Introduction to the Java Speech API
By Nathan Tippy, OCI Senior Software Engineer
March 2006
Speech Synthesis
Speech synthesis, also known as text-to-speech (TTS) conversion, is the process of converting text into human recognizable speech based on language and other vocal requirements. Speech synthesis can be used to enhance the user experience in many situations but care must be taken to ensure the user is comfortable with its use.
Speech synthesis has proven to be a great benefit in many ways. It is often used to assist the visually impaired as well as provide safety and efficiency in situations where the user needs to keep his eyes focused elsewhere. In the most successful applications of speech synthesis it is often central to the product requirements. If it is added on as an afterthought or a novelty it is rarely appreciated; people have high expectations when it comes to speech.
Natural sounding speech synthesis has been the goal of many development teams for a long time, yet it remains a significant challenge. People learn to speak at a very young age and continue to use their speaking and listening skills over the course of their lives, so it is very easy for people to recognize even the most minor flaws in speech synthesis.
As humans it is easy to take for granted our ability to speak but it is really a very complex process. There are a few different ways to implement a speech synthesis engine but in general they all complete the following steps:

There are many voices available to developers today. Most of them are very good and a few are quite exceptional in how natural they sound. I put together a collection of both commercial and non-commercial voices so you can listen to them without having to setup or install anything.
Unfortunately the best voices (as of the time of this writing) are commercial so works produced using them can not be re-distributed without fees. Depending on how many voices you use and what you are using them for the annual costs for distribution rights can run from hundreds to thousands each year. Many vendors also provide different fee schedules for distributing applications that use a voice verses audio files and/or streams produced from the voices.
Java Speech API (JSAPI)
The goal of JSAPI is to enable cross-platform development of voice applications. The JSAPI enables developers to write applications that do not depend on the proprietary features of one platform or one speech engine.
Decoupling the engine from the application is important. As you can hear from the voice demo page; there is a wide variety of voices with different characteristics. Some users will be comfortable with a deep male voice while others may be more comfortable with a British female voice. The choice of speech engine and voice is subjective and may be expensive. In most cases, end users will use a single speech engine for multiple applications so they will expect any new speech enabled applications to integrate easily.
The Java Speech API 1.0 was first released by Sun in 1998 and defines packages for both speech recognition and speech synthesis. In order to remain brief the remainder of the article will focus on the speech synthesis package but if you would like to know more about speech recognition visit the CMU Sphinx sourceforge.net project.
All the JSAPI implementations available today are compliant with 1.0 or a subset of 1.0 but work is progressing on version 2.0 (JSR113) of the API. We will be using the open source implementation from FreeTTS for our demo app but there are other implementations such as the one from Cloudscape which provides support for the SAPI5 voices that Microsoft Windows uses.
Important Classes and Interfaces
Class: javax.speech.Central
This singleton class is the main interface for access to the speech engine facilities. It has a bad name (much too generic) but as part of the upgrade to version 2.0 they will be renaming it to EngineManager which is a much better name based on what it does.
For our example, we will only use the availableSynthesizers and createSynthesizer methods. Both of these methods need a mode description which is the next class we will use.
Class: javax.speech.synthesis.SynthesiserModeDesc
This simple bean holds all the required properties of the Synthesizer. When requesting a specific Synthesizer or a list of available Synthesizers this object can be passed in with specific properties to restrict the results to Synthesizers matching the defined properties only. The list of properties include the engine name, mode name, locale and running synthesizer.
The mode name property is not implemented with a type safe enumeration and it should only be set to the string value 'general' or 'time' when using the FreeTTS implementation. The mode name is specific to the engine, and in this case restricts the synthesizer to those that can speak any text or those that can only speak the time. If a time-only synthesizer is used for reading general text it will attempt to read it and print error messages when those phonemes it can't pronounce are encountered.
The locale property can be used to restrict international synthesizers which have support for many languages. See the MBROLA project for some international examples.
The running synthesizer property is used to limit the synthesizers returned to only those that are already loaded into memory. Because some synthesizers can take a long time to load into memory this feature may be helpful in limiting runtime delays.
