The Git Distributed Revision Control System
By Austin Gilbert, OCI Senior Software Engineer
January 2015
Git is a fully distributed revision control system (RCS), like Mecurial, Bazaar, and Darcs. Git was created by Linus Torvalds, the creator of the Linux operating system to help support the development of the Linux kernel.
The purpose of all revision control systems is to manage sequences of changes over time to a collection of text documents in an orderly and meaningful way, granting the ability examine the documents at any point in time, moving forward and backward through file histories. A revision control system is an important tool in the software development process, providing several benefits to developers. Revision control systems facilitates concurrent and independent changes to a document collection with well defined conflict resolution enabling multiple developers to work independently on a code base simultaneously. Revision control systems provide quick and easy off-machine backup and recovery, ensuring nothing is lost if a single machine fails catastrophically as a copy of the document collection exists in multiple locations. Revision control systems allows us to return to known good states should we take a wrong turn in the development process. We can therefore make experimental changes without fear of causing permanent information loss or damage to a document collection. Finally, revision control systems give us traceability. By examining document histories, we can determine when and how bugs were introduced, and by comparing a buggy version with previous version we can quickly and easily correct the problem, either by reverting the change or patching it as necessary.
The primary motivating factor driving the creation of git was the need for a revision control system enabling parallel development by a distributed team of developers without the need for a constant connection back to a central server. Some open source examples of centralized revision control systems include CVS and Subversion. When utilized by thousands of developers simultaneously, a central server becomes a significant bottle-neck in the development process. Git supports multiple developers working from multiple locations with or without a persistent Internet connection, scales to thousands of developers, performs flawlessly (no data loss), and works quickly and efficiently.
In this paper we will introduce the git distributed revision control system, first describing its internal components and summarizing with practical use cases.
The Git Object Model
Object Store
At the heart of a git repository is the object store. It contains files, log messages, information about commiters, timestamps, file permissions, and other information necessary to rebuild any version or branch of the document collection.
The git object store is organized as a content-addressable storage system. Each of the objects in the store is identified with a unique identifier created by hashing the object’s content using the cryptographically Secure Hash Function (SHA1). Any change to an object’s content causes a change to the identity of the object. Objects are immutable. Therefore modifying an object’s content actually forces the creation of a new and separate object with its own unique identifier.
There are two major benefits to identifying objects in this way. (1) the object hashes are globally unique identifiers. If any two distributed repositories reference the same object hash, we can be sure they are referencing the same content. (2) building on the global uniqueness property of content and the way directories are represented in git, we can use the object hashes to quickly and efficiently determine if two document collections contain the same content. The comparison process need only exchange the hash values of the collection’s directories, the actual content or diff values don’t need to be exchanged. This is one of the primary reasons git is blazingly fast.
From the logical perspective, Git’s internal database stores every version of every file, not their differences. This is a drastic difference from most revision control systems. This is a requirement for git since it uses content addressable data storage, it must work with a complete version of the file not a diff. Git tracks histories as changes from one set of blobs to another, where the changes are linked together sequentially.
The logical requirement of storing a complete snapshot of the repository for each change set may seem daunting from an efficiency and storage standpoint. Fortunately, git has two optimizations to deal with this. Since the object store is content addressable, if an object hasn’t changed between commits, only a single copy of the object is needed. The repository snapshots reference the content using the SHA1 identity. Secondly, internally, git uses the concept of a pack file to compress the on-disk storage of file histories.
A pack file consists of a base image and a sequence of deltas. Each original SHA1 hash is maintained in the pack file and can be used as an index to the desired content in a pack file - i.e. given the base image how many of the deltas to apply to reach the desired SHA1 blob.
