J2SE 1.4 New IO API
By Todd Stewart, OCI Principal Engineer
December 2002
Introduction
The final release of Java Specification Request (JSR) #51 introduces APIs for scaleable I/O, fast buffered binary and character I/O, regular expressions, and charset conversion. These new APIs introduce four new abstractions:
This article will look at each of these abstractions, discuss the motivation for using the new I/O (NIO) APIs, and examine the performance characteristics of an NIO enhanced log parsing application.
Why use the New I/O APIs
There are several motivating reasons to start using the NIO APIs:
- You are a Java or C/C++ network programmer interested in writing high-performance, scalable, and portable socket applications.
- You require improved performance and control when reading and writing data to and from files.
- You desire more sophisticated pattern recognition using regular expressions.
Buffers
A Buffer is a fixed-length container for a sequence of primitive data types (byte, int, short, etc.). Buffers are used throughout the NIO APIs. Buffer is the base class for all types of buffers. There is a specialized buffer class for each primitive data type.
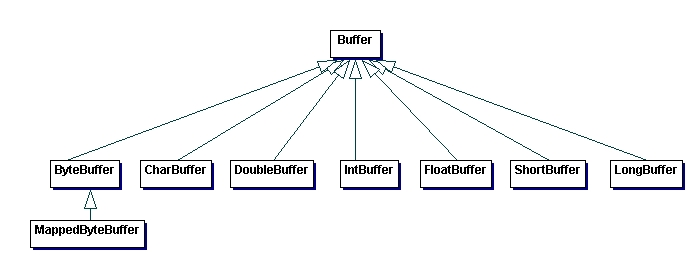
Buffers are designed to be an efficient mechanism for storing and manipulating primitive data types.
Manipulating Strings tends to create a lot of garbage because many temporary objects are created that must be collected by the garbage collector. In high-performance server applications, this can be a noticeable problem due to the overhead of the garbage collector.
Since buffers, in contrast, are a fixed size, they can significantly reduce the amount of garbage produced and, in turn, reduce the amount of work the garbage collector must do.
Buffers can also be declared as direct, which attempts to make use of the operating system's native I/O mechanisms. Direct buffers can be very efficient at moving and copying data because the Java VM is not involved. Since direct buffers have higher allocation and de-allocation costs than non-direct, you should use direct buffers for large, long-lived buffers.
It is also possible to map a region of a file directly into memory using a MappedByteBuffer. This can provide significant performance gains for certain types of applications.
Using Buffers
A buffer has a position, limit, and capacity.
- The position is the index to the next element to read or write.
- The limit is an index of the "virtual end" of the buffer. Attempting to read past or write beyond the limit results in an exception.
- The capacity is the size of the buffer measured in bytes.
When a new buffer is instantiated, the position is zero and the limit is set equal to the capacity.
Buffer buf = new ByteBuffer(10);
As data is written to the buffer (e.g., from a socket or a file), the position is incremented.
buf.putByte(0xBE);
buf.putShort(0xEFEE);
Once data has been inserted into a buffer, it cannot read it until the position is moved back.
Use the flip() method to set the limit to the current position and reset the position to the start of the buffer.
buf.flip();
A call to get() will return the three bytes between position and limit.
There are other methods to change the position and limit attributes.
- Clearing (
clear()) sets the position to zero and the limit to its capacity so it can be used like a new buffer (Note: the data is not cleared out). - Calling
mark()will set the mark at the current position. - Use
reset()to reset the position to a previously marked position.
Character Sets
A character set provides adapters (decoders and encoders) for translating between a sequence of bytes and 16-bit Unicode characters.
The Charset class is a factory of decoders and encoders for a named character set (e.g., US-ASCII, ISO-8859-1, UTF-8, etc.). A decoder transforms bytes in a specific charset into characters, and an encoder transforms characters into bytes.
The Charset class also provides encode and decode convenience methods, which simply delegate the request to a coder.
- A decoder accepts a
ByteBufferand returns aCharBuffer. - An encoder accepts a
CharBufferorString(which is adapted into aCharBuffer) and returns aByteBuffer.
Channels
A channel is a new abstraction that represents an open connection to an entity capable of performing I/O operations, such as files and sockets.
A channel is either open or closed. They are intended to be safe for multithreaded access.
The I/O-capable classes (FileInputStream, FileOutputStream, Socket, ServerSocket, etc.) in the existing java.io package have been modified to return the underlying channel.
There are two categories of channel:
- File-based channels
- Channels capable of multiplexed, non-blocking I/O (e.g., sockets)
All channels implement the Channel interface.
- A
ReadableByteChannelreads bytes from the channel into aByteBuffer. - A
ScatteringByteChannelreads bytes into a sequence of buffers, filling each buffer in turn. - A
WritableByteChannelwrites bytes to the channel from aByteBuffer. - The
GatheringByteChannelwrites bytes to the channel from a sequence of buffers, emptying each one in turn.