Class: javax.speech.synthesis.Synthesiser
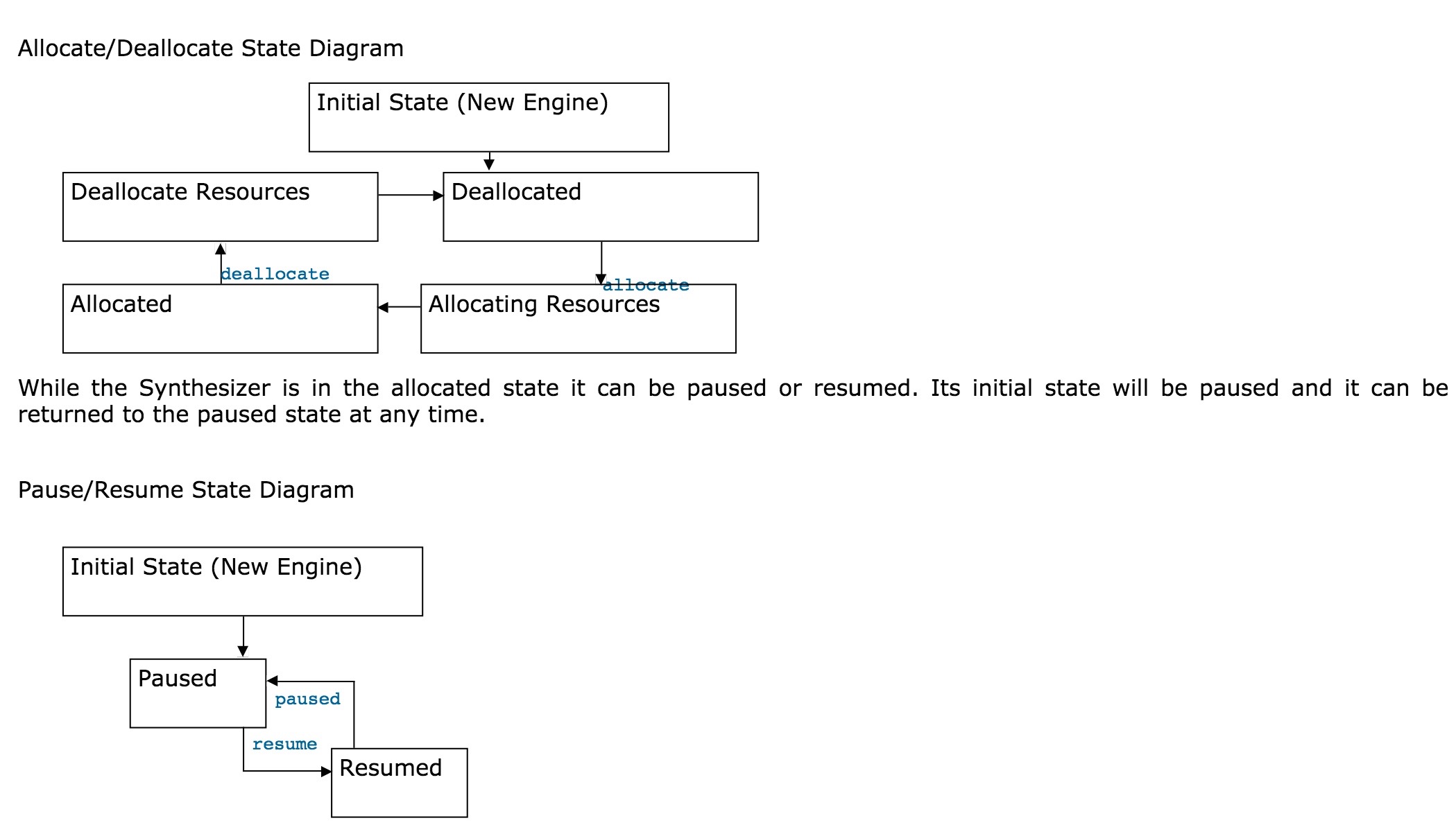
This class is used for converting text into speech using the selected voice. Synthesizers must be allocated before they can be used and this may take some time if high quality voices are supported which make use of large data files. It is recommended that the allocate method is called upon startup from a background thread. Call deallocate only when the application is about to exit. Once you have an allocated synthesizer it can be kept for the life of the application. Please note, in the chart below, the allocating and deallocating states that the synthesizer will be in while completing the allocate and deallocate operations, respectively.
Class: javax.speech.synthesis.Voice
This simple bean holds the properties of the voice. The name, age and gender can be set along with a Boolean to indicate that only voices already loaded into memory should be used. The setVoice method uses these properties to select a voice matching the required properties. After a voice is selected the getVoice method can be called to get the properties of the voice currently being used.
