enjoying a Friendly Front End with Elm
By Tyler Haas, OCI Software Engineer
AUGUST 2017
Introduction
Elm is a fairly new programming language that has been gaining momentum as a better way to do client side web development. Created in 2012 as Evan Czaplicki's senior thesis at Harvard University, Elm takes away many of the pains experienced by JavaScript developers on a daily basis.
Elm is a strongly typed, purely functional programming language which compiles to JavaScript. But what really makes it shine is that it boasts 0 runtime exceptions and super-friendly error messages.
Elm has an intense focus on simplicity that makes for an amazing developer experience and more maintainable and testable code. This makes it an excellent choice for developers who have minimal experience with JavaScript or even no programming experience whatsoever. Having said that, if you have used React or Redux, you'll feel right at home.
Elm also has a focus on maintainability as a code base grows. More on that later, but suffice it to say that for those looking for a way to write clearer, more maintainable large-scale web apps, Elm may be a really good option, even if you have no prior functional programming knowledge.
In this article, we will visit Elm from a high level and explore what makes it such a great language. My hope is that reading this will encourage you to explore Elm and consider it for your next project.
A HISTORY OF PROGRAMMING LANGUAGES
Looking at a history of programming languages can help us see why Elm was created and which problems Elm solves. It should be noted that the history that will be described here is a very simplified version and doesn't encompass all the reasons different programming languages were created. It does, however, illustrate a problem that many client-side single-page applications (SPAs) struggle with.
First, there was Assembly. It was very low level and hard. But somehow programmers were able to write in it and make some cool things.
Eventually, though, they reached a point where they said, "This is a maintainability nightmare! There has to be a better way!" And so they made C.
All of a sudden, developers were writing programs at a much higher level and it was great! But they still had a complaint. "What is with all this memory management? There has to be a better way!" And so Java was born.
Java is a great language. Web applications have been – and still are – written in it. But again we reached another crisis point where we said, "This is great for maintainability ... but what about all those types?! There has to be a better way!" And so we got JavaScript.
Today virtually all client-side code is written in JavaScript. As we have faced challenges, there has been one answer ... more JavaScript! From libraries to fill in missing features of the language to frameworks that make creating SPAs easier. Many engineers recently have noticed one problem that is caused by the nature of the JavaScript language: maintainability.
Any experienced JavaScript developer is familiar with the myriad issues with scaling JavaScript code. Maybe it's "spaghetti code" that makes tracking what your code base is doing hard. More likely it's shared state that is being changed in hundreds of places. Whatever the cause, the result is an application that makes it difficult to add new features and debug existing ones. I'm sure you have at some point tried to add a feature to one JavaScript application with 50,000+ lines of code and ended up breaking three.
So there is this huge problem that needs to be solved. The two main solutions to come out are Typescript and Flow. Both are great technologies for introducing types into your JavaScript. This has amazing benefits for refactoring code. Also, both of these have type inference, which allows them to know the type of an initialized variable without any type declarations. This is nice, since it gives the program some added type safety at compile time without the cumbersome declarations littered throughout the code base.
The implementation of how they determine the type is a little bit different for each, but both Flow and Typescript do a really good job of inferring primitive types. Non-primitive type inference in these systems is a bit more complex and causes things to break down a little. This is due to JavaScript's mutable nature. If an array or object is declared with no type declaration, the only thing that can be inferred is what type it is. What cannot be guaranteed is the shape of the value being assigned to the variable. This is very different from what you will find in Elm.
In Elm, all values are immutable, which allows Elm to make guarantees about the types of values in the application. Languages that are simply supersets of JavaScript need to respect the nature of dynamic languages and cannot make this same guarantee. In addition, Elm compares the types of what is being used in the application in such a way that everything has to match exactly. So If I declare the following shape:
let obj = {key1: string, key2: number}Then every time obj is used, Elm will check that it is an object where key1 is a string and key2 is a number. Typescript and Flow can't do that because they can't guarantee that the original structure of obj won't change the way Elm can.
The result of this enhanced type inference is an application that is extremely maintainable and doesn't require any type declarations! What this means for developers is that they can focus on writing applications and figure out the best way to write code in a maintainable way while keeping all the benefits of strongly typed languages.
BUILDING A MODERN WEB APP

Another problem that many web developers face is knowing all the different parts of getting a project setup. There is a term for this, at least among JavaScript developers. They call it JavaScript fatigue. It has developed this name because the tooling around the client side of a project is constantly changing, requiring additional learning.
JavaScript fatigue isn't a particularly hard problem to overcome. Software developers generally are quite good at learning new technologies and most of the time enjoy doing so. However, there is a cost to this. First, there is a monetary cost of training on the new technology. Even more important than that, there is a cost in complexity. Every package or tool that is added to a project adds complexity around the number of things developers need to keep in their heads and consider when bugs occur. This is by far the weightier cost compared to the training time of the team.
JavaScript
Let's walk through the typical components in a client side project in order to illustrate how these costs are introduced:
- The project will need a way to manage all the dependencies. So, the development team pulls in NPM or yarn to manage this.
- Next, they'll likely want to use the latest features of JavaScript, even if they aren't yet supported in all browsers. Babel can take care of this by transpiring ES6+ to ES5.
- Next, the project developers will be concerned about the performance of their application, so they pull in a bundle like Bowserify or Webpack. This will bundle and minify all code into one file that can be shipped efficiently to the client.
- Most will also utilize some sort of framework to write their UI code. React has become the choice of many front-end applications, but they may also choose Angular or Ember for this. They choose one and pull it in as another dependency.