Git Object Types
There are only four data types in the object store: blobs, trees, commits, and tags. Despite git work flows heavily revolving around branching and merging, there is no branch object in the object store, branches are tag objects held in a special reference directory. Each of these four atomic objects form the foundation for higher level data structures in git.
blobs. Each version of a file is represented with a blob. Blobs contain opaque binary data. Blobs are the basic building block for git’s other data structures.
trees. A tree object represents one level of directory information. It records the blob identifiers, path names, and some meta data (e.g. file permissions) for all files in a single directory. Trees can also reference other trees, and so recursively build a complete directory hierarchy for a document collection. Trees are used to represent the state of the document collection at a specific point in time.
commits. A commit object holds metadata for each change in the repository. It stores the commiter, commit timestamp, and log message. Each commit also points to a tree object that captures the state of the repository after the commit is applied. Commits contain a list of previous commits they build on. The commits in this list are called ‘parents’. A typical commit has a single parent commit pointing to the commit immediately proceeding it in the history, i.e. the state the repository was in prior to this modification. Merges can produce commits with multiple parents. The initial commit in a repository has no parent commits.
tags. A tag object is a human readable label referencing a specific commit object in the repository. Tags are typically used to label released versions of software. A tag may merely be a reference (a light-weight tag) or it may have a commit message associated with it. In the later case, an object is created for the tag in the data store and the tag becomes a permanent part of the repository. In the light-weight case, the commit hash value is written to a file in the refs directory.
The Staging Area
In git parlance, the working directory is the directory holding your document collection managed by git. The staging area, or index as it is sometimes called, is the buffer between your working directory and the git object store.
The staging area holds a set of prospective modifications to the object store. File additions, file removals, file renames, file permission changes, and file edits are held in the staging area until a commit is made.
Git commands are used to manipulate the contents of the staging area, and eventually commit the changes to the repository, resulting in the creation of objects in the git data store.
Modifying the Staging Area and the Data Store
Now that we’ve described the git object model, data store, and the staging area, it is time to demonstrate how we change the state of a git repository using the git command line.
Git works as a command line tool taking a command along with optional flags and parameters to the command. The most commonly used git commands and their uses are described in Appendix A.
To view the contents of your staging area and the status of your working directory, use the status command.
$ git statusThe status command displays the contents of the staging area in green at the top of the output. Modifications to your working directory not in the staging area (and thus not in the next commit) are displayed in red at the bottom of the output. If you don’t have a colorized console, don’t worry, the staging area contents and the working directory status are also labeled.
After a file has been edited, we add it to the staging area using the add command.
$ git add modified_file.cIf the file is actually new to the repository, git will add its reference to the appropriate tree object as well, meaning the file history is then being tracked in the repository.
To commit changes contained in the staging area to the data store, thereby altering the state of the git repository, use the commit command.
You need to provide a commit message to create a commit in the data store. By default git uses vim for commit messages, you can configure it to use your favorite editor with the environment variable GIT_EDITOR. You can also supply the commit message using the -m option.
$ git commit -m "Adding filename.c to the repository."Git does not manage your working directory using file directories like hierarchical revision control systems do. Instead, git creates tree objects in the data store as needed when a file path indicates a new sub-directory. The tree objects are created in the data store behind the scenes.
For example, adding a new file under a new sub-directory like so:
$ git add subdir/path.cwould cause git to create two objects: a blob containing the contents of path.c, and a tree object with the path name and a reference to the blob. As such, you cannot create empty directories in git. The hash value for the new tree object would be added to the list of reference objects on the root tree object.
To remove a file from the working directory and the repository, we use the rm command.
$ git rm filename.c This adds an entry to the staging index indicating filename.c is going to be removed. Once the staging area is committed, git will delete filename.c from the repository by removing its SHA1 object identifier from the appropriate tree object in the data store, it will then physically delete the file from disk on your behalf.
Renaming or moving a file is done with the mv command.
$ git mv filename.c newname.cAs an interesting side note, because git uses a content-addressable data store, if you delete and then add the file under a new path, git will often detect this and record the delete/add as a move instead. This is a useful feature under merge resolution.
To create a tag in the data store, we use the tag command, supplying a human readable label and possibly a message.
$ git tag v1.0 -m "Release version 1.0"By default, the tag command creates the tag object referencing the last commit in the current working branch (referred to as HEAD), however, a specific commit object can also be supplied.
