GPU Computing with OpenCL
By Charles Calkins, OCI Senior Software Engineer
July 2011
Introduction
In the past, processor vendors have increased performance by increasing CPU clock rates, but an upper limit is being reached due to factors such as the settling time of CPU circuitry and the dissipation of waste heat. Performance can still be improved by adding additional processors — dual and quad core machines are now becoming commonplace, but adding more than a handful of cores is cost-prohibitive on commodity hardware.
Additional processing power can be achieved by utilizing the GPU of video cards that allow general purpose computing. As far back as 2001, consumer-grade graphics cards from NVidia [1] allowed part of the rendering pipeline to be customized via user-written code, and since then GPUs have advanced to where more general computation is possible. GPU computing is now used in areas such as science, engineering, cryptography, and computer graphics. [2]
As a GPU is designed to execute the same operations on each item of work (such as a pixel of an image, or an element of an array), it can be conceptualized as a large SPMD (Single Program, Multiple Data) processor array supporting data-parallel applications. Applications most suited to this programming model are ones where there is little dependency between the data items in the computation, such as vector addition or image processing. [3, p. 21] Computations that are task, rather than data, driven, may not benefit as much.
Up to now, the means by which to write a general purpose computation for a GPU has either been vendor-specific, as with CUDA [4, 5] requiring graphics cards from NVidia, or OS-specific, as with Microsoft's DirectCompute [6] requiring DirectX on Windows XP and higher. In contrast, the Khronos Group has defined OpenCL [7, 8]. OpenCL implementations exist for Windows, Mac OS X and Linux, allowing code to be multiplatform. OpenCL devices not only include GPUs from various vendors, but standard CPUs and special accelerators, allowing code to be written once, yet be able to execute on a wide range of hardware devices.
This article will present two examples to show how general purpose applications can be written using OpenCL. The code for this article, available in the associated code archive, was developed on an HP Pavilion dv7-4170us laptop with an AMD Phenom II 2.2 GHz triple core processor and entry-level ATI Mobility Radeon HD 5470 graphics adapter [9]. The code was compiled with Visual Studio 2010, and the AMD Accelerated Parallel Processing (APP) SDK v2.4 [10] was used to provide the OpenCL libraries. Care was taken to ensure compatibility between the video driver and the APP SDK [11]. Each data point in the test data was produced by running the test five times, dropping the highest and lowest values, and averaging the remaining three. While OpenCL is a C API [12], we will use the C++ bindings [13]because error handling and resource cleanup is easier to manage.
Example 1 — Image Generation
While GPUs can be used to accelerate arbitrary computations, their fundamental purpose is to process computer graphics, so an application in this domain should demonstrate a significant performance benefit. In this example, we will generate a raytraced image of the Mandelbox [14] into a data buffer, taking advantage of several of the built-in graphics-related functions. We will first develop a host driver program which will manage interaction with the GPU, and then the code for the GPU program itself.
Host Driver Program
To allow failures of OpenCL API functions to be thrown as exceptions, __CL_ENABLE_EXCEPTIONS must be defined. The thrown exception is of type cl::Error, a subclass of std::exception.
// OCL_Mand.cpp
#define __CL_ENABLE_EXCEPTIONSThe cl.hpp header must be included to use the OpenCL C++ bindings, and omp.h is only needed in this example so execution can be timed.
- #include <iostream>
- #include <fstream>
- #include <omp.h>
- #include <CL/cl.hpp>
- #include "TGA.h"
We will allow the image dimensions to be specified on the command-line.
- int main(int argc, char *argv[]) {
- size_t width = 512;
- if (argc>=2)
- width = atoi(argv[1]);
- size_t height = width;
An OpenCL platform consists of a host computer with one or more compute devices. Platforms are enumerated by a call to cl:Platform:get().
- cl::Program program;
- std::vector<cl::Device> devices;
- try {
- std::vector<cl::Platform> platforms;
- cl::Platform::get(&platforms);
- if (platforms.size() == 0) {
- std::cout << "OpenCL not available" << std::endl;
- return 1;
- }
OpenCL devices can consist of GPUs, CPUs, and special accelerators. The Pavilion laptop used for development has two devices — one CPU device representing the triple-core Phenom II, and one GPU device representing the dual-processor Mobility Radeon HD. We request GPU devices from the first (and only, in our case) platform found via the CL_DEVICE_TYPE_GPU flag. Other constants can be used to request other device types, or CL_DEVICE_TYPE_ALL for all available devices.
An OpenCL context represents the execution environment — the set of devices, memory buffers, and other resources that are necessary for the computation.