- Next, they will need a good way to manage the state of the application. Redux has been the de facto solution for this for some time, so they pull that in as well.
- Many will also want to make sure that their code is optimized with persistent data structures so that any creation of new objects and arrays can be optimized.
- Then, they'll turn their attention to the development experience and pull in a few tools to make their lives easier.
- First, something that will support type declarations like Flow or TypeScript.
- They'll also want some sort of liner to catch any mistakes in their syntax. ESLint is good for this.
- Finally, they may choose to pull in Prettier, which is a very opinionated code formatter. This will avoid formatting arguments among the team and make sure there is consistency across the code base.
Whew! That was a lot! As discussed previously, each of these has overhead and introduces complexity even before we have started writing a single line of code.
Elm
Elm has a very different story. All of this is built in!
Let's go through how Elm provides all these features for free.
- Elm is a language and a platform so it comes with a great command line interface (CLI) that will handle all the dependencies of a project. Just run
elm package install, and Elm will set up everything needed to start a new project. - Babel and Webpack are unnecessary because Elm is compiled to a JavaScript bundle using the ECMAScript3 standard.
- Also, all Elm applications follow "The Elm architecture," so no frameworks or state-management tools are needed. Everyone just uses what is built into the language.
- Types are core to the language, so there is no need for Flow or TypeScript.
- Elm's compiler will catch all errors at compile time, so no linters are needed (much more on this later).
- Much of the tooling that is used in a typical application just goes out the window because it is baked right into the Elm platform. The only exception to this is elm-format, which takes the place of Prettier.
This is great because developers can learn Elm once and no longer have to worry about learning the latest JavaScript tools, thus avoiding JavaScript fatigu" and greatly simplifying their apps.
LANGUAGE GUARANTEES

What makes Elm so exciting is the guarantees it provides. It has quite a lot of constraints which at first – especially from the perspective of JavaScript – sounds like a bad thing. However, as you work within them more, you learn that these constraints actually enhance the code you write and result in higher-quality applications. Also by making these guarantees, Elm can totally eliminate whole classes of runtime errors!
No Null or Undefined Values
The first of these guarantees is that no value can be null or undefined. This probably is the most important guarantee. Many developers have been bitten by errors related to null values or undefined is not a function. In fact, null errors are such a problem that their creator called them his "billion-dollar mistake."
“I call it my billion-dollar mistake… At that time, I was designing the first comprehensive type system for references in an object-oriented language. My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn’t resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.”
– Tony Hoare, inventor of ALGOL W.
All Functions Are Pure
Another great language guarantee is that all functions are pure.
A pure function is one that always returns a value, and its return value is entirely dependent on its inputs and not on any external or member state. In other words, given the same inputs, it will always return the same result. This means that no HTTP requests or things like random number generation can be inside an Elm program. There are of course ways to do these, but we'll wait until our discussion of the Elm architecture to cover that.
This concept is very powerful. No longer does the developer have to keep in his or her head how external variables might affect a line of code because they are impossible to access. Also, this eliminates a whole range of bugs that are caused by external variables being changed in an unexpected way. This also has amazing benefits for testing. No more mocks; just call the function with some inputs and test its return value!
All Values Are Immutable
The next language guarantee is that all values are immutable. This again helps with avoiding bugs because it is impossible to have something in an obscure location of the codebase change an array or object.
Countless hours have been spent over the years trying to track down what is changing a value unintentionally. In Elm, this just isn't a problem. And for those who are concerned about memory management, Elm uses persistent data structures under the hood, which share as much of the previous data in memory as possible to help with efficiency.
Accurate Inference of All Types
Lastly, all types can be inferred quickly and accurately. This is great for maintenance of your applications. Unlike many strongly typed languages, you don't spend most of your development time declaring types.
In most Elm programs the parameters and return types of functions are declared. While this is good for documentation and providing the compiler with additional information, it is completely optional. If you do opt to do that it would look like this:
update : Msg -> Model -> ModelThis simply says that there's a function called update that accepts a Msg type and a Model type and returns a new Model.
The Elm Architecture
“When building front end applications in Elm, we use the pattern known as the Elm architecture. This pattern provides a way of creating self-contained components that can be reused, combined, and composed in endless variety.” [1]
This architecture provides a simple structure that makes web apps easy to reason about. It does such a good job of this that many have adopted it as a way to build applications in many other languages. This is achieved through:
- A consistent way to structure code
- A centralized data model
- Employing changes through a message-based system
- Declarative views
- Managed effects
One-Way Data Flow
One of the concepts that make Elm code easy to follow is that it uses one-way data flow. This makes it easy to track things as they flow through your program. Here is what the data flow looks like at a high level:
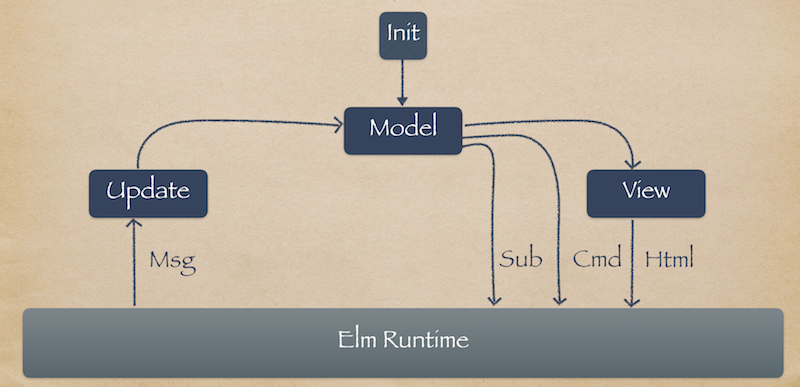
We start by initializing a model to hold the state of our application. This model is then used to render our view, which is passed to the Elm runtime. Any time there is user interaction or external changes, they are sent as messages. Our update function then takes the messages and a model and returns an updated model that is passed back to our view code and the cycle continues.
