Project Coin: Small Changes in JDK 7
By Lance Finney, OCI Principal Software Engineer
May 2010
Introduction
In February 2009, Sun made an open call for small language changes that the Java™ development community would want to see in JDK 7. This set of changes is called Project Coin (based on the pun that coin means both "a piece of small change" and "to create a new language"). The idea was to solicit input for "5 or so" changes to the Java language from developers who will be involved in the implementation. The goal was to find safe, small, and useful changes on the scale of the Enhanced For Loop introduced in Java 5, not on the scale of Generics or closures.
Within a month, 70 proposals were submitted, and an open discussion on the coin-dev mailing list whittled the proposals down to a few that were compellingly useful without being risky.
This article is a description of the "5 or so" (actually 9 at this point) proposals that were accepted. Some of the changes have already been implemented in the JDK 7 codebase, but others are not yet available.
- Implemented Proposals
- Strings in Switch
- Improved Type Inference for Generic Instance Creation
- Binary Literals
- Underscores in numbers
- Language support for JSR 292
- Yet-To-Be-Implemented Proposals
- Automatic Resource Management
- Simplified Varargs Method Invocation
- Collection Literals
- Indexing access syntax for Lists and Maps
Implemented Proposals
Five of the nine proposals were implemented for milestone M5 in November 2009, so you can use them now. The remaining proposals are due to be implemented by the feature-complete milestone M8, to be released in June 2010.
Strings in Switch
When developers are learning about Java's syntax, many are surprised that Strings cannot be used as selectors in switch statements, only primitive literals can. With this proposal, we gain this ability.
- private static final String BAZ = "baz";
-
- private void stringSwitch() {
- final String bar = "bar";
- String key = "key";
- switch (key) {
- case "": {
- System.out.println("Nothing");
- break;
- }
- case "foo": // fallthrough works as before
- case bar: // local final variables are ok
- case BAZ: { // constants are ok
- System.out.println("Matched key");
- break;
- }
- default:
- break;
- }
- }
As with primitives, the case must still be a constant expression; the following will not compile:
- private void illegalStringSwitch() {
- String foo = "foo";
- String key = "key";
- switch (key) {
- case foo: // local non-final variables are illegal
- case getStringValue(): { // method calls are illegal
- System.out.println("illegal");
- break;
- }
- default:
- break;
- }
- }
-
- private String getStringValue() {
- return "";
- }
This feature is no longer as important as it once might have been; now that Java has enumerated datatypes, many of the situations in which this might have been useful before Java 5 can now be better served through a well-designed Enum.
Improved Type Inference for Generic Instance Creation
When Generics were added to Java, one nice feature was type inference: a developer often could skip specifying the type in the call to a method when the type is obvious from context. Unfortunately, this wasn't implemented for constructors:
- private void previousInference() {
- List<String> list1 = Arrays.asList("foo", "bar"); // inference
- List<String> list2 = Collections.emptyList(); // inference
- List<String> list3 = new ArrayList<String>(); // no inference
- }
Without inference, the right side of the first and second lines above would have been Arrays.(String)asList("foo", "bar") and Collections.(String)emptyList(), respectively. With inference, that verbosity is unnecessary because Java infers from the context that the type of the List is String (though technically, it is still optional and legal to include the type declaration). Unfortunately, that was not implemented for the last situation, which uses a constructor.
Because of this gap, many developers have created utility classes like com.google.common.collect.Lists to create objects without explicit type declarations:
- public class Lists {
- public static <E> List<E> newArrayList() {
- return new ArrayList<E>(); }
- public static <E> List<E> newArrayList(int i) {
- return new ArrayList<E>(i); }
- // ...