$ git tag v1.0 deadbeef -m "Release version 1.0."The tag command is also used to print a list of tags in the repository. This is the behavior when no arguments are supplied.
$ git tagBranches and Merging
During the software development life cycle, it is paramount new features be introduced in such a way they don’t destabilize already functioning code. Most revision control systems have a logical concept that allow us to copy the repository at a point in time, and then make modifications to the copy, leaving the mainline code in a known good state. These copies are called branches. Branches help us isolate changes until we know they’re ready for integration. The process of integrating a branch is called merging. In this section, we’ll discuss branching and merging with git.
In git, creating and merging branches is trivially easy. Therefore using branches before making any modification is the recommend approach to doing work on your repository.
In git, branches are merely tag objects stored in a special reference directory. We can create or view branches using the branch command. To list all branches in our copy of the repository (called the local repository), we run the branch command with no arguments.
$ git branchAll branches that exist in our local repository will be listed. By default, the only branch in a git repository is themaster branch.
Git is distributed. If a git repository knows about a remote copy, it can also display those branches. To display, all known branches we run the branch command with the -a option.
$ git branch -aThis will show local branches in white and remote branches in red. The currently checkout branch will be displayed in green. Branches can be shared by pushing the data store to other repositories or by fetching or pulling remote data stores to the local repository. We will cover the syntax for sharing in the Remote Repositories section below.
Branch Creation
To create a branch from the current branch, we give the branch command a parameter - the name of the new branch.
$ git branch new_branchNow listing the branches will show our new branch. We can checkout our new branch and start working on our changes by using the checkout command.
$ git checkout new_branchThis checks out our new branch. Git protects you from losing changes. It will not let you switch branches if you have changes you’d lose by doing so. Make sure you’ve committed all changes on your current branch before switching to another branch to do work.
To create a branch and check it out in one step, perform the following:
$ git checkout -b new_branch branch_frombranch_from is the name of the branch to create new_branch from.
Branch Integration
After you’ve implemented your changes and commits, integrate your feature branch using the mergecommand. Before merging, you checkout the branch you wish to integrate into.
$ git checkout develop
$ git merge --no-ff new_branchIf there are no conflicts, you will be prompted for a commit message for the merge commit.
If there are conflicts, you will be dropped into conflict resolution mode. You will need to use the mergetool command to resolve conflicts. The mergetool command launches your favorite diff tool to identify differences on both sides of the merge. After saving changes to each file, commit the merge using the commit command.
If there are conflicts and you don’t wish to keep the merge, you can back out the changes by using the –abort option while in merge resolution mode.
$ git merge --abort Git will cleanup you working directory and put you in a known good state - as if the merge never occurred.
Git supports n-way merging. You can merge as many branches as you wish to do so at one time. Generally, we recommend only two at a time for simplicity’s sake.
Branching Model
Logically, we can create and manage branches in git repositories however we like. However, adopting common conventions can greatly aid the software development process.
The prevailing git branch management strategy is described on nvie.com. It covers conventions for the full software development life cycle. We will summarize the conventions here.
The primary convention is that the role of the master branch changes. Master becomes a linear history representing only released versions of the software. All development work and integration move to a new branch called develop.
As developers set out to implement new features, they create topic or feature branches off the develop branch. Generally, there is no naming convention for feature branches other than picking a descriptive and meaningful name representing your task. Once features are complete, they’re integrated back into the develop branch. See the below figure for an overview of the model.
Branches that have been integrated into develop can be deleted using the -d option.
$ branch -d branch_namebranch_name is the name of the feature branch we wish to delete. When using the -d option, git will prevent you from deleting branches which haven’t been merged back into their parent branches. This prevents you from accidentally deleting work. If we decide a branch will never be integrated and we still wish to delete it, we can force deletion using the -D option.