Any time the model changes, the whole view code runs and then the resulting view is diffed against its previous version using an in-memory representation of the DOM called the virtual DOM. This enables the runtime to decide what are the minimal updates that need to be made in order to make the view look a certain way.
Let's look at each of these stages in greater detail.
Centralized Data Model
The first principle of the Elm architecture is that the model contains the whole state of the app in a single record — an Elm record is similar to a JavaScript object. This acts as the single source of truth for the app.
Dan Abramov described the benefits of this quite nicely.
“This makes it easy to create universal apps, as the state from your server can be serialized and hydrated into the client with no extra coding effort. A single state tree also makes it easier to debug or inspect an application; it also enables you to persist your app's state in development, for a faster development cycle. Some functionality which has been traditionally difficult to implement - Undo/Redo, for example - can suddenly become trivial to implement, if all of your state is stored in a single tree.”[2]
This state tree drives everything in the application. Any interaction with the application simply changes the state tree, which means that most bugs can be solved simply by looking at the state of your model at the time the bug occurs.
Here is the Model from an example application that creates a player card in the game "Exalted":
- Model = {
- playerInformation : [
- ( "Name", "Tyler" ),
- ( "Player", "One" ),
- ( "Caste", "Dawn" ),
- ( "Concept", "My Concept" ),
- ( "Anima", "White Wolf" ),
- ( "SupernalAbility", "Archery" )
- ],
- exAttributes : [
- ( "Strength", 1 ),
- ( "Dexterity", 1 ),
- ( "Stamina", 1 ),
- ( "Charisma", 1 ),
- ( "Manipulation", 1 ),
- ( "Appearance", 1 ),
- ( "Perception", 1 ),
- ( "Intelligence", 1 ),
- ( "Wits", 1 )
- ],
- exAbilities : [
- ( "Archery", False ),
- ( "Athletics", False ),
- ( "Awareness", False ),
- ( "Brawl", False ),
- ( "Buraucracy", False ),
- ( "Craft", False ),
- ( "Dodge", False ),
- ( "Integrity", False ),
- ( "Investigation", False ),
- ( "Larceny", False ),
- ( "Linguistics", False ),
- ( "Lore", False ),
- ( "Martial Arts", False ),
- ( "Medicine", False ),
- ( "Melee", False ),
- ( "Occult", False ),
- ( "Performance", False ),
- ( "Presence", False ),
- ( "Resistance", False ),
- ( "Ride", False ),
- ( "Sail", False ),
- ( "Socialize", False ),
- ( "Stealth", False ),
- ( "Survival", False ),
- ( "Thrown", False ),
- ( "War", False ),
- ]
- }
It's important to note that most Elm applications have a more complex model than this, yet their models look significantly simpler than what you see above. This is achieved through Elm's robust type system and helper functions.
In a real Elm app the same record would mostly look like this:
- Model = {
- playerInformation: initPlayerInformation,
- exAttributes: initExAttributes,
- exAbilities: initExAbilities
- }
-
- initPlayerInfo = Dict.fromList [
- ( "Name", "Tyler" ),
- ( "Player", "One" ),
- ( "Caste", "Dawn" ),
- ( "Concept", "My Concept" ),
- ( "Anima", "White Wolf" ),
- ( "SupernalAbility", "Archery" )
- ]
- ...
Message-based System
In order to change the application model, the Elm runtime sends a message to the update function. This message tells the application what happened, and the update function responds by causing the view to change in some way.
Here's an example of that.
First, declare all the messages that the application could possibly send, like so:
- type Msg
- = EditPlayerInformation String String
- | EditExAttribute String Int
- | EditExAbility String Int
- | ToggleCasteOrFavored String
Then, write an update function to handle the messages.
Try not to get caught up in the syntax here. Instead, pay attention to how each of these branches is simply taking in a message and a model and returning a new model.
- update msg model =
- case msg of
- EditPlayerInformation section val ->
- let
- newPlayerInfo =
- Dict.insert section
- (if String.length val > 0 then
- (Just val)
- else
- Nothing
- )
- model.playerInformation
- in
- { model | playerInformation = newPlayerInfo }
-
- EditExAttribute exAttribute attributeValue ->
- { model | exAttributes = Dict.insert exAttribute attributeValue model.exAttributes }
-
- EditExAbility exAbility abilityValue ->
- let
- ( favored, _ ) =
- Dict.get exAbility model.exAbilities
- |> Maybe.withDefault ( False, 0 )
- in
- { model | exAbilities = Dict.insert exAbility ( favored, abilityValue ) model.exAbilities }
-
- ToggleCasteOrFavored exAbility ->
- let
- ( favored, abilityValue ) =
- Dict.get exAbility model.exAbilities
- |> Maybe.withDefault ( False, 0 )
- in
- { model | exAbilities = Dict.insert exAbility ( not favored, abilityValue ) model.exAbilities }
The important take away here is that this message-based approach makes it easy to track what is changing the state of the app simply by knowing what message is sent. And since all the changes to your model are in the update function, it makes finding the bug much easier.
Declarative View
In imperative languages, a change to the view of the application is accomplished by providing each step needed to make a necessary change. Elm applications simply declare how they want the next state of the application to look, and the runtime takes care of what needs to change in the DOM to make it look that way through the use of the virtual DOM. This greatly simplifies things while making Elm highly performant. Of course, as mentioned before, the Model drives the view.
