Hyperledger Fabric Myths and Reality
By Lance Feagan, OCI Senior Software Engineer
April 2020
Introduction
The market consensus is that Hyperledger Fabric is the market leader in enterprise blockchain. Looked at more broadly through the recent Forbes Blockchain 50 [1], Fabric is the number one platform, followed closely by Ethereum, with Corda a distant third place.
The diverse set of companies using Fabric proves its bona fides in the enterprise. There are, however, a number of technology-related myths and hidden sharp edges that architects and business leaders looking to adopt Fabric should be aware of when planning.
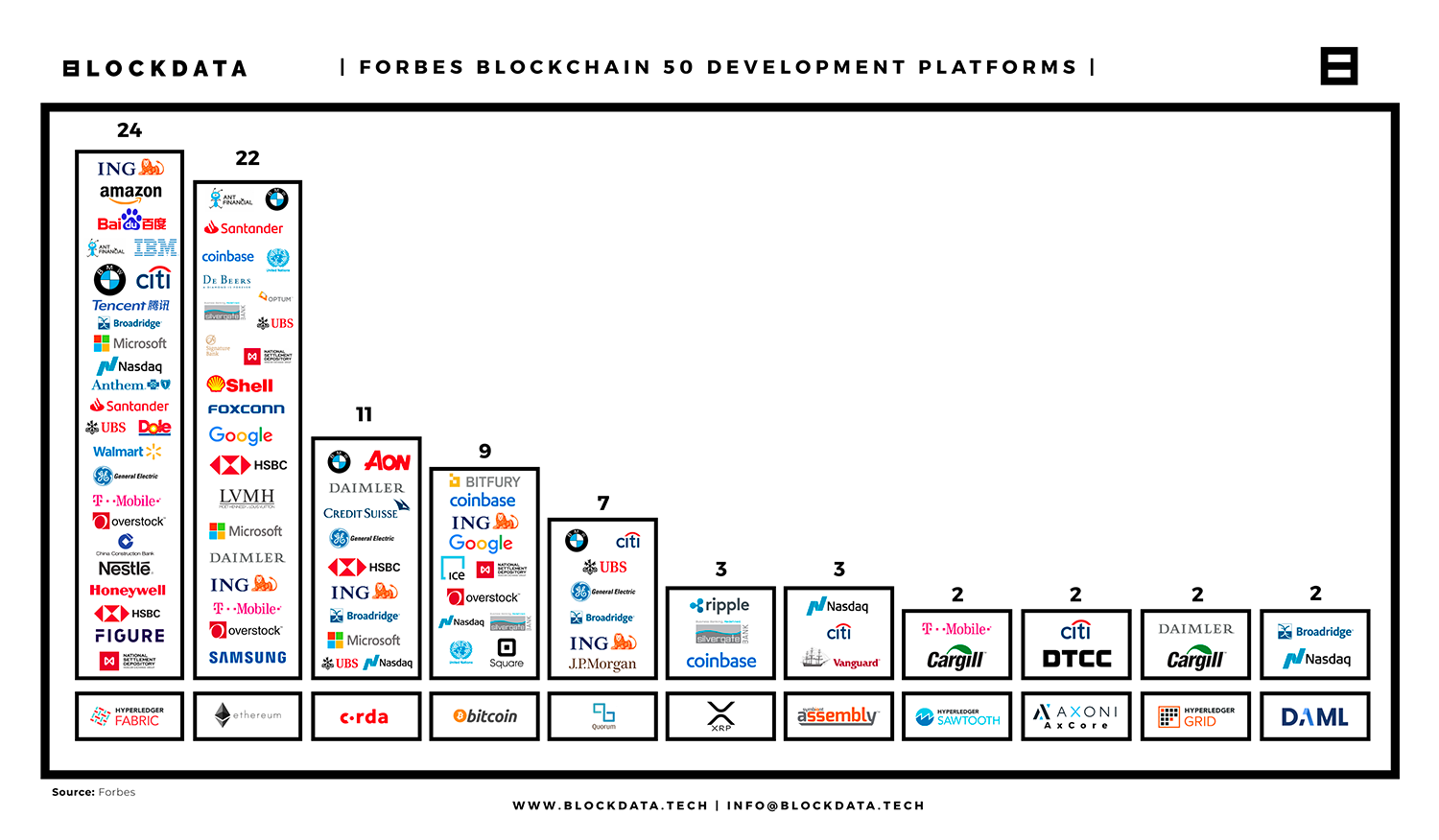
Figure 1. Blockchain 50 Data Deep Dive [2]
The motivation for this presentation is to help others avoid – or prepare solutions to overcome – the challenges I experienced in the last four years using Fabric to create solutions and develop the ledger itself. Through frequent presentations on Fabric internals, I have had good discussions about the unique design and operation aspects of Fabric that universally surprise those familiar with other blockchain systems.