$ branch -D branch_name 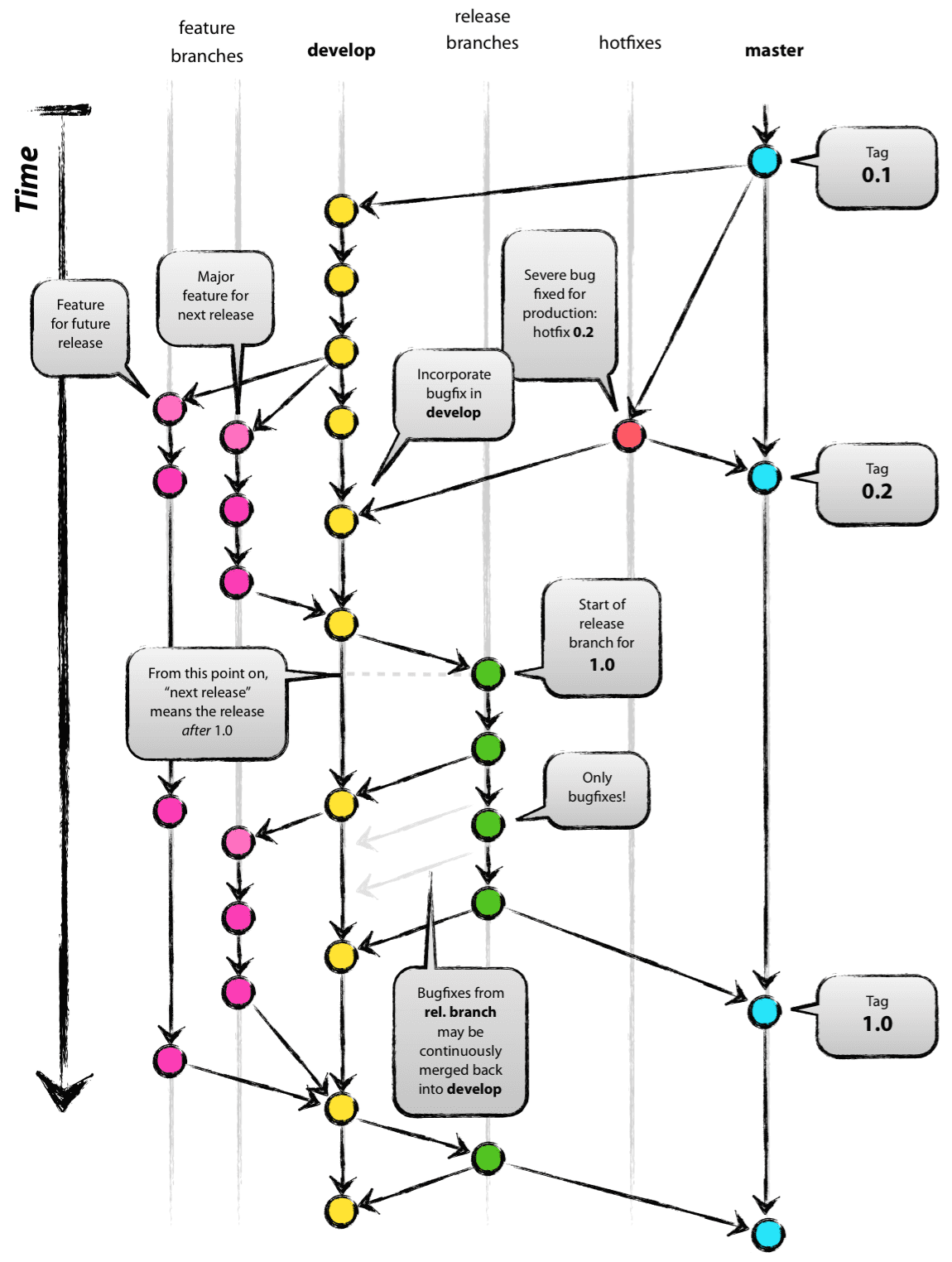
As all required features are integrated into develop, the software becomes feature complete. Once feature complete, thedevelop branch is used to create a release branch. The release branches are prefixed with release, followed by a dash and the version. Once the release is approved the release branch is merged into master.
The merge commit is the release of the new version. The commit is then tagged with a human readable label for future reference to the release. The release branch may be deleted. However, if you are going to maintain multiple versions of the software in parallel as is often the case with libraries, then you may wish to keep the release branch around as a long-lived branch in the repository where bug fixes will be integrated.