Let's see an example.
You may notice that this is formatted differently. Elm programs are usually formatted with leading commas, but don't let that throw you. While somewhat jarring at first, it has some definite benefits:
- First, if a comma is missed, it becomes very obvious, and that's a good thing.
- Second, a feature of Elm's tooling we'll discuss later depends on very clean output when viewing the differences between two versions of a package. The leading comma syntax cleans up the output nicely in that case.
- view model =
- div []
- [ playerInformationView model
- , allExAttributesView model
- , allExAbilitiesView model.exAbilities
- ]
-
- ...
-
- allExAbilitiesView exAbilities =
- div []
- ([ h2 [] [ text "Abilities" ] ]
- ++ List.map
- (exAbilityView exAbilities)
- abilities
- )
-
-
- exAbilityView exAbilities exAbility =
- let
- ( favored, exAbilityVal ) =
- Dict.get exAbility exAbilities
- |> Maybe.withDefault ( False, 0 )
-
- filledList =
- List.map2 (\ref val -> ref >= val)
- (List.repeat 5 exAbilityVal)
- (List.range 1 5)
- in
- div []
- [ casteOrFavoredBox exAbility favored
- , text (exAbility ++ " ")
- , div
- []
- (List.map2 (abilityDot exAbility)
- (List.range 1 5)
- filledList
- )
- ]
Let's walk through this code:
A function in Elm starts with the name of the function followed by any parameters it accepts separated by whitespace. That makes sense, since the model is driving how the application looks at any point in time.
All HTML element functions, such as div or button, accept two arrays:
- The first array is for the attributes of the element
- The second is for its children
Looking at the view function, it accepts a model which passes down its exAbilities property to the allExAbilitiesView function. This function, in turn, passes the exAbilities array, along with an exAbility, to the exAbilityView function, which will return HTML.
In this way, the whole view of the application operates on the model, so that as the model changes, the view does as well.
Note that nowhere in our view code does it say how to change the DOM but instead, says, "Hey, Elm. Please make the DOM look like this."
Managed Effects
Since Elm has only pure functions, it is impossible to have any sort of side-effects within the application. Instead, it provides a way to tell Elm that you want to perform a side effect, and the Elm runtime will handle that task for you.
When Elm completes the task, it'll return a message just like any other event. It has two different mechanisms to do this:
- Subscriptions
- Commands
Subscriptions
Subscriptions are how an application can listen for external input such as keyboard events, global mouse events, browser location changes, and websocket events.
Let's look at an example:
- module Main exposing (..)
-
- import Html exposing (Html, div, text)
- import Mouse
- import Keyboard
-
-
- -- MODEL
-
-
- type alias Model =
- Int
-
-
- init : Model
- init =
- 0
-
-
- -- MESSAGES
-
-
- type Msg
- = MouseMsg Mouse.Position
- | KeyMsg Keyboard.KeyCode
-
-
- -- VIEW
-
-
- view : Model -> Html Msg
- view model =
- div []
- [ text (toString model) ]
-
-
- -- UPDATE
-
-
- update : Msg -> Model -> Model
- update msg model =
- case msg of
- MouseMsg position ->
- model + 1
-
- KeyMsg code ->
- model + 2
-
-
- -- SUBSCRIPTIONS
-
-
- subscriptions : Model -> Sub Msg
- subscriptions model =
- Sub.batch
- [ Mouse.clicks (\_ -> MouseMsg)
- , Keyboard.downs (\_ -> KeyMsg)
- ]
The code starts by declaring this as the main module and allowing anything that imports it to access all functions inside it with the exposing (..) syntax.
Next, it imports the Html, div, and text functions from the Html module. Also, the Mouse and Keyboard modules are imported.
Then, a Model type is declared as an Int.
Next, the model is initialized in the init function to 0.
The Msg type is declared to be either a MouseMsg or a KeyMsg. Jumping down to the subscriptions function, this tells Elm to listen for a mouse click and uses an anonymous function as a callback to send the MouseMsg to our program when it receives a click anywhere on the page.
The same pattern is followed for keydown with the KeyMsg.
Finally, up in our update function, when we receive either of those messages, we increment the model, which is then sent to our view.
Commands
Commands are how to tell the runtime to execute things that involve side effects. Some examples of this include:
- Random number generation
- Making an HTTP request
- Saving to local storage
Here's an example:
- module Main exposing (..)
-
- import Html exposing (Html, div, button, text)
- import Html.Events exposing (onClick)
- import Random
-
-
- -- MODEL
-
-
- type alias Model =
- Int
-
-
-
- init : ( Model, Cmd.none )
- init =
- ( 1, Cmd.none )
-
-
- -- MESSAGES
-
-
- type Msg
- = Roll
- | OnResult Int
-
-
- -- VIEW
-
-
- view : Model -> Html Msg
- view model =
- div []
- [ button [ onClick Roll ] [ text "Roll" ]
- , text (toString model)
- ]
-
-
- -- UPDATE
-
-
- update : Msg -> Model -> ( Model, Cmd Msg )
- update msg model =
- case msg of
- Roll ->
- ( model, Random.generate OnResult (Random.int 1 6) )
-
- OnResult res ->
- ( res, Cmd.none )
This snippet is much the same as the subscriptions version, except we are importing onClick from the Html.Events module and the Random module. Also, our init function has changed to accept the Model and a Cmd, which is initialized to send no commands.
Again, we have two messages that our app accepts, Roll and OnResult.