- cl_context_properties cprops[3] = { CL_CONTEXT_PLATFORM,
- (cl_context_properties)platforms[0](), 0 };
- cl::Context context = cl::Context(CL_DEVICE_TYPE_GPU, cprops);
-
- devices = context.getInfo<CL_CONTEXT_DEVICES>();
- if (devices.size() == 0) {
- std::cout << "GPU device not available" << std::endl;
- return 1;
- }
Commands are sent to a device via a command queue. Here, we establish a queue to the first (and only, in our case) GPU device. By default, a queue executes commands in the order that they were queued, but out-of-order execution can be specified by setting the CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE flag as a third constructor parameter. Dependencies between queued items can be established by a system of events (completion of an action fires an event, and a dependent action waits on the event before it executes) to control execution, but events are not needed in these examples.
cl::CommandQueue queue = cl::CommandQueue(context, devices[0]);A kernel is a function that executes on an OpenCL device, and a program is a set of kernel and auxilliary functions. Kernel source code must be compiled before it can be executed on a device. While methods exist to load compiled code, binaries must be provided with the application for every supported platform. If the kernel code is compiled from source, however, only the one source code file needs to be included with the host driver executable. If distributing kernel source code as a clear-text file is not desired, the code can be embedded into the driver executable as a large block of strings, as will be done in the second example in this article.
For this example, a separate file, Mandelbox.cl is used, and will be described in the next section. The code is loaded into a string, the string compiled into a program, and the function Mandelbox identified as the kernel function to be used. If compilation fails, an exception will be thrown which will be handled later in the program.
- std::string source = LoadKernelSource("Mandelbox.cl");
- cl::Program::Sources sources(1,
- std::make_pair(source.c_str(), source.size()));
- program = cl::Program(context, sources);
- program.build(devices);
- cl::Kernel kernel = cl::Kernel(program, "Mandelbox");
As a kernel running on a GPU does not have direct access to the host, arguments to the kernel must be provided to it before it starts. Arguments can include scalar values, as well as memory buffers that can be one, two, or three dimensional. As we wish to create an image, a 2D buffer is used. No data needs to be passed into the kernel in the buffer, but the kernel must be able to pass data out, so the buffer can be marked as write-only by the kernel by using the CL_MEM_WRITE_ONLY flag. We wish the buffer to be structured as containing red, green, blue and alpha image channels, each an unsigned 8-bit value. The GPU device in the Pavilion limits the image width and height to 8192x8192.
cl::Image2D img = cl::Image2D(context, CL_MEM_WRITE_ONLY,
cl::ImageFormat(CL_RGBA, CL_UNSIGNED_INT8), width, height);Two arguments are passed to the kernel — a configuration parameter that affects the image generation, and the buffer that was just created.
- float scale = 3.0f;
- kernel.setArg(0, scale);
- kernel.setArg(1, img);
The kernel is now executed, with the OpenMP omp_get_wtime() function used to time the execution. Command queues can be profiled by setting the CL_QUEUE_PROFILING_ENABLE flag when the queue is constructed and calling clGetEventProfilingInfo() to obtain timings, but using OpenMP allows profiling to be performed consistently between both OpenCL and non-OpenCL code examples.
The enqueueNDRangeKernel() method starts the kernel function running on each element of a problem — in this example, on every pixel of the width x height image buffer. The finish() method ensures that all commands in the queue have completed before the execution time is measured.
- double startTime = omp_get_wtime();
- queue.enqueueNDRangeKernel(kernel, cl::NDRange(),
- cl::NDRange(width, height), cl::NDRange());
- queue.finish();
- double endTime = omp_get_wtime()-startTime;
As the buffer is available to the GPU device, it must be mapped into host memory with enqueueMapImage() to be accessed by the CPU. The second parameter of enqueueMapImage() is set to CL_TRUE so the operation is blocking (vs. non-blocking, where events can be used to monitor progress), with the subsequent parameters indicating that the range from (0,0) to (width-1, height-1) is to be mapped for reading. The range must be expressed in three dimensions, so the mapping origin is (0,0,0) and the size has a depth of 1.
- size_t image_row_pitch, image_slice_pitch;
- unsigned char *ptr = (unsigned char *)queue.enqueueMapImage(img,
- CL_TRUE, CL_MAP_READ, range3(0,0,0), range3(width,height,1),
- &image_row_pitch, &image_slice_pitch);
The buffer was constructed such that it matches the image data portion of a Targa image file [15] to allow easy writing of the rendered image to disk.
WriteTGA("test.tga", width, height, ptr);At the end of the execution, the time to calculate the image is displayed. If any errors were generated, they are also displayed. If the program failed to compile, the build output is presented to aid in debugging.
- std::cout << "Calculation time: " << endTime << std::endl;
- } catch (cl::Error &err) {
- std::cout << "Error: " << err.what() << "(" << err.err() << ")"
- << std:: endl;
- // if it was a compilation error
- if (err.err() == CL_BUILD_PROGRAM_FAILURE)
- std::cout <<
- program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(devices[0])
- << std::endl;
- } catch (std::exception &e) {
- std::cout << "Error: " << e.what() << std::endl;
- }
-
- return 0;
- }
-
Two additional functions are used in the code above. The LoadKernelSource() method reads the specified code file from disk and loads it into a string, and the range3() method provides a shortcut for creating a 3-component range.