Note that the age and gender parameters are integers and do not use a typesafe enumeration. If an invalid value is used a PropertyVetoException will be thrown. The valid constants for these fields are found on the Voice class and they are.
Voice.GENDER_DONT_CARE
Voice.GENDER_FEMALE
Voice.GENDER_MALE
Voice.GENDER_NUTRAL
Voice.AGE_DONT_CARE
Voice.AGE_CHILD
Voice.AGE_TEENAGER
Voice.AGE_YOUNGER_ADULT
Voice.AGE_MIDDLE_ADULT
Voice.AGE_OLDER_ADULT
Voice.AGE_NEUTRALInterface: javax.speech.synthesis.Speakable
This interface should be implemented by any object that will produce marked up text that is to be spoken. The specification for JSML can be found on line and is very similar to W3Cs Speech Synthesis Markup Language Specification (SSML) which will be used instead of JSML for the 2.0 release.
Interface: javax.speech.synthesis.SpeakableListener
This interface should be implemented by any object wishing to listen to speech events. Notifications for events such as starting, stopping, pausing, resuming and others can be used to keep the application in sync with what the speech engine is doing.
Hello World
To try the demo you will need to set up the following:
Download freetts-1.2.1-bin.zip from http://sourceforge.net/projects/freetts/
FreeTTS only supports a subset of 1.0 but it works well and has an easy-to-understand voice. Our JSML inflections will be ignored but the markup will be parsed correctly.
Unzip the freetts-1.2.1-bin.zip file to a local folder.
The D:\apps\ folder will be used for this example
Go to D:\apps\freetts-1.2.1\lib and run jsapi.exe
This will create the jsapi.jar from Sun Microsystems. This is done because it uses a different license than FreeTTS's BSD license.
Add this new jar and all the other jars found in the D:\apps\freetts-1.2.1\lib folder to your path. This will give us the engine, the JSAPI interfaces and three voices to use in our demo.
Copy the D:\apps\freetts-1.2.1\speech.properties file to your %user.home% or %java.home%/lib folders. This file is used by JSAPI to determine which speech engine will be used.
Compile the three demo files below and run BriefVoiceDemo from the command line.
BriefVoiceDemo.java
- package com.ociweb.jsapi;
-
- import java.beans.PropertyVetoException;
- import java.io.File;
- import java.text.DateFormat;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- import java.util.Locale;
-
- import javax.speech.AudioException;
- import javax.speech.Central;
- import javax.speech.EngineException;
- import javax.speech.EngineList;
- import javax.speech.EngineModeDesc;
- import javax.speech.EngineStateError;
- import javax.speech.synthesis.JSMLException;
- import javax.speech.synthesis.Speakable;
- import javax.speech.synthesis.SpeakableListener;
- import javax.speech.synthesis.Synthesizer;
- import javax.speech.synthesis.SynthesizerModeDesc;
- import javax.speech.synthesis.Voice;
-
- public class BriefVoiceDemo {
-
- Synthesizer synthesizer;
-
- public static void main(String[] args) {
-
- //default synthesizer values
- SynthesizerModeDesc modeDesc = new SynthesizerModeDesc(
- null, // engine name
- "general", // mode name use 'general' or 'time'
- Locale.US, // locale, see MBROLA Project for i18n examples
- null, // prefer a running synthesizer (Boolean)
- null); // preload these voices (Voice[])
-
- //default voice values
- Voice voice = new Voice(
- "kevin16", //name for this voice
- Voice.AGE_DONT_CARE, //age for this voice
- Voice.GENDER_DONT_CARE,//gender for this voice
- null); //prefer a running voice (Boolean)
-
- boolean error=false;
- for (int r=0;r<args.length;r++) {
- String token= args[r];
- String value= token.substring(2);
-
- //overide some of the default synthesizer values
- if (token.startsWith("-E")) {
- modeDesc.setEngineName(value);
- } else if (token.startsWith("-M")) {
- modeDesc.setModeName(value);
- } else
- //overide some of the default voice values
- if (token.startsWith("-V")) {
- voice.setName(value);
- } else if (token.startsWith("-GF")) {
- voice.setGender(Voice.GENDER_FEMALE);
- } else if (token.startsWith("-GM")) {
- voice.setGender(Voice.GENDER_MALE);
- } else
- //dont recognize this value so flag it and break out
- {
- System.out.println(token+
- " was not recognized as a supported parameter");
- error = true;
- break;
- }
- }
-
- //The example starts here
- BriefVoiceDemo briefExample = new BriefVoiceDemo();
- if (error) {
- System.out.println("BriefVoiceDemo -E<ENGINENAME> " +
- "-M<time|general> -V<VOICENAME> -GF -GM");
- //list all the available voices for the user
- briefExample.listAllVoices();
- System.exit(1);
- }
-
- //select synthesizer by the required parameters
- briefExample.createSynthesizer(modeDesc);
- //print the details of the selected synthesizer
- briefExample.printSelectedSynthesizerModeDesc();
-
- //allocate all the resources needed by the synthesizer
- briefExample.allocateSynthesizer();
-
- //change the synthesisers state from PAUSED to RESUME
- briefExample.resumeSynthesizer();
-
- //set the voice
- briefExample.selectVoice(voice);
- //print the details of the selected voice
- briefExample.printSelectedVoice();
-
- //create a listener to be notified of speech events.