OnResult accepts an Int as its payload. When the runtime sends the Roll message our program will send back the original model and a command to be executed. It has also declared that OnResult is the message that should be returned upon completion of the command. The command will generate a random integer between 1 and 6. Once the command completes it will send the OnResult message to our program with a random number that we will use as our new model.
Consistent Structure
All Elm programs follow a model, view, controller pattern of structuring the application. Elm does this through a program function that accepts a record containing fields for init, view, update, and subscriptions.
Here is what the whole application file would look like:
- module Main exposing (..)
-
- import Html exposing (Html, div, button, text, program)
- import Html.Events exposing (onClick)
- import Keyboard
- import Mouse
- import Random
-
-
- -- MODEL
-
-
- type alias Model =
- Int
-
-
- init : ( Model, Cmd Msg )
- init =
- ( 1, Cmd.none )
-
-
-
- -- MESSAGES
-
-
- type Msg
- = KeyMsg
- | MouseMsg
- | OnResult Int
- | Roll
-
-
-
- -- VIEW
-
-
- view : Model -> Html Msg
- view model =
- div []
- [ button [ onClick Roll ] [ text "Roll" ]
- , text (toString model)
- ]
-
-
-
- -- UPDATE
-
-
- update : Msg -> Model -> ( Model, Cmd Msg )
- update msg model =
- case msg of
- KeyMsg ->
- ( model + 2, Cmd.none
-
- MouseMsg ->
- ( model + 1, Cmd.none )
-
- OnResult res ->
- ( model + res, Cmd.none )
-
- Roll ->
- ( model, Random.generate OnResult (Random.int 1 6) )
-
-
- -- SUBSCRIPTIONS
-
-
- subscriptions -> Model -> Sub Msg
- subscriptions model =
- Sub.batch
- [ Mouse.clicks (\_ -> MouseMsg)
- , Keyboard.downs (\_ -> KeyMsg)
- ]
-
-
- -- MAIN
-
-
- main : Program Never Model Msg
- main =
- program
- { init = init
- , view = view
- , update = update
- , subscriptions = subscriptions
- }
There aren't a lot of new pieces here. The main thing to notice is that there is the MAIN section at the bottom.
Elm always looks for a main function as its entry point to the application. We put the program function there so that we can glue our init, view, update, and subscriptions functions together. Now:
- When we click anywhere on the screen, the counter will be incremented by 1
- Any keypress will increment the counter by 2
- If we click the "roll" button, the counter will be incremented by a random number between 1 and 6
This isn't a complicated program, but you can see how this scales well to large apps. By taking a model, view, update approach it organizes where to find everything quite easily.
In addition, we still have all the benefits discussed before of having everything be immutable, one-way data flow, and a single source of truth.
JavaScript Interop
As mentioned Elm began in 2012, so it is still very young and has yet to develop the same robust ecosystem that JavaScript has.
By comparison NPM, JavaScript's package registry, has 488,791 packages with approximately 557 new packages being added every day. Elm, on the other hand, only has 973 packages available, of which only 657 are compatible with the latest version of Elm.
This means that JavaScript adds more packages to its registry in a two-day period than Elm has in total!
JavaScript's large, active community has always been one of its greatest strengths. This enables JavaScript applications to be built very quickly and cheaply by leveraging open source packages available through NPM.
Elm needs a way to take advantage of this resource. The problem is that if it were possible to just intermingle JavaScript code in with Elm code, it would ruin all the nice guarantees we have been talking about.
The solution that Elm came up with is "Ports." Ports allow data to be passed from JavaScript code to Elm and vice versa. This allows all the great features of Elm to stay intact but also take advantage of JavaScript's robust package registry.
There is another important benefit from having this interop capability via the use of Ports. It allows for Elm to be introduced in a less risky way.
Since Elm can interoperate with JavaScript, you can introduce it to an existing application on as small of a feature as you want. In fact, nearly all successful Elm projects in production have started out this way. They found a piece of their existing application that was a pain spot or had a feature that lent itself to Elm's strengths and just gave it a shot. From there, they were able to analyze whether they liked it or not without being tied to Elm outside of one small part of their code base.
Built-in Tooling
Elm has some great tools built right in to assist with the development of frontend applications, most notably the compiler, but also its “Time Travelling Debugger” and elm-package.
There are comparable tools in the JavaScript ecosystem, but it is really nice that these come along for free.
It's also important to remember that Elm is still young as far as programming languages go, so while these tools are incredibly sophisticated and helpful, it's reasonable to expect these tools to get better over time.
The Compiler
Elm is best known for its ability to eliminate all runtime errors. However, its best feature by far is its compiler.
The compiler constantly checks your work, alerting you to potential errors and pitfalls. By tracking your program and telling you when you haven't handled all possible scenarios, it helps you avoid errors at runtime. It will catch syntax errors and misspelling of function and constant names. This is very helpful, but the best part is that it has the most friendly error messages of any language.
Friendly Error Messages
One thing that many developers run into when programming in JavaScript is that the error messages aren't always helpful. Many times the console will simply show an error that is vague such as the infamous “undefined is not a function.” Worse than that, sometimes the actual error was many files away from execution at the time of the error.