As time goes on, bugs are found in the released versions of the software. As they are found, branches are created from the release tag. These branches are prefixed as hotfix branches. For example, if version 1.0 of the software had a bug, we’d branch off the tag for version 1.0 and call that branch hotfix–1.0.1 or hotfix–1.0p0, etc. The hotfix branch will contain all changes necessary to fix the bug. Once the bug is fixed, the hotfix branch is merged into master (or the long-lived release branch if parallel versions of the software must be maintained). The hotfix branches are also merged back into develop and then deleted .
Remote Repositories
Git is fully distributed. Everyone gets an entire copy of the repository history when they clone a repository. Any changes users make to a repository are local to their repository until they are explicitly shared.
Technically, git has no centralized authority for determining the official version of the repository. The distinction is made only by convention. Typically, the maintainer of the software has the official copy of the repository.
Typically, users begin working with a git repository by invoking the clone command.
$ git clone urlThis downloads the complete history of the repository and all of the objects in the repositories data store. After cloning, a git repository retains a reference to the original repository. This reference is displayed as a remote repository named origin. You can actually rename the reference to anything you wish, or add repository references to other remote repositories (those of your collaborators for instance).
To view remote repositories use the remote command.
$ git remoteIf you wish to see the URLs of the remotes in addition to the labels, use the -v option.
$ git remote -vThis command will print a list of all known remote repositories and their URLs. When viewing remote branches with git branch -a, git will display the remote name after the label remotes followed by the branch name - all separated with a ‘/’. The following is example output from running git branch -a:
master
* develop
remotes/origin/HEAD -> origin/master
remotes/origin/master
remotes/origin/develop To add a new remote, we again use the remote command. This time supply a name for the remote and a URL where the repository is available. For example:
$ git remote bobs_repo https://github.com/bob/repo.gitThis would add a remote called bobs_repo and grab the repository hosted at the github URL. Generally, speaking when you’re adding a remote, git goes ahead and downloads that remote’s object store so you can begin viewing the remote’s branches and histories immediately.
Getting And Viewing Remote Changes
To download the latest changes from a remote branch, use the fetch command.
$ git fetch origin/developThis command would grab the latest commits to the develop branch from the repository origin. To view the changes, use the log command with the branch name.
$ git log origin/developViewing specific changes can be accomplished with the show command, the diff command, or the difftool command. The show and diff commands display a commit’s diff using git’s internal diff engine, the difftool command uses your configured diff program to display the changes. When viewing changes on remote branches, it is easiest to provide the hash values referenced in the log message to view changes.
$ git difftool deadbeef~ deadbeefHere we’re using some short hand notation so we don’t have to type the entire hash. We’re also using notation to indicate ‘previous commit’, the ~. For a complete reference of the possible shorthand notations, run git rev-parse --help and read the section entitled ‘SPECIFYING REVISIONS’.
The above command would display the changes introduced in the commit with the hash starting with deadbeef. The revision proceeding deadbeef would be on the left and changes contained in the deadbeef commit would be displayed on the right.
To download and integrate changes from a remote branch, use the pull command. This command would be used to keep your integration and master branches in sync with origin. For example:
$ git checkout master
$ git pull originThe pull command executes a fetch, followed by a merge.
Sharing Local Changes With A Remote
After you’ve completed a feature and integrated it into your develop branch, you’d do a git pull origin to get any new changes from the remote repository, and then you’d want to share your changes. To share a copy of your changes with a remote repository use the push command. The long-form syntax for push is as follows:
$ git push origin develop:developHere origin is the remote repository name. The first develop is the name of the local branch we wish to share, the seconddevelop (after the colon) is the name of the remote branch we wish to push to. In this case, they match.
If the remote branch exists, git must be able to execute a fast-forward merge onto that branch (indicating the branches have a shared history) otherwise the push will fail.
If the remote branch does not exist, git will create the branch in the remote repository.
Configuring the “push.default” setting to “simple” will allow us to use the shorthand version for a push.