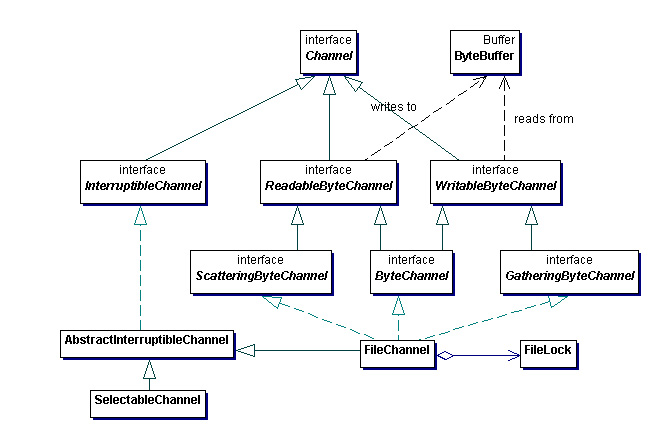
File Channels
File channels support reading and writing to the underlying file.
FileChannel implements the scattering, gathering, and byte channel interfaces and is interruptible. Since FileChannels are not selectable (see Selectable Channels), they cannot be used for non-blocking I/O. They do support some advanced features that were previously only available to C programmers:
- A file can be mapped into memory, which may provide better performance than the typical read or write methods.
- A region of a file may be locked to prevent access by other programs.
- The
FileChannelallows bytes to be transferred from one file to another file (via its channel). Many operating systems can perform this in a very efficient manner by transferring directly from the file system cache.
Selectable Channels
Multiplexed, non-blocking I/O is possible by using selectable channels and selectors. This type of I/O is more scalable and efficient than the standard thread-oriented, blocking I/O.
Traditionally, to serve multiple client connections, a thread is allocated for each connection. This solution wastes system resources, since threads are expensive to create and manage, and, in this case, tend to wait on I/O most of time.
When using a selector and any number of non-blocking channels (each representing a client connection), a single thread can handle all incoming requests. In this model, long running transactions can degrade quality of service. When this is an issue, a pool of worker threads can be used to handle simultaneous requests.
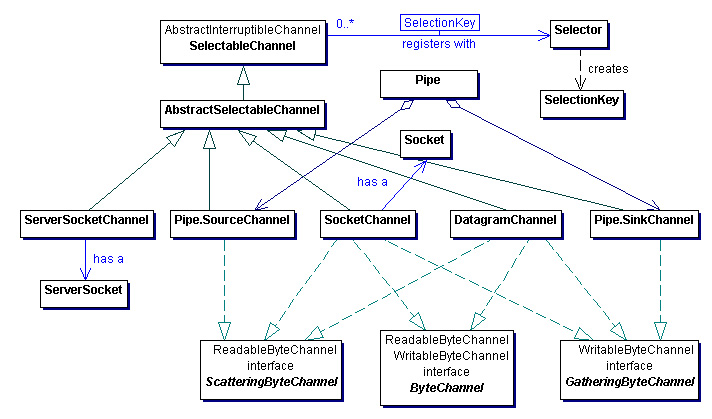
Selectors
A Selector acts as an I/O manager that keeps track of all the registered channels. When one or more channels become ready for I/O, a set of selection keys are returned indicating which channels are ready and for what type of I/O operation (read, write, connect, or accept). It is up to the developer to iterate over the set and perform the appropriate operation for each channel.
There is a lot of excitement in the Java community about the support for multiplexed, non-blocking I/O. As such, there have been many good articles and examples written to show how to take advantage of these facilities. Refer to the References section for additional information.
Regular Expressions
The package java.util.regex contains classes for matching character sequences against patterns specified by regular expressions. For more information, refer to the Java New Brief (JNB) article: Regular Expressions in Java.
Log Parsing Application
In this section, we will look at a log parsing utility that interprets and gathers instrumentation data and generates statistics.
The initial version is resource intensive in terms of memory and CPU time. This will be compared to a modified version that uses some of the NIO facilities.
The application performs the following steps:
- Read in each line of the file
- Check if line contains instrumentation data
- Tokenize the line
- Create the data model objects
- Calculate statistics
- Generate a report
The initial version uses a BufferedReader to sequentially read the file from disk. The NIO version uses a MappedByteBuffer to directly map the log file into memory. The expectation is that the new version will exhibit better performance.
The initial version uses a BufferedReader that wraps a File object:
- BufferedReader reader = new BufferedReader(new FileReader(theFile));
- String line = null;
- while((line = reader.readLine()) != null) {
- // process the line
- }
The NIO version gets a FileChannel from the input stream and maps the file into memory by creating a MappedByteBuffer.