Elm's compiler greatly improves on this by giving us extremely helpful error messaging. Here are a few examples:
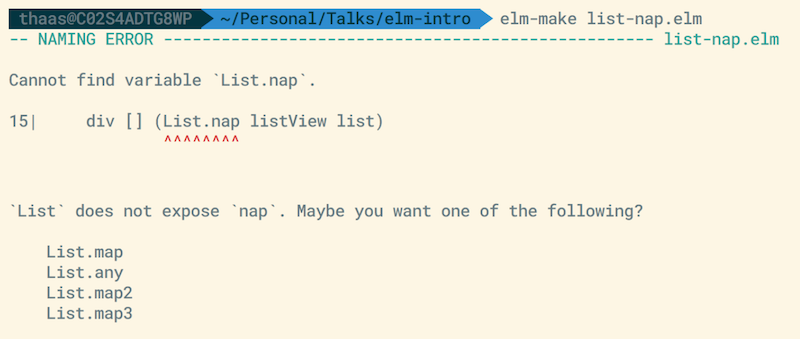
Here the code calls List.nap , which does not exist. What the compiler does is really quite nice.
First, at the very top, it tells us there is a NAMING ERROR and tells us it is happening in the file list-nap.elm.
Further, it narrows this down by showing the code is on line 15 and even gives us nice markers where the naming error is occurring.
Most impressively though, it gives us this amazing message so we can clearly know that it failed because List.nap doesn't exist, complete with suggestions of similar functions that do exist in the List module!
Let's look at another message:
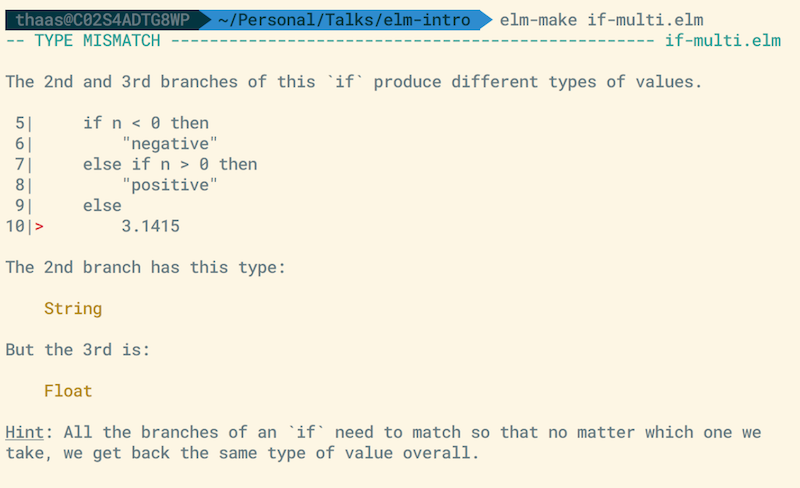
This is a type mismatch error message. The thing to notice here is that it shows the whole expression, which is found on lines 5 - 10 in this example.
Since this is a type mismatch, it puts a marker on the line of the expression that is causing the mismatch. It then gives a very readable message telling about branches 1 and 2 having a different type than branch 3 in the if statement, along with showing the types of each branch.
The best part about this message is the text in the hint. It actually teaches us about the language and why our code wouldn't work. In this case, that all branches must return the same type.
This is not unique to this error message. In fact, teams using Elm in their projects often mention how they can introduce Elm to new developers who have never used the language, and the compiler is helpful enough with hints like these to actually teach them enough to be productive.
Let's look at one last error message:
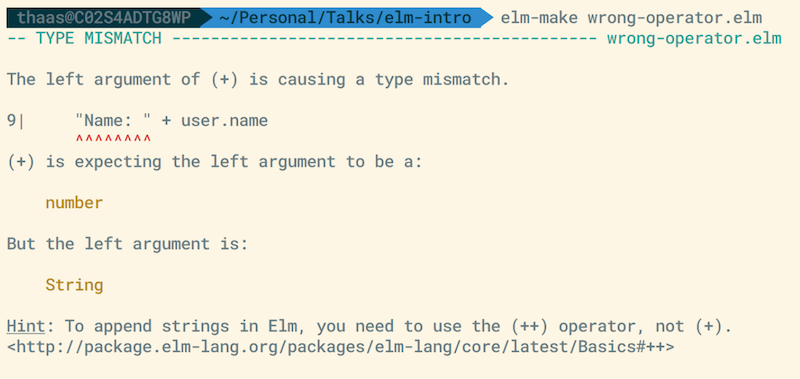
This is similar to what we've seen before. We get the line number, markers pointing out where the error is, and a friendly message telling us that the type of the argument on the left doesn't match what the “+” operator expects.
Looking at the hint, we can see that the code used the wrong operator if we want to append strings. Further, it gives us a link to the documentation if we want to read up on the correct operator, the “++” operator. Very nice!
Compiler Driven Development
With error messages like the ones displayed above, the compiler has quickly gained a reputation of being very developer friendly. This has brought on a term in the Elm community, “compiler driven development.”
What this means is that you can make a change and trust that the compiler will have your back and guide you through all the affected parts of your code base. Once you no longer have any error message and it is successfully compiled, your shiny new feature is working!
This really is an amazing workflow. Literally, just dream up any feature, add it to your view code, and wait for the lovely error messages to start pouring in.
In other languages, error messages are something to be avoided, and the developer doesn't get a good feeling when they see them. An Elm developer, on the other hand, welcomes error messages with open arms because of this workflow and how much benefit they get out of it.
Let's walk through an example of adding a feature, so we can get a feel for how this works.
The feature we will be implementing is to add a reset button to the counter example we have been using.
The first thing we want to do is to add our feature. Let's go to the view code and add a button that resets the count on click.
- -- VIEW
-
-
- view : Model -> Html Msg
- view model =
- div []
- [ button [ onClick Reset ] [ text "Reset" ]
- , button [ onClick Roll ] [ text "Roll" ]
- , text (toString model)
- ]
Now we have our button. Let's see what happens when we compile.