- std::string LoadKernelSource(std::string filename) {
- // load from the current directory, or the parent directory,
- // such as when the driver executable is in a subdirectory
- // of the source code
- std::ifstream file(filename);
- if (!file.is_open()) {
- file.open("../" + filename);
- if (!file.is_open())
- throw std::exception("File not found");
- }
-
- return std::string((std::istreambuf_iterator<char>(file)),
- std::istreambuf_iterator<char>());
- }
-
- cl::size_t<3> range3(size_t a, size_t b, size_t c) {
- cl::size_t<3> range;
- range.push_back(a); range.push_back(b); range.push_back(c);
- return range;
- }
An uncompressed Targa file consists of a header, followed by the image data. The pack pragma is used to ensure the header remains 18 bytes and has no additional structure padding, otherwise an invalid file will be written.
- // TGA.cpp
- #include <fstream>
- void WriteTGA(char *fileName, unsigned short width,
- unsigned short height, unsigned char *data) {
- #pragma pack(push, 1)
- struct {
- unsigned char _idLength, _colorMapType, _imageType;
- unsigned short _cMapStart, _cMapLength;
- unsigned char _cMapDepth;
- unsigned short _xOffset, _yOffset, _width, _height;
- unsigned char _pixelDepth, _imageDescriptor;
- } tgaHeader;
- #pragma pack(pop)
-
- memset(&tgaHeader, 0, sizeof(tgaHeader));
- tgaHeader._imageType = 2;
- tgaHeader._width = width;
- tgaHeader._height = height;
- tgaHeader._pixelDepth = 32;
- std::ofstream tga(fileName, std::ios::binary);
- tga.flags(0);
- tga.write((char *)&tgaHeader, sizeof(tgaHeader));
- tga.write((char *)data, width*height*4*sizeof(unsigned char));
- }
GPU Program
With the host application complete, we now write the GPU program in the file Mandelbox.cl. OpenCL kernels are written in a somewhat restricted form of C99 [3, p. 98], with additional OpenCL-specific specifiers. One of the new specifiers is __constant, to indicate that the data should be stored in the constant memory of the device. This is necessary as dynamically allocated memory is not supported, so omitting __constant in this instance on a variable outside of function scope causes a compilation error.
- // Mandelbox.cl
-
- // number of iterations
- __constant int maxIterations = 50;
Vector types are supported, such as float3. Elements are accessed via x, y, z and w, as appropriate. Multiple accessors can be used simultaneously, e.g., eyePos.xy is of type float2.
// eye position
__constant float3 eyePos = (float3)(0.0f, 0.0f, -15.0f);While single-precision floating point values are available, double-precision floating point is an optional OpenCL extension that is not supported on the hardware of the Mobility Radeon HD 5470.
// maximum ray length from the eye
__constant float maxRayLength = 100; Additional rendering constants are needed. A fully-fledged renderer would allow a user to specify camera and lighting details as parameters to the kernel, but the additional complexity is not needed for this example.
- // maximum number of steps to take along the ray
- __constant int maxSteps = 100;
-
- // light parameters
- __constant float3 ambient = (float3)(0.1f, 0.1f, 0.1f);
- __constant float3 lightPos = (float3)(5.0f, 5.0f, -10.0f);
-
- // distance estimation constants
- __constant float fixedRadius2 = 1.0f * 1.0f;
- __constant float minRadius2 = 0.5f * 0.5f;
- __constant float3 boxFoldColor = (float3)(0.1f, 0.0f, 0.0f);
- __constant float3 sphereFoldColor = (float3)(0.0f, 0.1f, 0.0f);
Structs and typedefs are supported, as in standard C.
- typedef struct {
- float distance;
- float3 color;
- } DEInfo;
Algorithms exist which, given a point, return an estimated distance to the Mandelbox. The one used here was adapted from a post on Fractalforums.com [16].
- DEInfo DistanceEstimation(float3 z0, float scale) {
- DEInfo info;
- info.distance = 0.0f;
- info.color = 0;
-
- float3 c = z0;
- float3 z = z0;
- float factor = scale;
-
- int n;
- for (n = 0; n < maxIterations; n++) {
Operations can be performed on vector types, such as the addition of two float3 variables expressed as a single +=.
- if (z.x > 1.0f) { z.x = 2.0f - z.x; info.color+=boxFoldColor; }
- else if (z.x < -1.0f) { z.x = -2.0f - z.x;
- info.color+=boxFoldColor; }
-
- if (z.y > 1.0f) { z.y = 2.0f - z.y; info.color+=boxFoldColor; }
- else if (z.y < -1.0f) { z.y = -2.0f - z.y;
- info.color+=boxFoldColor; }
-
- if (z.z > 1.0f) { z.z = 2.0f - z.z; info.color+=boxFoldColor; }
- else if (z.z < -1.0f) { z.z = -2.0f - z.z;
- info.color+=boxFoldColor; }
A number of graphics-oriented functions are built into OpenCL, such as length(), the computation of the length of a vector.
