft;
RingTest(argc, argv, cft);
DDSMPI_Partition partition;
RingTest(argc2, argv2, partition);
DDSMPI_ByTag topic;
RingTest(argc3, argv3, topic);
DDSShutdown();
} catch (const DDSException& e) {
ACE_ERROR((LM_ERROR, ACE_TEXT("DDSException caught: %s\n"),
e.what()));
return -1;
} catch (const CORBA::Exception& e) {
e._tao_print_exception("CORBA Exception caught:");
return -1;
} catch (const std::exception& e) {
ACE_ERROR((LM_ERROR, ACE_TEXT("std::exception caught: %s\n"),
e.what()));
return -1;
}
return 0;
}argc and argv are duplicated so each test can run independently, as each manipulates command-line arguments. Two functions that initialize and shutdown DDS itself are invoked separately from the tests. If Initialize() and Shutdown() were only called once in the application, then these calls could be moved to BeginCommonInitialize() and EndCommonShutdown() respectively. For completeness, they are implemented as:
// DDSMPILib/DDSMPIBase.cpp
DDS::DomainParticipantFactory_var _dpf;
void DDSInitialize(int argc, ACE_TCHAR *argv[]) {
_dpf = TheParticipantFactoryWithArgs(argc, argv);
}
void DDSShutdown() {
TheServiceParticipant->shutdown();
ACE_Thread_Manager::instance()->wait();
}PERFORMANCE
With all three DDS methods complete, we can compare the performance of each method with the process ring as implemented in MPI. Scripts in the Tests directory were used to collect timings, and the data is collated in the Data directory. Each test described below was executed three times, and the results averaged — the raw measurements can be found in the file Summary.ods in the Data directory. All times are in microseconds and represent one loop around the ring. OpenMPI version 1.5.4 was used for the MPI tests, and OpenDDS 3.1 with TAO 1.6a p13 was used for the DDS tests.
The first scenario measures performance on a shared-memory architecture. A machine, running 64-bit Red Hat Enterprise Linux 5 (kernel 2.6.18-8.el5, GCC 4.1.1), with four 2.67 GHz Intel Xeon CPUs, was used for benchmarking. Four tests were run (passing blocks of 100, 500, 1000 and 2000 integers around the ring) for each of the four implementations — MPI; and the PARTITION, Content Filtered Topic, and ByTag DDS methods.
The MPI test was executed from the Output/Release directory for each count of integers (the -n parameter) and number of times around the ring (the -i parameter), with a command line similar to:
$MPI_ROOT/bin/mpirun -np 4 MPIRingTest -i 100000 -n 2000The DDS tests were executed from the Tests directory using the run_test_DDSMPI.pl test script, with the -s parameter indicating 4 instances are to be started.
./run_test_DDSMPI.pl -i2000 -n2000 -s4The results are as follows:
| Integers | MPI | PARTITION | CFT | ByTag |
|---|---|---|---|---|
| 100 | 6.875 | 574.348 | 766.987 | 2321.357 |
| 500 | 13.688 | 881.589 | 1020.053 | 2528.527 |
| 1000 | 22.620 | 1243.433 | 1403.900 | 3158.850 |
| 2000 | 32.919 | 1916.240 | 2154.393 | 4074.687 |
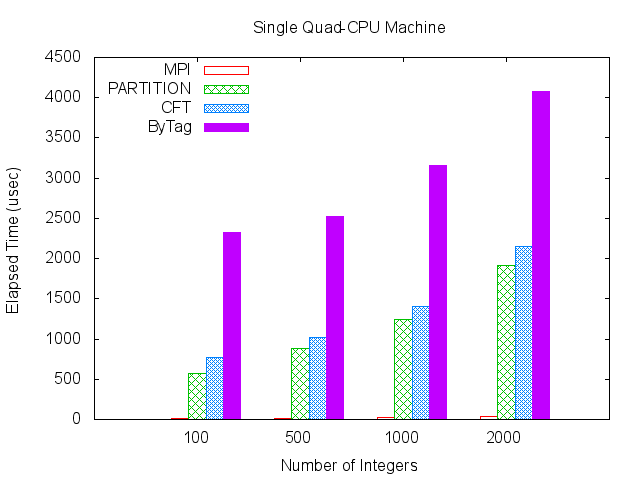
Figure 9. CPU Machine
As can be seen from the data, the MPI implementation is significantly faster than any of the DDS implementations, although OpenMPI 1.5.4 may be making in-memory optimizations that OpenDDS 3.1 is not. The ByTag method is surprisingly slow, but its need for two samples instead of one may explain its roughly doubled time as well.
The second scenario measures performance on a network of machines. 17 machines, each with a single 2.60GHz Intel Pentium 4 CPU, configured with 32-bit SuSE 11.1 (kernel 2.6.27.7-9-pae, GCC 4.3.2), and connected by Gigabit Ethernet, were used for this benchmark. The same set of tests as before — four different data sizes for each of the four methods — were performed.