What this is telling us is that our program doesn't have a Msg type of Reset. Easy enough. Let's go add that.
- type Msg
- = KeyMsg
- | MouseMsg
- | OnResult Int
- | Reset
- | Roll
Here we've added Reset to our list of possible messages in our application. If we try to compile again, we'll get another error that looks like this:

We can really start to see the power of the compiler. It is quite literally walking us through this process step by step, telling us exactly what we need to do next to get everything working!
This time it is telling us that we aren't handling the Reset Msg we just made and need to add a case for that in our update function. Let's reset our count to 0 when we receive the Reset Msg.
- update : Msg -> Model -> ( Model, Cmd Msg )
- update msg model =
- case msg of
- KeyMsg ->
- ( model + 2, Cmd.none )
-
- MouseMsg ->
- ( model + 1, Cmd.none )
-
- OnResult res ->
- ( model + res, Cmd.none )
-
- Reset ->
- ( 0, Cmd.none )
-
- Roll ->
- ( model, Random.generate OnResult (Random.int 1 6) )
Awesome! Now we're handling the Reset Message.
Let's try to compile and see what the next step is.
Success! Compiled 1 module.
Successfully generated index.html
Looks like that's it! This was a very pleasant experience thanks to the Elm compiler.
Using this workflow is great because we can let the compiler walk us through all the places that are affected by a change, allowing us to just worry about the business logic.
Time Traveling Debugger
The nature of the Elm architecture has made it really easy to track how our data changes at any point in time. The only way to change the data model is through the use of a message, and the model is completely responsible for driving the view of the application. This means that if the view ends up in an unexpected state, the last message received at the time the view changed unexpectedly will be responsible for the bug. This may lead to discovering that the update function has some incorrect logic, or it may be that the wrong message was sent. Whatever the source of the bug, the gain here is that we can isolate where the bug is coming from much faster.
Using this knowledge Elm has come up with a tool called the "Time Travelling Debugger." This tool simply watches all messages that are being received and will show you what the model looks like at the point each message was received. It will also allow you to replay how the application looked at the point of the message. This makes it easy to just scroll through the list of messages and look at the UI to figure out when things are going wrong, so that the developer can identify which message is causing the bug.
Another great feature of this tool is that it allows for the history of these messages to be imported and exported. This is a great feature in the situation where a QA engineer or another developer finds the bug. Usually, in these situations, they would need to document all the steps required to reproduce the bug to the developer who is responsible for fixing it. Sometimes even though these details are documented, it's still hard to reproduce.
The Time Travelling Debugger alleviates this by just exporting the file, sending it over to the developer, who then imports it and is able to replay the application by scrolling through the applications messages as described previously.
Elm Reactor
This feature isn't fancy but it is worth mentioning. Elm Reactor is a built-in way to run the application locally. The main thing that it provides is that it sets up the Time Travelling Debugger. However, it doesn't have anything like live-reload or hot module replacement, so as the application grows, it's best to switch off Elm Reactor in favor of something like Webpack for convenience sake. But it will provide the necessary tooling to get up and going at least in the early stages of the application.
Elm-package
Elm-package is the tool provided to manage dependencies. This includes:
- Installing dependencies into a project
- Publishing packages to the registry
- Updating published packages
Typically, this is where the feature set of most package managers stops, but Elm-package has some extra features that make a huge difference in the experience of maintaining an application.
Elm Package Install
The most basic and frequent way that Elm-package is used is to install dependencies. Elm's registry is set up to namespace all packages under the username of its publisher.
For example, if someone with the username of "bestdeveloperever" made a package called "superhumblepackage," you could add that as a dependency by typing
elm package install bestdeveloperever/superhumblepackageAnother feature of Elm-package is that it follows the rest of the Elm platform in providing a great developer experience.
Let's look at how this is accomplished by installing Abadi Kurniawan's date picker package. Running
elm package install abadi199/datetimepickerwould output the following in the terminal:
To install abadi199/datetimepicker I would like to add the following dependency to elm-package.json:
"abadi199/datetimepicker": "5.0.0
May I add that to elm-package.json for you? [Y/n]It may seem like a small thing to ask that the package be added to elm-package.json (the package.json of elm), but it is nice that there is an explicit way to opt out of putting things in the elm-package.json.
In our case, we will depend on this package for our datepicker, so let's add that to the json file and enter Y or simply press enter. Doing so will result in additional text.
Some new packages are needed. Here is the upgrade plan.
Install:
abadi199/dateparser 1.0.2
abadi199/datetimepicker 5.0.0
elm-community/list-extra 6.1.0
elm-lang/core 5.1.1
elm-lang/html 2.0.0
elm-lang/svg 2.0.0
elm-lang/virtual-dom 2.0.4
elm-tools/parser 2.0.1
elm-tools/parser-primitives 1.0.0
rluiten/elm-date-extra 8.7.0
rtfeldman/elm-css 8.2.0
rtfeldman/elm-css-helpers 2.1.0
rtfeldman/elm-css-util 1.0.2
rtfeldman/hex 1.0.0
Do you approve of this plan? [Y/n]Here the Elm-package is warning of all the packages that datetimepicker depends on and is making sure that it's okay to install all of those. Again, a very nice experience from a developers standpoint because it allows us to take a second look at how installing this package will affect the project.
Elm Package Publish & Elm Package Bump
This brings us to one of the best features of Elm-package, the experience of publishing to the registry.
Once ready to publish to the registry, the only thing that needs to be done is run the command
elm package publishin the terminal. This will kick off the process of publishing your package to the registry.