- }
- List<String> list = Lists.newArrayList();
Now, with the proposal implemented for Project Coin, com.google.common.collect.Lists is unnecessary, and the example can now be simplified to this:
- private void newInference() {
- List<String> list1 = Arrays.asList("foo", "bar"); // inference
- List<String> list2 = Collections.emptyList(); // inference
- List<String> list3 = new ArrayList<>(); // new inference
- }
"<>" is referred to as the diamond operator, used where Java can infer the type for a constructor (perhaps 90% of constructor type arguments, according to Project Coin leader Joseph Darcy). There was hope to be able to avoid the diamond operator completely, but eliminating it would have left no way to generate a raw ArrayList, and that would have broken backwards-compatibility.
This innovation does not seem very useful in the simple example above, but compare the following lines:
- private void compareInference() {
- AtomicReference<Map<String, List<Integer>>> ref1 =
- new AtomicReference<>();
- AtomicReference<Map<String, List<Integer>>> ref2 =
- new AtomicReference<Map<String, List<Integer>>>();
- }
This is exactly the type of change Project Coin was looking for: small, safe, and useful.
Binary Literals
How would you use Java to find the decimal value of the binary number 10100001? Unfortunately, the simplest way currently is this: int value = Integer.parseInt("10100001", 2). This approach has a number of problems:
- It's verbose
- It's slow
- It usually can't be inlined
- The binary value can't be used as a selector in a switch
- String parsing relies on runtime exceptions, not compile-time errors
JDK 7 will simplify this situation by adding a new form of specifying numeric literals. In addition to specifying one in decimal ("1"), octal ("01"), and hexadecimal ("0x1"), we can now specify it as a binary literal: "0b1". So, binary literals will start with a zero, as octal and hexadecimal numbers do, and they use a 'b' character in the same way hexadecimal numbers use 'x'.
- private void binaryLiteral() {
- // These all represent the decimal value 43:
- int decimal = 43;
- int hex = 0x2B;
- int octal = 053;
- int binary = 0b101011;
- }
We can now replace the problematic parsing code that introduced this section with this much simpler syntax: int value = 0b10100001. This approach is simpler to read (it's the same syntax as used in GCC C/C++ compilers, Ruby, and Python), quicker, can be inlined, can be used in switches, and will give a compile-time error if the letter "O" or "o" is used instead of the digit "0".
Underscores in numbers
Humans often group our numbers together for readability: we see phone numbers (at least in the United State) as 555-555-1212, we write our credit cards as 5123 1234 1234 1234, and we express large numbers as 1,234,567,890.0. While these groupings make sense for humans, they generally don't work for computers without specific formats and parsing, so we give those numbers to a computer as 5555551212, 5123123412341234, and 1234567890.0, all of which are illegible for us humans.
Fortunately, the Ruby language introduced an innovation that is being adopted in this Project Coin proposal. We now have the ability to place into our numbers underscores that the compiler will ignore. For example, int i = (1_5 + 10_5)/2_0; produces a value of 6 because the compiler sees it as int i = (15 + 105)/20;. More importantly, it means that we can process some formatted numbers without going through String parsing.
Underscores can also be used in non-decimal formats (even the new binary literal format), as seen in these examples from the original proposal:
- int phoneNumber = 555_1212;
- long creditCardNumber = 1234_5678_9012_3456L;
- long socialSecurityNumbers = 999_99_9999L;
- float monetaryAmount = 12_345_132.12f;
- long hexBytes = 0xFF_EC_DE_5E;
- long hexWords = 0xFFEC_DE5E;
- long maxLong = 0x7fff_ffff_ffff_ffffL;
- long alsoMaxLong = 9_223_372_036_854_775_807L;
-
- byte nybbles = 0b0010_0101;
- long bytes = 0b11010010_01101001_10010100_10010010;
- int weirdBitfields = 0b000_10_101;
Language support for JSR 292
JSR 292 is a larger set of changes in JDK 7 for "Supporting Dynamically Typed Languages on the Java™ Platform", and this proposal is mostly about adding a new java.dyn package for classes that will allow executing dynamically-typed languages through a new invokevirtual bytecode instruction. With its focus on bytecode support for dynamic languages, this proposal is really more for the Java platform than for the Java language. Since this article is focused on Java language changes, please see the original proposal for more information on these bytecode-level changes.