- float r = length(z);
- float r2 = r*r;
-
- if (r2 < minRadius2) {
- z = (z * fixedRadius2) / minRadius2;
- factor = (factor * fixedRadius2) / minRadius2;
- info.color+=sphereFoldColor;
- }
- else if (r2 < fixedRadius2) {
- z = (z * fixedRadius2) / r2;
- factor = (factor * fixedRadius2) / r2;
- info.color+=sphereFoldColor;
- }
-
- z = (z * scale) + c;
- factor *= scale;
- r = length(z);
-
- info.distance = r / fabs(factor);
- if (r > 1024)
- break;
- }
clamp() is another built-in function which restricts each component of a vector to the specified minimum and maximum.
- info.color = clamp(info.color, 0, 1);
-
- if (n == maxIterations)
- info.distance=0;
- return info;
- }
This method computes the surface normal by evaluating the distance to small displacements from the point in question. It uses normalize(), another built-in function, which reduces a vector to unit length.
- float3 Normal(float3 z, float e, float scale) {
- float3 xoff = (float3)(e, 0.0f, 0.0f), yoff = (float3)(0.0f, e, 0.0f),
- zoff = (float3)(0.0f, 0.0f, e);
-
- float3 d = (float3)
- ( DistanceEstimation(z + xoff, scale).distance -
- DistanceEstimation(z - xoff, scale).distance,
- DistanceEstimation(z + yoff, scale).distance -
- DistanceEstimation(z - yoff, scale).distance,
- DistanceEstimation(z + zoff, scale).distance -
- DistanceEstimation(z - zoff, scale).distance );
-
- return normalize(d / (2*e));
- }
Functions that are to be used as kernels are marked with the __kernel specifier. The name of the function is referenced in the call to cl::Kernel(), and its parameters, in order, correspond to what is given in the kernel.setArg() calls. Specifiers are given to indicate the memory usage of the arguments. Here, __read_only for the input-only scale value, and __write_only for the output-only image buffer.
__kernel void Mandelbox(__read_only float scale,
__write_only image2d_t dest_img) {Each individual item of work can be referenced multiple ways, including by index relative to all of the work to perform. The function get_global_id() returns the index, for the specified dimension, of the current running kernel instance. As the problem is expressed in two dimensions, the indices for dimensions 0 and 1 are retrieved and are interpreted as the x,y coordinates of a pixel in the output image buffer. Indices relative to a local work group are also available, where a work group has additional capabilities such as data sharing, but only the global IDs are needed in this example.
- // pixel being evaluated by this kernel instance
- int x = get_global_id(0);
- int y = get_global_id(1);
The function get_global_size() returns the maximum number of work items for the specified dimension, which, for this example, correspond to the image size.
- // image dimensions
- int width = get_global_size(0);
- int height = get_global_size(1);
A more complex renderer would determine a ray to trace based on a matrix-specified, movable camera. In our simplified case, the vector from the eye point to a point on the view plane (a virtual grid with a resolution equal to the image dimensions) is sufficient to determine the direction of a ray to trace.
- // view plane ranges from (-5,-5,-5) to (5,5,-5) in world space
- float3 viewPos = (float3)(10*(x/(float)width)-5,
- 10*(y/(float)height)-5, -5);
-
- // start tracing a ray from the eye
- float3 ray = eyePos;
-
- // unit length ray from eye into world
- float3 rayDirection = normalize(viewPos-eyePos);
The ray trace method itself was inspired by that of the subblue renderer [19]. The estimated distance to the Mandelbox is used as the amount to increase the length of the ray step — eventually, either the ray intersects the object, or misses it entirely after exceeding a fixed step count.
- float rayLength = 0;
- const float EPSILON = 1.0E-6f;
- float eps = EPSILON;
- bool intersected = false;
- DEInfo dei;
-
- for (int i = 0; i < maxSteps; ++i) {
- dei = DistanceEstimation(ray, scale);
- ray += rayDirection*dei.distance;
- rayLength += dei.distance;
-
- if (rayLength > maxRayLength)
- break; // exceeded max ray length
- if (dei.distance < eps) {
- intersected = true; // hit the Mandelbox
- break;
- }
-
- // pixel scale of 1/1024
- eps = max(EPSILON, (1.0f / 1024)*rayLength);
- }
If the ray did not intersect the object, the image pixel corresponding to the traced ray is set to be transparent by setting its alpha channel to 0. If the object was intersected, a standard lighting calculation is performed by using the dot product between the surface normal and the vector to the light source to determine the light intensity.
- // background is black, and alpha 0 (transparent)
- uint4 pixelColor = 0;
- if (intersected) {
- // normal at the intersection point
- float3 N = Normal(ray, eps/2, scale);
-
- // compute color (single white light source of intensity 1)
- float3 L = normalize(lightPos-ray);
- float NdotL = dot(N, L);
- float3 diffuse = 0;
- if (NdotL > 0)
- diffuse = dei.color * NdotL;
-
- float3 color = clamp(diffuse + ambient, 0, 1);
-
- // TGA is bgr order, so reverse x (r) and z (b)
- pixelColor = (uint4)((uint)(color.z * 255), (uint)(color.y * 255),
- (uint)(color.x * 255), 255);
- }
Finally, write the pixel's color to the appropriate position in the image with the OpenCL function write_imageui(), as determined by the indices determined by get_global_id().
write_imageui(dest_img, (int2)(x,y), pixelColor);
}Test
In order to test performance, the Mand application was created to execute the kernel code as C++, using OpenMP for parallelization. The files GPUSupport.h and GPUSupport.cpp implement types such as float3 and int2 as C++ classes, as well as provide implementations of the built-in functions such as length(), clamp() and normalize().