$ git pushThis will push our current branch to the upsteam repository (origin by default) branch of the same name. This is the preferred configuration. If ever in doubt about what to push where, use the long-form syntax.
Collaborating With Git
Being fully distributed has many attractive benefits, but having a central copy of the repository can aid in collaboration.
In a corporate environment, where there are a handful of maintainers working on a project (for some definition of handful) and everyone needs write access to the central repository, the best approach is to host the central copy of the repository on a sever to which everyone has Secure Shell (SSH) access. Then manage write access to the repository using gitolite.
For open source software, where the general public needs access to the software in order to help make changes, a central copy of the repository can also be useful. However, exposing your official centralized copy of git to the general public is ill advised. Git is a powerful tool. It is not however a tool that protects itself from the user. As such it is easy to put a git repository in an undesirable state - especially for beginners who don’t yet fully understand the consequences of what they are doing.
For these situations, github.com is useful alternative. In github’s model, a central copy of the repository is hosted in their data center. Maintainers have read/write access to this copy of the repository. They work by cloning the central copy and then pushing changes back to it, like you’d normally do.
Everyone else has read-only access to the central repository. To make changes to the source code, a contributor must fork the central repository, creating their own copy - also hosted on github.com. They then clone their fork, implement the changes they wish to make, pushing their changes back to their forked version. Once they’re done with a feature, they send a pull request to the maintainers of the official repository. The maintainers may then choose whether or not to integrate contributions.
It sounds a little convoluted, but in practice it works very well. Github adds enough isolation around the official copy of the code to protect it from accidental mishaps.
Summary
We’ve reviewed the git distributed revision control system. We’ve described its object model and data store, as well as the staging area, branching and merging functionality, and the intended branching model. We’ve also discussed distributed collaboration using git and how to manage remote repositories. This introduction is only the tip of the iceberg. For further reading to understanding and using git, see The Git Parable and Loeliger’s book Version Control with Git.
References
- Mecurial
http://mercurial.selenic.com - Bazaar
http://bazaar.canonical.com/en/ - Darcs
http://darcs.net - CVS
http://www.nongnu.org/cvs/ - Subversion
https://subversion.apache.org - SHA1
https://en.wikipedia.org/wiki/SHA–1 - Preston-Werner, Tom. The Git Parable. May, 2009.
http://tom.preston-werner.com/2009/05/19/the-git-parable.html - GitHub.com
http://github.com - Gitolite
http://gitolite.com/gitolite/ - Driessen, V. A successful Git branching model. Jan., 2010.
http://nvie.com/posts/a-successful-git-branching-model/ - Loeliger, J., and M. McCullough. Version Control with Git. 2012. 978–1–449–31638–9 .
Appendix A
The following is a list of the most commonly used git commands in alphabetic order followed by a brief description of their purpose [Loeliger]:
- add, adds file contents to the changeset.
- bisect, helps to find a change that introduced a by using a binary search of the repository history.
- branch, lists, creates, or deletes branches.
- checkout, switches the working directory to a given branch, or restores a file in the working directory to the version from a given branch.
- clone, downloads a copy of a repository.
- commit, records a change to the repository.
- diff, shows changes between commits, the commit and working trees, or differences between branches, etc.
- fetch, downloads objects and references from another repository.
- grep, searches the code for keywords or binary strings displaying matches.
- init, creates a new git repository.
- log, shows the history in the form of the commit log.
- merge, joins two or more development histories into one.
- mv, moves or renames a file, directory, or symlink.
- pull, fetches from and merges another repository or local branch.
- push, updates remote refs along with associated objects.
- rebase, forward-ports local commits to the updated upstream head.
- reset, changes HEAD to the specified state.
- rm, removes files from the working directory and changeset.
- show, displays various types of objects.
- status, displays the working directory status (new files, modified files, etc).
- tag, creates, lists, deletes tag objects. Tag can also be used to verify GPG signed tag objects.
For convenience, the documentation for these commands and all other git commands are available using the –help option at the command line. E.g.,
$ git --help
$ git add --helpSoftware Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