However, there is one change within the Java language that should be noted. In order to support invoking identifiers from languages that use different syntax, JDK 7 now allows "exotic identifiers". In addition to the other legal identifiers, Java now supports identifiers of the form#"name". So, this is now a legal method that prints 54:
- private void weirdMethod() {
- int #"weird variable name" = 6;
- int #"funky variable name" = 9;
- System.out.println(#"weird variable name" * #"funky variable name");
- }
Yet-To-Be-Implemented Proposals
Four of the accepted proposals have not been implemented in the public builds as of this writing. They are planned for a feature-complete milestone in June 2010. There is always a possibility that some of these will be pulled from JDK 7 before they are implemented.
In light of this uncertainty, the following sections are based on what was proposed, and they might not correspond to, or compile on, the actual implementations.
Automatic Resource Management
This proposal from Josh Bloch is intended to help Java developers dispose of resources more effectively. Until now, developers have had to manage resources manually, and this has proved to be ugly and error-prone. Even the most common "correct" idioms and example code is susceptible to leaks and failures. The essential problem is that closing resources in the finally block can itself throw an exception, and that new exception hides the original exception.
Here's a simple example to show the problem:
- static String readFirstLineFromFile1(String path) throws IOException {
- BufferedReader br = new BufferedReader(new FileReader(path));
- try {
- return br.readLine();
- } finally {
- br.close();
- }
- }
This example uses the very common approach of closing the resource in a finally block. Unfortunately, br.close() can throw an exception, so we should handle it, as in this example:
- static String readFirstLineFromFile2(String path) throws IOException {
- BufferedReader br = new BufferedReader(new FileReader(path));
- try {
- return br.readLine();
- } finally {
- try {
- br.close();
- } catch (IOException e) {
- e.printStackTrace(); // or log or ignore
- }
- }
- }
While this is a bit better, it's still problematic. Unfortunately, if both br.readLine() and br.close() throw an exception, then the second exception (which we probably don't care about) will be the one propagated. Here's the correct approach in JDK 6 and earlier to make sure the interesting exception is propagated:
- static String readFirstLineFromFile3(String path) throws IOException {
- BufferedReader br = new BufferedReader(new FileReader(path));
- boolean success = false;
- try {
- String line = br.readLine();
- success = true;
- return line;
- } finally {
- try {
- br.close();
- } catch (IOException e) {
- if (success) {
- throw e; // propagate secondary exception
- }
- e.printStackTrace(); // or log or ignore
- }
- }
- }
This is a lot of extra code just to handle exceptions, and almost no one goes to this extreme. With Automatic Resource Management, this code will be simplified because we will be able to declare and initialize the Closeable resources within an expanded try statement that declares which resources will be closed automatically:
- static String readFirstLineFromFile4(String path) throws IOException {
- try (BufferedReader br = new BufferedReader(new FileReader(path)) {
- return br.readLine();
- }
- }
Technically, the above implementation could still leak, because the FileReader also needs to close. Fortunately, the new syntax will allow declaring in the try statement all the resources that will be automatically closed:
- static String readFirstLineFromFile5(String path) throws IOException {
- try (Reader fin = new FileReader(path);
- BufferedReader br = new BufferedReader(fin) {
- return br.readLine();
- }
- }
Automatic Resource Management will reduce error-prone boilerplate code, and it will enable replacing many finally blocks with syntactic sugar that handles resources correctly and automatically.
Simplified Varargs Method Invocation
This proposal from Bob Lee removes a compiler warning that should never have been there in the first place.
When Varargs and Generics were introduced in Java 5, Varargs were implemented using arrays. Unfortunately, arrays cannot contain non-reifiable types (i.e., you can have a List[] but not a List[(String)]), so vararg methods have trouble when taking non-reifiable types. This problem comes up frequently when developers encounter a compiler warning when using Arrays.asList(...):
- private void varags() {
- List<String> list1 = Arrays.asList("foo");
- // Warning: "unchecked generic array creation
- // for varargs parameter of type ArrayList<String>[]"
- List<ArrayList<String>> list2 =
- Arrays.asList(new ArrayList<String>());
- }
The first line doesn't have a problem because Strings do not take parameterized types, but the second line that uses List produces a compiler warning. This warning is based on the internal implementation of Arrays.asList(...). Frustratingly, there is nothing a developer can do to resolve the warning short of just not using that method.