The file Mandelbox.cpp encapsulates the rendering code. It begins by including GPUSupport.h.
- // Mandelbox.cpp
- #include <iostream>
- #include "GPUSupport.h"
OpenMP's threadprivate attribute is used to mark the global_id array for thread local storage — that is, each OpenMP thread receives its own copy of the array. get_global_id() is implemented as a macro that returns the appropriate array element for the requested dimension. The global_size array does not change across threads, so each thread does not require its own copy.
- int global_id[3], global_size[3];
- #pragma omp threadprivate(global_id)
-
- #define get_global_id(x) global_id[x]
- #define get_global_size(x) global_size[x]
The contents of Mandelbox.cl follow, only with structures such as:
__constant float3 eyePos = (float3)(0.0f, 0.0f, -15.0f);changed to:
__constant float3 eyePos = float3(0.0f, 0.0f, -15.0f);as, unless C++ constructor syntax is used, C++ interprets the values in parenthesis as the evaluation of a comma expression, rather than as parameters to initialize an object. The Mandelbox() function is driven by Render() inside of a loop parallelized by OpenMP. With this code, all three CPU cores are fully engaged. Status is displayed to the user every 100 rows to indicate that the rendering is proceeding, as image generation can take a considerable amount of time.
- void Render(image2d_t img, int width, int height, float scale) {
- global_size[0] = width;
- global_size[1] = height;
- #pragma omp parallel for schedule(dynamic)
- for (int y=0; y<height; y++) {
- global_id[1] = y;
- if (y%100 == 0)
- std::cout << y << std::endl;
- for (int x=0; x<width; x++) {
- global_id[0] = x;
- Mandelbox(scale, img);
- }
- }
- }
The code in main() has the same behavior as the OpenCL version — the image size is supplied on the command line, the call to Render() is timed, and the image is written to disk.
- // Mand.cpp
- #include <iostream>
- #include <omp.h>
- #include "GPUSupport.h"
- #include "TGA.h"
-
- void Render(image2d_t img, int width, int height, float scale);
-
- int main(int argc, char *argv[]) {
- int width = 512;
- if (argc>=2)
- width = atoi(argv[1]);
- int height = width;
- image2d img(width, height);
-
- double startTime = omp_get_wtime();
- Render(img, width, height, 3.0f);
- double endTime = omp_get_wtime()-startTime;
-
- WriteTGA("test.tga", width, height, img.Ptr());
- std::cout << "Calculation time: " << endTime << std::endl;
- }
Both the OpenCL and C++ versions produce the same image:

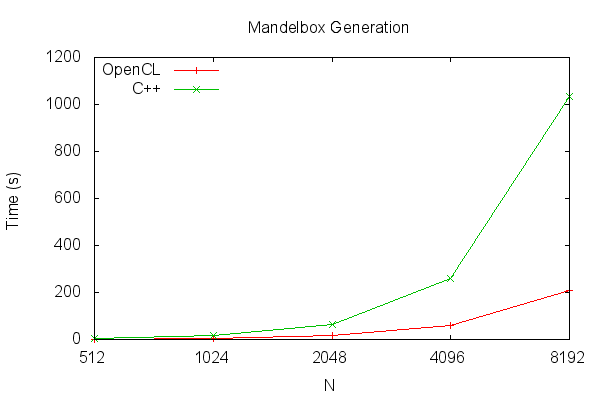
As shown in the table, the C++ version runs significantly slower. Even though the Pavilion contains a low-end graphics card, the GPU version of the application performs as much as five times faster than when all three cores of the main CPU combined are used. Performing the same test on a high-end graphics card would be an interesting exercise.
| N | OpenCL | C++ |
|---|---|---|
| 512 | 1.36 | 4.05 |
| 1024 | 5.15 | 16.31 |
| 2048 | 17.29 | 65.03 |
| 4096 | 58.22 | 258.57 |
| 8192 | 206.66 | 1034.53 |
Example 2 — Bitonic Sort
The bitonic sort algorithm is described in [10] and [17], though we will be using Thomas Christopher's implementation [18]. We will compare the performance of this algorithm as executed on the GPU and CPU, and against a traditional sequential sorting algorithm, by sorting an array of length N, for various sizes of N. To satisfy the algorithm, N must be a power of 2.
We begin, as before, by enabling exceptions and including relevant headers.
- // OCL_Sort.cpp
- #define __CL_ENABLE_EXCEPTIONS
-
- #include <iostream>
- #include <vector>
- #include <algorithm>
- #include <exception>
- #include <string>
- #include <omp.h>
- #include <CL/cl.hpp>
We define several functions, each representing a sort algorithm, and returning the elapsed execution time. The first is SortSTL(), which calls std::sort(). std::sort() is implemented in Visual Studio 2010 by quicksort, heap sort or insertion sort, depending upon the number of elements to be sorted.