- SpeakableListener optionalListener= new BriefListener();
-
- //The Date and Time can be spoken by any of the selected voices
- SimpleDateFormat formatter = new SimpleDateFormat("h mm");
- String dateText = "The time is now " + formatter.format(new Date());
- briefExample.speakTextSynchronously(dateText, optionalListener);
-
- //General text like this can only be spoken by general voices
- if (briefExample.isModeGeneral()) {
- //speak plain text
- String plainText =
- "Hello World, This is an example of plain text," +
- " any markup like <jsml></jsml> will be spoken as is";
- briefExample.speakTextSynchronously(plainText, optionalListener);
-
- //speak marked-up text from Speakable object
- Speakable speakableExample = new BriefSpeakable();
- briefExample.speakSpeakableSynchronously(speakableExample,
- optionalListener);
- }
- //must deallocate the synthesizer before leaving
- briefExample.deallocateSynthesizer();
- }
-
- /**
- * Select voice supported by this synthesizer that matches the required
- * properties found in the voice object. If no matching voice can be
- * found the call is ignored and the previous or default voice will be used.
- *
- * @param voice required voice properties.
- */
- private void selectVoice(Voice voice) {
- try {
- synthesizer.getSynthesizerProperties().setVoice(voice);
- } catch (PropertyVetoException e) {
- System.out.println("unsupported voice");
- exit(e);
- }
- }
-
- /**
- * This method prepares the synthesizer for speech by moving it from the
- * PAUSED state to the RESUMED state. This is needed because all newly
- * created synthesizers start in the PAUSED state.
- * See Pause/Resume state diagram.
- *
- * The pauseSynthesizer method is not shown but looks like you would expect
- * and can be used to pause any speech in process.
- */
- private void resumeSynthesizer() {
- try {
- //leave the PAUSED state, see state diagram
- synthesizer.resume();
- } catch (AudioException e) {
- exit(e);
- }
- }
-
- /**
- * The allocate method may take significant time to return depending on the
- * size and capabilities of the selected synthesizer. In a production
- * application this would probably be done on startup with a background thread.
- *
- * This method moves the synthesizer from the DEALLOCATED state to the
- * ALLOCATING RESOURCES state and returns only after entering the ALLOCATED
- * state. See Allocate/Deallocate state diagram.
- */
- private void allocateSynthesizer() {
- //ensure that we only do this when in the DEALLOCATED state
- if ((synthesizer.getEngineState()&Synthesizer.DEALLOCATED)!=0)
- {
- try {
- //this call may take significant time
-
- synthesizer.getEngineState();
- synthesizer.allocate();
- } catch (EngineException e) {
- e.printStackTrace();
- System.exit(1);
- } catch (EngineStateError e) {
- e.printStackTrace();
- System.exit(1);
- }
- }
- }
-
- /**
- * deallocate the synthesizer. This must be done before exiting or
- * you will run the risk of having a resource leak.
- *
- * This method moves the synthesizer from the ALLOCATED state to the
- * DEALLOCATING RESOURCES state and returns only after entering the
- * DEALLOCATED state. See Allocate/Deallocate state diagram.
- */
- private void deallocateSynthesizer() {
- //ensure that we only do this when in the ALLOCATED state
- if ((synthesizer.getEngineState()&Synthesizer.ALLOCATED)!=0)
- {
- try {
- //free all the resources used by the synthesizer
- synthesizer.deallocate();
- } catch (EngineException e) {
- e.printStackTrace();
- System.exit(1);
- } catch (EngineStateError e) {
- e.printStackTrace();
- System.exit(1);
- }
- }
- }
-
- /**
- * Helper method to ensure the synthesizer is always deallocated before
- * existing the VM. The synthesiser may be holding substantial native
- * resources that must be explicitly released.