In JDK 7, these warnings will go away, because Java will move the warnings from the caller of methods like Arrays.asList(...) to the implementations. This will eliminate thousands of unnecessary and annoying compiler warnings. None of this would have been necessary had Varargs been implemented using List, but it's too late to revert that now (though an additionalList-based version of Varargs could be added in the future).
Collection Literals
This proposal from Josh Bloch adds support for immutable List, Set, and Map literals with syntax similar to that used for arrays.
Here is a snippet of the code necessary today to create immutable Lists, Sets, and Maps (ignoring utilities from libraries like Google Guava):
- private void oldInitializers() {
- final List<String> bridgeSuitOrder =
- Collections.unmodifiableList(
- Arrays.asList("Clubs", "Diamonds", "Hearts",
- "Spades", "No Trump"));
- final Set<String> originalStates =
- Collections.unmodifiableSet(
- new HashSet<String>(
- Arrays.asList("NH", "MA", "RI", "CT",
- "NY", "NJ", "PA", "DE", "MD",
- "VA", "NC", "SC", "GA")));
- HashMap<String, Double> weights = new HashMap<String, Double>();
- weights.put("H", 1.0079);
- weights.put("He", 4.0026);
- weights.put("Li", 6.941);
- weights.put("Be", 9.0122);
- weights.put("B", 10.811);
- weights.put("C", 12.011);
- final Map<String, Double> atomicWeights =
- Collections.unmodifiableMap(weights);
- }
In JDK 7, all of that will be replaceable with this:
- private void newInitializers() {
- final List<String> bridgeSuitOrder =
- ["Clubs", "Diamonds", "Hearts", "Spades", "No Trump"];
- final Set<String> originalStates =
- {"NH", "MA", "RI", "CT", "NY", "NJ", "PA", "DE", "MD",
- "VA", "NC", "SC", "GA"};
- final Map<String, Double> atomicWeights =
- { "H" : 1.0079, "He" : 4.0026, "Li" : 6.941, "Be" : 9.0122,
- "B" : 10.811, "C" : 12.011};
- }
Notice that Sets and Maps use braces ('{' and '}'), but Lists look more like arrays and use brackets ('[' and ']').
Indexing access syntax for Lists and Maps
In parallel with the previous proposal comes this proposal from Shams Mahmood, which adds array-like indexing for List and Map objects. This is another small, safe, and useful improvement in the Java language that creates consistency among different access approaches.
To see this simplification in action, compare the following two methods. Note that the new approach also uses the new initializers introduced above.
- private void oldIndexing() {
- final List<String> bridgeSuitOrder =
- Arrays.asList("Clubs", "Diamonds", "Hearts", "Spades", "No Trump");
- System.out.println("Highest Suit = " + bridgeSuitOrder.get(0));
-
- HashMap<String, Double> atomicWeights = new HashMap<String, Double>();
- atomicWeights.put("H", 1.0079);
- atomicWeights.put("He", 4.0026);
- atomicWeights.put("Li", 6.941);
- atomicWeights.put("Be", 9.0122);
- atomicWeights.put("B", 10.811);
- atomicWeights.put("C", 12.011);
- System.out.println("Carbon weight = " + atomicWeights.get("C"));
- }
-
- private void newIndexing() {
- final List<String> bridgeSuitOrder =
- ["Clubs", "Diamonds", "Hearts", "Spades", "No Trump"];
- System.out.println("Highest Suit = " + bridgeSuitOrder[0]);
-
- final Map<String, Double> atomicWeights =
- { "H" : 1.0079, "He" : 4.0026, "Li" : 6.941, "Be" : 9.0122,
- "B" : 10.811, "C" : 12.011};
- System.out.println("Carbon weight = " + atomicWeights["C"]);
- }
Setup
In order to gain experience with the implemented features of Project Coin before JDK 7 is released (currently planned for September 2010), you will need to download one of the binary snapshots. For this document, I used the milestone M7, which was released on April 15, 2010. JDK 7 is intended to be feature-complete by milestone M8 in June 2010.