- double SortSTL(int *a, int N) {
- double start = omp_get_wtime();
- std::sort(a, a+N);
- return omp_get_wtime()-start;
- }
SortOMP() implements the bitonic sort algorithm, but parallelizes it using OpenMP. A thread count is provided so the number of threads used can be controlled. The inner loop is parallelized, which is equivalent to the manner in which the kernel will be invoked by OpenCL.
- double SortOMP(int *a, int N, int numThreads) {
- double start = omp_get_wtime();
-
- int i,j,k, t;
- for (k=2; k<=N; k=2*k) {
- for (j=k>>1; j>0; j=j>>1) {
- #pragma omp parallel for num_threads(numThreads)
- for (i=0; i<N; i++) {
- int ixj=i^j;
- if (ixj>i) {
- if ((i&k)==0 && a[i]>a[ixj])
- { t=a[i]; a[i]=a[ixj]; a[ixj]=t; }
- if ((i&k)!=0 && a[i]<a[ixj])
- { t=a[i]; a[i]=a[ixj]; a[ixj]=t; }
- }
- }
- }
- }
-
- return omp_get_wtime()-start;
- }
SortOpenCL() invokes the kernel code on a supplied command queue. If the kernel is to be executed on a CPU device (isCPU is true), then the original array to be sorted can be used as an OpenCL buffer by setting the CL_MEM_USE_HOST_PTR flag. Otherwise, a buffer created in GPU-accessible memory must be created, and the array copied into it, as host memory cannot be directly accessed. This is indicated by the CL_MEM_COPY_HOST_PTR flag. Similarly, at the completion of the sort, the OpenCL buffer must be copied back to the host if a GPU device is used.
As the kernel is short, we embed it directly as a string, rather than as an external file that must be loaded. The first parameter to the kernel, the one dimensional array to sort, is passed somewhat differently than the 2D image buffer was in the previous example — it is expressed as a pointer, but it is marked with the __global specifier, as the memory it points to is allocated in the OpenCL global memory space.
Only the functionality of the innermost loop of the algorithm is implemented as a kernel. Global synchronization across all work items is not implemented in the OpenCL specification at this time [12, p.29], which is needed to ensure a pass of the algorithm is complete before the next one starts. Synchronization is performed by allowing the kernel function to complete, and then re-running the kernel, with modified arguments, for the next pass.
- const char *source =
- "__kernel void sort(__global int *a, int k, int j) \n"
- "{ \n"
- " int i = get_global_id(0); \n"
- " int ixj=i^j; \n"
- " int t; \n"
- " if (ixj>i) { \n"
- " if ((i&k)==0 && a[i]>a[ixj]) \n"
- " { t=a[i]; a[i]=a[ixj]; a[ixj]=t; } \n"
- " if ((i&k)!=0 && a[i]<a[ixj]) \n"
- " { t=a[i]; a[i]=a[ixj]; a[ixj]=t; } \n"
- " } \n"
- "}
-
- double SortOpenCL(int *a, int N, bool isCPU, const cl::Context &context,
- cl::CommandQueue &queue, cl::Kernel &kernel) {
- cl::Buffer buffer = cl::Buffer(context,
- CL_MEM_READ_WRITE |
- (isCPU?CL_MEM_USE_HOST_PTR:CL_MEM_COPY_HOST_PTR),
- N*sizeof(cl_int), a);
-
- double start = omp_get_wtime();
- int j,k;
- kernel.setArg(0, buffer);
- for (k=2; k<=N; k=2*k) {
- kernel.setArg(1, k);
- for (j=k>>1; j>0; j=j>>1) {
- kernel.setArg(2, j);
- queue.enqueueNDRangeKernel(kernel, cl::NDRange(),
- cl::NDRange(N), cl::NDRange());
- queue.finish();
- }
- }
-
- if (!isCPU) {
- cl_int *ptr = (cl_int *)queue.enqueueMapBuffer(buffer, CL_TRUE,
- CL_MAP_READ, 0, N*sizeof(cl_int));
- // not part of the sort itself, but counted in timing as we
- // are viewing it as an in-place sort
- memcpy(a, ptr, N*sizeof(cl_int));
- }
-
- return omp_get_wtime()-start;
- }
We wish to ensure that the sort was performed correctly. assert_sort() throws an exception if the array to be tested is not in sorted order.
- void assert_sort(const std::string msg, const std::vector<int> &expected,
- const std::vector<int> &actual) {
- if (expected != actual)
- throw std::exception(("Sort " + msg + " failed").c_str());
- }
SortTest(), for a given array length, creates an array of random elements (with a fixed random number generator seed, so the sequence is identical for a given N), sorts it using the various algorithms, and displays the elapsed times in CSV format.