Each MPI test was started from the Output/Release directory with a command line similar to:
$MPI_ROOT/bin/mpirun --hostfile labhostfile -np 17 MPIRingTest -i 20000 -n 2000
where labhostfile is a text file containing the hostnames of all machines that participate in the computation, here, lab01 through lab17. The -np 17 parameter causes 17 instances to be started by selecting machines in a round-robin fashion from the host file. This results in one instance starting on each listed machine.
Each DDS test was started from the Tests directory with a command line similar to:
./run_test_lab.pl -i2000 -n2000
The results are as follows:
| Integers | MPI | PARTITION | CFT | ByTag |
|---|---|---|---|---|
| 100 | 1519.987 | 13240.000 | 20239.467 | 71295.933 |
| 500 | 3121.873 | 16151.467 | 22915.200 | 82000.600 |
| 1000 | 4226.943 | 19219.433 | 25743.267 | 78114.167 |
| 2000 | 6314.297 | 25485.667 | 31919.033 | 96024.400 |
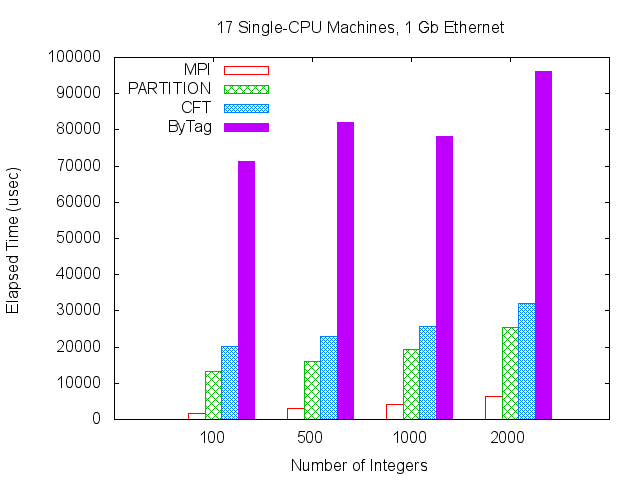
Figure 10. CPU and Ethernet
The overall pattern is the same as the shared memory test, with the MPI implementation much faster than any of the DDS methods, although the difference in magnitude isn't as great as in the multiprocessor test. The DDS methods perform also with the relative performance as previous, although, here, the execution time of the the ByTag method is not monotonically increasing. Also, overall, the tests ran much slower than in the multiprocessor case which is to be expected.
CONCLUSION
The MPI paradigm of communicating to processes by number, or by group, can be an effective programming methodology, especially for numeric computation that relies on matrices, grids or other geometric relationships. DDS can be used in a similar manner, although with a performance penalty due to conformance with the MPI model. The additional filtering, memory copying from MPI-style arrays to IDL structure-based DDS samples, and such have an impact that wouldn't be present in a typical DDS architecture. If an application is already using DDS and a rank-based form of communication is desired, is compute-bound rather than communication-bound, or sends a large enough amount of data in each message transmission, using DDS like MPI may be a viable approach.
Acknowledgements
Many thanks to Mike Martinez and Adam Mitz for insights into DDS concepts, strategies and OpenDDS behavior used in the preparation of this article.
REFERENCES
[1] MPI Documents
http://mpi-forum.org/docs/docs.html
[2] Documents associated with Data Distribution Services, v1.2
http://www.omg.org/spec/DDS/1.2/
[3] Message Passing Interface
http://en.wikipedia.org/wiki/Message_Passing_Interface
[4] MPI 3.0 Standardization Effort
http://meetings.mpi-forum.org/MPI_3.0_main_page.php
[5] Myrinet Overview
http://www.myricom.com/scs/myrinet/overview/
[6] InfiniBand Trade Association
http://www.infinibandta.org/
[7] Data parallelism
http://en.wikipedia.org/wiki/Data_parallelism
[8] Browne, Dongarra, Trefethen. Numerical Libraries and Tools for Scalable Parallel Cluster Computing
http://www.netlib.org/utk/people/JackDongarra/PAPERS/libraries-tools1.pdf
[9] Data distribution service
http://en.wikipedia.org/wiki/Data_distribution_service
[10] Barney. Message Passing Interface (MPI)
https://computing.llnl.gov/tutorials/mpi/
[11] SP Parallel Programming Workshop
http://www.mhpcc.edu/training/workshop/mpi/MAIN.html
[12] Snir. MPI Message Passing Interface Standard
http://www.mcs.anl.gov/research/projects/mpi/tutorial/snir/mpi/mpi.htm
[13] Pacheco. Parallel Programming with MPI Morgan Kaufmann Publishers, Inc., 1997.
[14] Karniadakis, Kirby. Parallel Scientific Computing in C++ and MPI: A Seamless Approach to Parallel Algorithms and their Implementation Cambridge University Press, 2003.
[15] Open MPI: Version 1.5.4
http://www.open-mpi.org/software/ompi/v1.5/
[16] OpenDDS
http://www.opendds.org/