- *
- * @param e exception to print before exiting.
- */
- private void exit(Exception e) {
- e.printStackTrace();
- deallocateSynthesizer();
- System.exit(1);
- }
-
- /**
- * create a synthesiser with the required properties. The Central class
- * requires the speech.properties file to be in the user.home or the
- * java.home/lib folders before it can create a synthesizer.
- *
- * @param modeDesc required properties for the created synthesizer
- */
- private void createSynthesizer(SynthesizerModeDesc modeDesc) {
- try {
- //Create a Synthesizer with specified required properties.
- //if none can be found null is returned.
- synthesizer = Central.createSynthesizer(modeDesc);
- }
- catch (IllegalArgumentException e1) {
- e1.printStackTrace();
- System.exit(1);
- } catch (EngineException e1) {
- e1.printStackTrace();
- System.exit(1);
- }
-
- if (synthesizer==null) {
- System.out.println("Unable to create synthesizer with " +
- "the required properties");
- System.out.println();
- System.out.println("Be sure to check that the \"speech.properties\"" +
- " file is in one of these locations:");
- System.out.println(" user.home : "+System.getProperty("user.home"));
- System.out.println(" java.home/lib : "+System.getProperty("java.home")
- +File.separator+"lib");
- System.out.println();
- System.exit(1);
- }
- }
-
- /**
- * is the selected synthesizer capable of speaking general text
- * @return is Mode General
- */
- private boolean isModeGeneral() {
- String mode=this.synthesizer.getEngineModeDesc().getModeName();
- return "general".equals(mode);
- }
-
- /**
- * Speak the marked-up text provided by the Speakable object and wait for
- * synthesisers queue to empty. Support for specific markup tags is
- * dependent upon the selected synthesizer. The text will be read as
- * though the mark up was not present if unsuppored tags are encounterd by
- * the selected synthesizer.
- *
- * @param speakable
- * @param optionalListener
- */
- private void speakSpeakableSynchronously(
- Speakable speakable,
- SpeakableListener optionalListener) {
-
- try {
- this.synthesizer.speak(speakable, optionalListener);
- } catch (JSMLException e) {
- exit(e);
- }
-
- try {
- //wait for the queue to empty
- this.synthesizer.waitEngineState(Synthesizer.QUEUE_EMPTY);
-
- } catch (IllegalArgumentException e) {
- exit(e);
- } catch (InterruptedException e) {
- exit(e);
- }
- }
-
-
-
- /**
- * Speak plain text 'as is' and wait until the synthesizer queue is empty
- *
- * @param plainText that will be spoken ignoring any markup
- * @param optionalListener will be notified of voice events
- */
- private void speakTextSynchronously(String plainText,
- SpeakableListener optionalListener) {
- this.synthesizer.speakPlainText(plainText, optionalListener);
- try {
- //wait for the queue to empty
- this.synthesizer.waitEngineState(Synthesizer.QUEUE_EMPTY);
-
- } catch (IllegalArgumentException e) {
- exit(e);
- } catch (InterruptedException e) {
- exit(e);
- }
- }
-
- /**
- * Print all the properties of the selected voice
- */
- private void printSelectedVoice() {
-
- Voice voice = this.synthesizer.getSynthesizerProperties().getVoice();
- System.out.println();
- System.out.println("Selected Voice:"+voice.getName());
- System.out.println(" Style:"+voice.getStyle());
- System.out.println(" Gender:"+genderToString(voice.getGender()));
- System.out.println(" Age:"+ageToString(voice.getAge()));
- System.out.println();
- }
-
- /**
- * Helper method to convert gender constants to strings
- * @param gender as defined by the Voice constants
- * @return gender description
- */
- private String genderToString(int gender) {
- switch (gender) {
- case Voice.GENDER_FEMALE:
- return "Female";
- case Voice.GENDER_MALE:
- return "Male";
- case Voice.GENDER_NEUTRAL:
- return "Neutral";
- case Voice.GENDER_DONT_CARE:
- default:
- return "Unknown";
- }
- }
-
- /**
- * Helper method to convert age constants to strings
- * @param age as defined by the Voice constants
- * @return age description
- */
- private String ageToString(int age) {
- switch (age) {
- case Voice.AGE_CHILD:
- return "Child";
- case Voice.AGE_MIDDLE_ADULT:
- return "Middle Adult";
- case Voice.AGE_NEUTRAL:
- return "Neutral";
- case Voice.AGE_OLDER_ADULT:
- return "OlderAdult";
- case Voice.AGE_TEENAGER:
- return "Teenager";
- case Voice.AGE_YOUNGER_ADULT:
- return "Younger Adult";
- case Voice.AGE_DONT_CARE:
- default:
- return "Unknown";
- }
- }
-
- /**
- * Print all the properties of the selected synthesizer
- */
- private void printSelectedSynthesizerModeDesc() {
- EngineModeDesc description = this.synthesizer.getEngineModeDesc();
- System.out.println();
- System.out.println("Selected Synthesizer:"+description.getEngineName());
- System.out.println(" Mode:"+description.getModeName());
- System.out.println(" Locale:"+description.getLocale());
- System.out.println(" IsRunning:"+description.getRunning());
- System.out.println();
- }
-
- /**
- * List all the available synthesizers and voices.