- void SortTest(bool &first, int N,
- const cl::Context &cpuContext, cl::CommandQueue &cpuQueue,
- cl::Kernel &cpuKernel,
- const cl::Context &gpuContext, cl::CommandQueue &gpuQueue,
- cl::Kernel &gpuKernel) {
- std::vector<int> unsorted;
- unsorted.resize(N);
- std::srand(0);
- for (int i=0; i<N; i++)
- unsorted[i] = std::rand();
- std::vector<int> sorted(unsorted.begin(), unsorted.end());
- std::sort(sorted.begin(), sorted.end());
-
- // single-threaded STL sort
- std::vector<int> a(unsorted.begin(), unsorted.end());
- double sortSTLTime = SortSTL(&a[0], a.size());
- assert_sort("SortSTL", sorted, a);
-
- // single-threaded OpenMP bitonic sort
- std::copy(unsorted.begin(), unsorted.end(), a.begin());
- double sortOMP1Time = SortOMP(&a[0], a.size(), 1);
- assert_sort("SortOMP1", sorted, a);
-
- // multi-threaded OpenMP bitonic sort
- std::copy(unsorted.begin(), unsorted.end(), a.begin());
- double sortOMPNTime = SortOMP(&a[0], a.size(), omp_get_max_threads());
- assert_sort("SortOMPN", sorted, a);
-
- // OpenCL with CPU device
- std::copy(unsorted.begin(), unsorted.end(), a.begin());
- double sortOpenCLCPUTime = SortOpenCL(&a[0], a.size(), true,
- cpuContext, cpuQueue, cpuKernel);
- assert_sort("SortOpenCLCPU", sorted, a);
-
- // OpenCL with GPU device
- std::copy(unsorted.begin(), unsorted.end(), a.begin());
- double sortOpenCLGPUTime = SortOpenCL(&a[0], a.size(), false,
- gpuContext, gpuQueue, gpuKernel);
- assert_sort("SortOpenCLGPU", sorted, a);
-
- if (first) {
- std::cout <<
- "\"N\",\"STL\",\"OMP1\",\"OMPN\",\"OpenCLCPU\",\"OpenCLGPU\""
- << std::endl;
- first = false;
- }
- std::cout << N << "," << sortSTLTime << "," << sortOMP1Time
- << "," << sortOMPNTime << "," << sortOpenCLCPUTime << ","
- << sortOpenCLGPUTime <<
- std::endl;
- }
GetOpenCLObjects() is very similar to the process in the first example of obtaining a device, queue, and kernel, although here the type of device desired is passed as a parameter, rather than being hard-coded to be a GPU device.
- void GetOpenCLObjects(std::vector<cl::Platform> &platforms,
- cl_device_type type, cl::Context &context, cl::CommandQueue &queue,
- cl::Kernel &kernel) {
- // create context and queue
- cl_context_properties cprops[3] = { CL_CONTEXT_PLATFORM,
- (cl_context_properties)platforms[0](), 0 };
- context = cl::Context(type, cprops);
- std::vector<cl::Device> devices =
- context.getInfo<CL_CONTEXT_DEVICES>();
- if (devices.size() == 0)
- throw std::exception("Device not available");
- queue = cl::CommandQueue(context, devices[0]);
-
- // compile source, get kernel entry point
- cl::Program program;
- try {
- cl::Program::Sources sources(1,
- std::make_pair(source, strlen(source)));
- program = cl::Program(context, sources);
- program.build(devices);
- kernel = cl::Kernel(program, "sort");
- } catch (cl::Error &err) {
- // if it was a compilation error
- if (err.err() == CL_BUILD_PROGRAM_FAILURE)
- std::cout <<
- program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(devices[0])
- << std::endl;
- throw;
- }
- }
Finally, main() drives the test sequence. Both OpenCL CPU and GPU devices are created, and passed to SortTest(). Arrays of length 220 to 225 are sorted. Arrays of smaller size are sorted in less than a second so are not profitable to profile, and a buffer size of 226 or higher is too large for the GPU to create — clCreateBuffer(), as called by cl::Buffer(), returns CL_INVALID_BUFFER_SIZE on the Mobility Radeon hardware.