Though technically one can develop Java applications with nothing but the JDK, a simple text editor, and the command line, most of us prefer to use an IDE. Unfortunately, at the time of this writing, neither IDEA nor Eclipse provides full support for pre-release versions of JDK 7. Though both provide a source-level option for JDK 7, neither provides updated inline compilation or code completion for the new features.
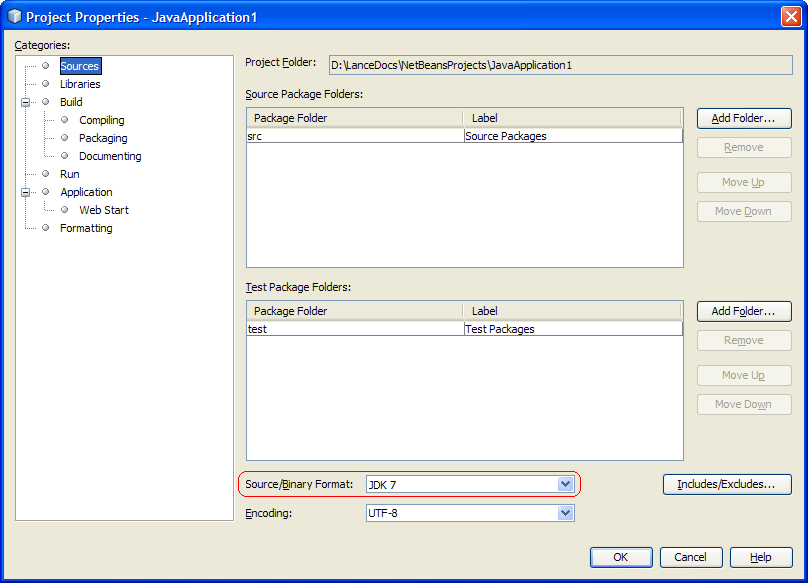
Fortunately, NetBeans provides a pre-release version of their upcoming 6.9 release that provides full in-editor support for Project Coin features. To download this version, go to the NetBeans download site and select the 6.9 milestone download (6.9M1 at this writing). Make sure to set the project's "Source/Binary Format" to JDK 7 in order to use the implemented features:
Conclusion
The small language changes accepted for Project Coin do not radically change the Java language; there is nothing here with the scope of Generics or Annotations. However, this are a collection of small and useful changes that continue the evolution of Java into a more concise and expressive language.
Not all of the new features demonstrated here are implemented, and even the ones that are might change before the final release. So,the final implementations may be different in detail when JDK 7 goes live. However, this article should be useful as a preview for the spirit of the new features.
The "open suggestion box" nature of Project Coin is a new approach for the stewards of the Java language, and I hope that it is repeated in future versions. Having developer-driven input to the language evolution will help Java continue to be relevant and enjoyable to use.
References
- [1] Project Coin
http://openjdk.java.net/projects/coin/ - [2] coin-dev mailing list
http://mail.openjdk.java.net/mailman/listinfo/coin-dev - [3] JDK 7 - (build 1.7.0-ea-b87 used in this article)
https://jdk7.dev.java.net/ - [4] NetBeans download site - (use 6.9 or higher to test Project Coin features)
http://netbeans.org/downloads/ - [5] Joseph Darcy presentation at Devoxx 2009 -
http://mediacast.sun.com/users/jddarcy/media/Devoxx2009-Project-Coin.pdf - [6] Bob Lee presentation at Strange Loop 2009 -
http://thestrangeloop.com/sites/default/files/slides/BobLee_FutureOfJava.pdf - [7] Source Code for Examples
May2010-src.zip