- */
- public void listAllVoices() {
- System.out.println();
- System.out.println("All available JSAPI Synthesizers and Voices:");
-
- //Do not set any properties so all the synthesizers will be returned
- SynthesizerModeDesc emptyDesc = new SynthesizerModeDesc();
- EngineList engineList = Central.availableSynthesizers(emptyDesc);
- //loop over all the synthesizers
- for (int e = 0; e < engineList.size(); e++) {
- SynthesizerModeDesc desc = (SynthesizerModeDesc) engineList.get(e);
- //loop over all the voices for this synthesizer
- Voice[] voices = desc.getVoices();
- for (int v = 0; v < voices.length; v++) {
- System.out.println(
- desc.getEngineName()+
- " Voice:"+voices[v].getName()+
- " Gender:"+genderToString(voices[v].getGender()));
- }
- }
- System.out.println();
- }
- }
-
BriefSpeakable.java
- package com.ociweb.jsapi;
-
- import javax.speech.synthesis.Speakable;
-
- /**
- * Simple Speakable
- * Returns marked-up text to be spoken
- */
- public class BriefSpeakable implements Speakable {
-
- /**
- * Returns marked-up text. The markup is used to help the vice engine.
- */
- public String getJSMLText() {
- return "<jsml><para>This Speech <sayas class='literal'>API</sayas> " +
- "can integrate with <emp> most </emp> " +
- "of the speech engines on the market today.</para>" +
- "<break msecs='300'/><para>Keep on top of the latest developments " +
- "by reading all you can about " +
- "<sayas class='literal'>JSR113</sayas></para></jsml>";
- }
-
- /**
- * Implemented so the listener can print out the source
- */
- public String toString() {
- return getJSMLText();
- }
-
- }
BriefListener.java
- package com.ociweb.jsapi;
-
- import javax.speech.synthesis.SpeakableEvent;
- import javax.speech.synthesis.SpeakableListener;
-
- /**
- * Simple SpeakableListener
- * Prints event type and the source object's toString()
- */
- public class BriefListener implements SpeakableListener {
-
- private String formatEvent(SpeakableEvent event) {
- return event.paramString()+": "+event.getSource();
- }
-
- public void markerReached(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void speakableCancelled(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void speakableEnded(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void speakablePaused(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void speakableResumed(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void speakableStarted(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void topOfQueue(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
-
- public void wordStarted(SpeakableEvent event) {
- System.out.println(formatEvent(event));
- }
- }
Conclusion
Further work on version 2.0 continues under JSR 113. The primary goal of the upcoming 2.0 spec is to bring JSAPI to J2ME but a few other overdue changes like class renaming have been done as well.
My impression after using JSAPI is that it would be much easier to use if it implemented unchecked exceptions. This would help make the code much easier to read and implement. Overall I think the API is on the right track and adds a needed abstraction layer for any project using speech synthesis.
As computer performance continues to improve and Java becomes embedded in more devices, interfaces that make computers easier for non-technical people such as voice synthesis and recognition will become ubiquitous. I recommend that anyone who might be working with embedded Java in the future keep an eye on JSR113.
References
- [1] JSML
http://java.sun.com/products/java-media/speech/forDevelopers/JSML/ - [2] FreeTTS JSAPI setup
http://freetts.sourceforge.net/ - [3] JSAPI
http://java.sun.com/products/java-media/speech/news/index.html JSAPI Guide JSAPI JavaDoc Overview - [4] Diagrams
http://JavaNut.com/BlogDraw