- int main() {
- try {
- std::vector<cl::Platform> platforms;
- cl::Platform::get(&platforms);
- if (platforms.size() == 0)
- throw std::exception("OpenCL not available");
-
- cl::Context cpuContext, gpuContext;
- cl::CommandQueue cpuQueue, gpuQueue;
- cl::Kernel cpuKernel, gpuKernel;
- GetOpenCLObjects(platforms, CL_DEVICE_TYPE_CPU, cpuContext,
- cpuQueue, cpuKernel);
- GetOpenCLObjects(platforms, CL_DEVICE_TYPE_GPU, gpuContext,
- gpuQueue, gpuKernel);
-
- bool first = true;
- for (int b=20; b<=25; b++)
- SortTest(first, 1<<b,
- cpuContext, cpuQueue, cpuKernel,
- gpuContext, gpuQueue, gpuKernel);
- } catch (cl::Error &err) {
- std::cout << "Error: " << err.what() << "(" << err.err() << ")"
- << std:: endl;
- } catch (std::exception &e) {
- std::cout << "Exception: " << e.what() << std::endl;
- }
-
- return 0;
- }
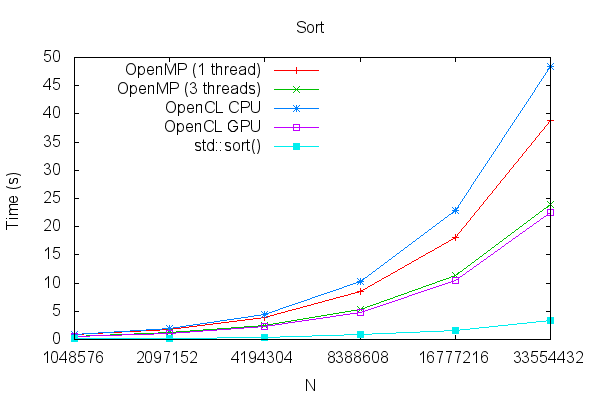
The results are shown here. The OpenCL kernel running on the CPU device was the slowest of all, but the same code on the GPU device performed the best of the bitonic sort variants. The OpenMP variation, using all CPUs, was not far behind. The fastest sort, however, was std::sort(), which demonstrates that the selection of the best algorithm may not be intuitive — for this problem size and platform, against conventional wisdom, a parallel algorithm was not faster than a sequential one. A slower CPU, or faster GPU, may have produced the opposite result.
| N | OpenMP (1 thread) | OpenMP (3 threads) | OpenCL CPU | OpenCL GPU | std::sort() |
|---|---|---|---|---|---|
| 1048576 | 0.84 | 0.57 | 0.90 | 0.57 | 0.11 |
| 2097152 | 1.82 | 1.20 | 1.97 | 1.11 | 0.21 |
| 4194304 | 3.93 | 2.55 | 4.44 | 2.28 | 0.42 |
| 8388608 | 8.46 | 5.36 | 10.36 | 4.85 | 0.83 |
| 16777216 | 18.12 | 11.42 | 22.90 | 10.50 | 1.64 |
| 33554432 | 38.78 | 23.95 | 48.34 | 22.53 | 3.29 |
Summary
In this article, we have shown how to use OpenCL to implement general purpose computations on graphics card GPUs. While performance, even on low-end cards, can be significant, care must be taken to ensure that the most appropriate algorithm is selected to solve the problem at hand.
References
- [1] GeForce 3 Series
http://en.wikipedia.org/wiki/GeForce_3_series - [2] GPGPU Applications
http://en.wikipedia.org/wiki/GPGPU#Applications - [3] Tsuchiyama, et al. The OpenCL Programming Book, Parallel Programming for MultiCore CPU and GPU, Fixstars Corporation, 2010
http://www.amazon.com/The-OpenCL-Programming-Book-ebook/dp/B003H4QYHE/ref=sr_1_1?ie=UTF8&qid=1308143362&sr=8-1 - [4] CUDA Parallel Programming Made Easy
http://www.nvidia.com/object/cuda_home_new.html - [5] CUDA
http://en.wikipedia.org/wiki/CUDA - [6] DirectCompute Lecture Series 101: Introduction to DirectCompute
http://channel9.msdn.com/Blogs/gclassy/DirectCompute-Lecture-Series-101-Introduction-to-DirectCompute - [7] OpenCL Overview
http://www.khronos.org/opencl/ - [8] OpenCL
http://en.wikipedia.org/wiki/OpenCL - [9] ATI Mobility Radeon HD 5470
http://www.notebookcheck.net/ATI-Mobility-Radeon-HD-5470.23698.0.html - [10] AMD APP SDK Downloads
http://developer.amd.com/sdks/AMDAPPSDK/downloads/Pages/default.aspx - [11] APP SDK 2.4 OpenCL version problem
http://forums.amd.com/forum/messageview.cfm?catid=390&threadid=150504&forumid=9 - [12] Munshi, The OpenCL Specification, Version 1.1, Khronos OpenCL Working Group, 9/30/2010
http://www.khronos.org/registry/cl/specs/opencl-1.1.pdf - [13] Gaster, The OpenCL C++ Wrapper API, Version 1.1, Khronos OpenCL Working Group, 6/14/2010
http://www.khronos.org/registry/cl/specs/opencl-cplusplus-1.1.pdf - [14] What is a Mandelbox
http://sites.google.com/site/mandelbox/what-is-a-mandelbox - [15] Truevision TGA
http://en.wikipedia.org/wiki/Truevision_TGA - [16] Re: A Mandelbox distance estimate formula
http://www.fractalforums.com/3d-fractal-generation/a-mandelbox-distance-estimate-formula/msg14893/#msg14893 - [17] Bitonic sort
http://www.inf.fh-flensburg.de/lang/algorithmen/sortieren/bitonic/bitonicen.htm - [18] Bitonic Sort
http://www.tools-of-computing.com/tc/CS/Sorts/bitonic_sort.htm - [19] 3D Mandelbulb Ray Tracer
http://www.subblue.com/projects/mandelbulb