- // Open the file and then get a channel from the stream
- FileInputStream fis = new FileInputStream(theFile);
- FileChannel fc = fis.getChannel();
-
- // Map the entire file into memory
- int size = (int)fc.size();
- MappedByteBuffer bb = fc.map(
- FileChannel.MapMode.READ_ONLY, 0, size);
To read a line from the byte buffer, the buffer needs to be decoded into characters and split into lines by searching for the new line character(s). One way to do this is convert the entire byte buffer into a character buffer, create a regular expression to match a line, and iterate across the buffer.
- // Regular expression pattern used to match lines
- Pattern linePattern = Pattern.compile(".*\r?\n");
-
- // Decode the file into a char buffer
- CharBuffer cb =
- Charset.forName("ISO-8859-15").newDecoder().decode(bb);
-
- // Create the matcher and iterate over the buffer
- Matcher lm = linePattern.matcher(cb);
- while ( lm.find() ) {
- String line = lm.group();
- // process the line
- }
This new implementation was slower than the initial version. After profiling the code (using Java's profiler), this solution required significantly more memory due to decoding the entire file into a character buffer.
In addition to the memory increase, a significant amount of time was spent executing the group method that returns the string matched by the find.
An alternative is to create a Reader from the channel using the Channels utility class.
- BufferedReader reader =
- new BufferedReader(Channels.newReader( fc, "ISO-8859-15" ) );
- String line = null;
- while((line = reader.readLine()) != null) {
- // process the line
- }
This solution performed better than the line matcher approach but did not show an improvement over the original buffered-reader approach.
In general, the original buffered-reader approach suffers from creating many temporary objects and demanding a lot of memory. The simple attempt to improve the application by mapping the file into memory did not improve the performance.
A more complete solution is to concentrate on reducing the number of temporary objects and making use of direct buffers when possible. This example demonstrates that memory-mapped files are not going to improve performance of sequentially accessed, line-based data.
Memory mapped files, however, can be much more efficient when dealing with large binary data sets or randomly accessed data. This is because the operating system handles the paging of the data and can perform very fast copy and move operations.
Test Results
The tests were run on a Windows 98 machine with JRE 1.4.1_01, a Sun Solaris 2.8 machine with JRE 1.4.0_01, and a Linux machine with JRE 1.4.1. Some tests were run using the -server option which enables the server HotSpotTM VM. Times are in milliseconds.
| File Size | Buffered | Mapped |
|---|---|---|
| 4M | 26475 | 26827 |
| 1.5M | 10790 | 11935 |
| 500K | 5190 | 5446 |
| 100K | 2082 | 2300 |
| File Size | Buffered | Mapped | Buffered (-server) | Mapped (-server) |
|---|---|---|---|---|
| 4M | 20984 | 24626 | 40437 | 37312 |
| 1.5M | 9658 | 11145 | 26124 | 24377 |
| 500K | 5512 | 6241 | 13990 | 13625 |
| 100K | 2768 | 3444 | 5364 | 5590 |
| File Size | Buffered | Mapped | Buffered (-server) | Mapped (-server) |
|---|---|---|---|---|
| 4M | 9254 | 10578 | 9084 | 9935 |
| 1.5M | 3843 | 4474 | 4996 | 5640 |
| 500K | 1795 | 2095 | 3188 | 3393 |
| 150K | 883 | 1001 | 1488 | 1676 |
For all test cases, the buffered I/O was faster than the memory-mapped file. The memory-mapped solution was from 2% to 20% slower.
For nearly all test cases, the server HotSpot™ performed worse, especially on Linux. The one exception is the 4M file on Solaris.
An interesting note is when running with the server HotSpot™ on Linux, the memory mapped solution performed better for file sizes 500K and above.
Summary
The NIO APIs introduce facilities for scaleable I/O, fast buffered binary and character I/O, regular expressions, and charset conversion. They are not intended to replace but to augment Java's current I/O.
The Java community is excited because some of these capabilities were only available to C programmers (e.g., multiplexed, non-blocking I/O, file locking, and memory-mapped files). This will likely enable the migration of high-performance C applications to the Java platform with similar performance characteristics.
References
- [1] JSR 51 - New I/O APIs for the Java™ Platform
http://jcp.org/en/jsr/detail?id=051 - [2] Master Merlin's new I/O classes
http://www.javaworld.com/javaworld/jw-09-2001/jw-0907-merlin.html - [3] Java™ 2 Platform, Standard Edition (J2SE™), Version 1.4 Overview
http://developer.java.sun.com/developer/technicalArticles/releases/j2se1.4 - [4] Non-Blocking Socket I/O in JDK 1.4
http://www.owlmountain.com/tutorials/NonBlockingIo.htm - [5] Regular Expressions in Java
https://objectcomputing.com/resources/publications/sett/regular-expressions-java - [6] Put Java in the fast lane
http://www.javaworld.com/javaworld/jw-08-2002/jw-0802-performance.html - [7] The Java Developers Almanac 1.4
http://javaalmanac.com/ - [8] New I/O (NIO) APIs (JavaLive Transcript)
http://developer.java.sun.com/developer/community/chat/JavaLive/2002/jl0919.html
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