This is a nice, simple experience, but the true power of this amazing CLI comes in when you are trying to bump the version. Elm uses semantic versioning, just as most package managers do. What separates it is that it can actually enforce that semantic versioning is properly followed!
Here is an image of a package that incorrectly attempted to bump the version number as a minor version:
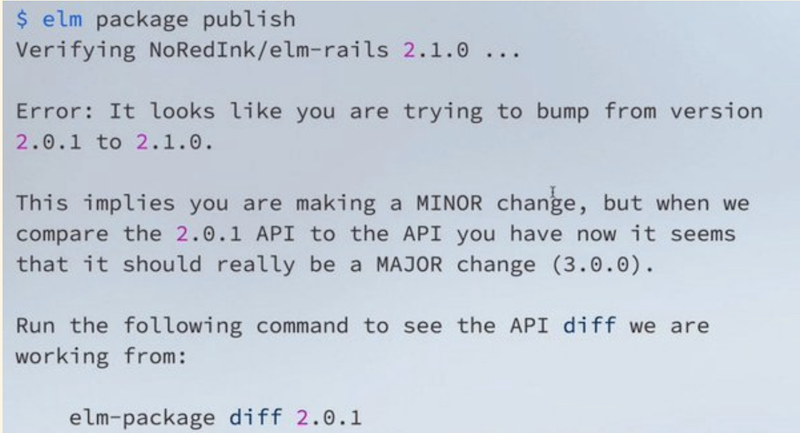
What this error is saying is that it has actually detected that the changes made to the package are a breaking change, and the version is only being bumped by a minor change.
This is amazing because now developers can finally completely trust that if they say that they want to accept any updates to packages, as long as they aren't major version updates, they can be confident that their application won't break unintentionally. This is done by doing a diff between the types throughout the program and can tell how drastically the API has changed based on how those types are used.
Because it has this capability it actually makes things even easier to do versioning because we now can use
elm package bumpand Elm-package will do all the diffing and automatically bump the package to the correct version based on the API.
Elm Package Diff
The last command that Elm-package provides is
elm package diffThis command simply outputs the API differences between two versions of an API, so that maintainers of a package see why their package was bumped in a certain way. But also so consumers of a package can see what changed in an API before deciding if they want to go through the work of updating their code base to be compatible with the new version.
Here is what the output looks like if we run
elm package diff Bogdanp/elm-ast 7.0.0 8.0.3Comparing Bogdanp/elm-ast 7.0.0 to 8.0.3...
This is a MAJOR change.
------ Changes to module Ast.Statement - MAJOR ------
Changed:
- type Statement
= Comment String
| FunctionDeclaration Ast.Helpers.Name (List Ast.Expression.Expression) Ast.Expression.Expression
| FunctionTypeDeclaration Ast.Helpers.Name Ast.Statement.Type
| ImportStatement Ast.Helpers.ModuleName (Maybe.Maybe Ast.Helpers.Alias) (Maybe.Maybe Ast.Statement.ExportSet)
| InfixDeclaration Ast.BinOp.Assoc Int Ast.Helpers.Name
| ModuleDeclaration Ast.Helpers.ModuleName Ast.Statement.ExportSet
| PortDeclaration Ast.Helpers.Name (List Ast.Helpers.Name) Ast.Expression.Expression
| PortModuleDeclaration Ast.Helpers.ModuleName Ast.Statement.ExportSet
| PortTypeDeclaration Ast.Helpers.Name Ast.Statement.Type
| TypeAliasDeclaration Ast.Statement.Type Ast.Statement.Type
| TypeDeclaration Ast.Statement.Type (List Ast.Statement.Type)
+ type Statement
= Comment String
| EffectModuleDeclaration Ast.Helpers.ModuleName (List (Ast.Helpers.Name, Ast.Helpers.Name)) Ast.Statement.ExportSet
| FunctionDeclaration Ast.Helpers.Name (List Ast.Expression.Expression) Ast.Expression.Expression
| FunctionTypeDeclaration Ast.Helpers.Name Ast.Statement.Type
| ImportStatement Ast.Helpers.ModuleName (Maybe.Maybe Ast.Helpers.Alias) (Maybe.Maybe Ast.Statement.ExportSet)
| InfixDeclaration Ast.BinOp.Assoc Int Ast.Helpers.Name
| ModuleDeclaration Ast.Helpers.ModuleName Ast.Statement.ExportSet
| PortDeclaration Ast.Helpers.Name (List Ast.Helpers.Name) Ast.Expression.Expression
| PortModuleDeclaration Ast.Helpers.ModuleName Ast.Statement.ExportSet
| PortTypeDeclaration Ast.Helpers.Name Ast.Statement.Type
| TypeAliasDeclaration Ast.Statement.Type Ast.Statement.Type
| TypeDeclaration Ast.Statement.Type (List Ast.Statement.Type)Summary
Hopefully, you can now see the benefits that Elm provides:
- Great language guarantees like immutability and static typing
- Being able to write code that is more maintainable thanks to the power of functions and type inference
- (Best of all) a developer-friendly compiler
We've seen how the compiler messages help you debug an application and correct syntax errors. We've even seen how they can speed development of new features or refactor a code base through compiler-driven development.
At this point, I hope you explore Elm further and start working on your very first Elm application. Again, I would suggest picking some small part of your existing code base that might lend itself to Elm's strengths. Visiting the official tutorial and the Elm slack channel will help you on your journey.
As you use Elm more, I believe you'll want to write all your client-side code in this great language!
Thanks go out to the reviewers of this article, most notably Mark Volkmann and Nathan Tippy.
Please send feedback to haast@objectcomputing.com.
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