Through this paper, I hope to accomplish three things:
- Illuminate areas where those unfamiliar with Fabric’s inner-workings will run into trouble
- Slice through marketing with x-ray vision to help you make a clear-eyed decision
- For each potential limitation in the as-is product, show you how it can be designed or coded around, thanks to Fabric’s flexible, modular design.
At the end of the day, in spite of a few rough edges, I strongly feel Fabric is the best of the first wave of enterprise blockchain systems.
Figure 2. [3]
Myth 1
Support for Node.js & Java SDKs means that I can develop applications using modern web application development technologies and patterns.
Most modern applications use a three-tier architecture with an application server acting as the middle tier—supplying an HTTP API and business logic called by the web client. Current best practice application servers often implement this MVC architecture using Node.js or Java. With Fabric support for these languages, it is all too easy to conclude that an MVC architecture can be employed when crafting a solution.
While a Fabric application can be developed in this way for demonstration purposes, in practice, the security implications of this will likely prove unacceptable to any party interested in the security afforded by blockchain.
Non-repudiation is the first tenet any secure system should afford. This means we should be able to positively assert that if a transaction is signed using Alice’s private key, that no other party could have signed for her, and therefore she cannot deny her involvement and responsibility.
By introducing an application server responsible for signing transactions, we have delegated this responsibility to a third party and can no longer confidently assert Alice’s involvement. The application server, as the business logic implementer, also serves as a custodian of Alice’s private key to sign transaction on her behalf.
Remediation
In Fabric, applications primarily address B2B needs. As such, each organization may have an internal application server that authenticates local users and signs blockchain transactions using the organization’s identity, rather than that of an individual. Ultimately, as each organization is responsible for the actions of its members, this should be equivalent from a partner’s perspective. Internally, the organization should keep careful audit records of internal users performing actions on the blockchain to determine responsibility.
Alternatively, a more traditional two-tier architecture can be used, by developing a native application to be run on a desktop or mobile device. A native application can interact with a local secure enclave or HSM to sign transactions. If a lightweight, web-friendly application delivery mechanism must be provided, an alternative, such as use of a CloudHSM or VirtualHSM with multi-party computation for signing, can be utilized.
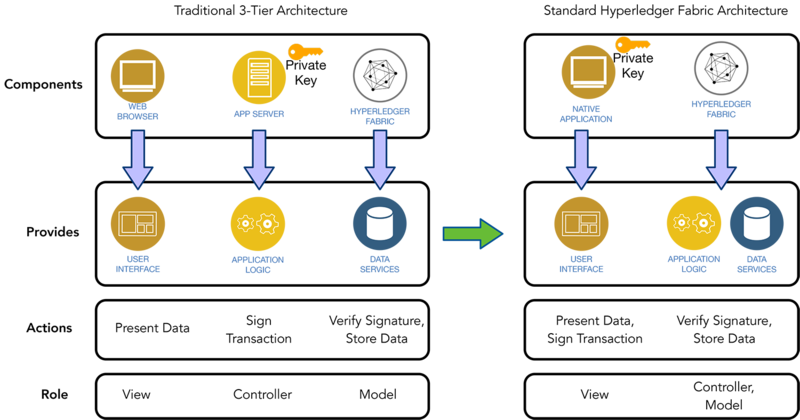
Figure 3. On the left we have a traditional three-tier architecture: web browser, application server, and Fabric. The browser provides the UI, the app server contains the business logic, Fabric provides smart contracts and DB. Often, this business logic implements privacy or access control rules that cannot be trusted to run in the browser client. If we move to a two-tier architecture, this logic will need to be fully contained in the smart contract code.
Myth 2
With Fabric chaincode support for Node.js and Java, a language practitioner can successfully create smart contracts.
Fabric support for developing smart contracts in Node.js was added in version 1.1, released in early 2018, and for Java in version 1.3, released in late 2018. But, most importantly, Fabric 1.4.0, released in early 2019, introduced an improved programming model for Node.js and later Java with 1.4.2. These improvements have obviated the need for Composer by baking modeling abstractions into the smart contract language and have been a significant boost to developer productivity, code readability, quality, and maintainability.
However, there are many areas where developers will need to understand the Fabric transaction model to optimize performance. Just as with many other blockchain systems using key-oriented ledgers, having a "fat" value that may be modified for more than one reason can significantly impair performance. Much like Robert C. Martin’s single responsibility principle, each row should be narrowly aligned with its purpose. A row serving multiple functional areas will become a "hot" row with high potential for write conflicts. With Fabric, if multiple transactions are updating a particular key within a batch (a block antecedent), all transactions subsequent to the first will be rejected, as the read-set key version no longer matches.
The solution is to decompose the asset value into finer-grained pieces stored at different keys. In this way, multiple pieces can be manipulated independently as part of a single batch.
As a simple example, consider a company that manages a fleet of vehicles. The original data model might have a single company asset with a nested JSON array-of-documents storing each vehicle’s maintenance and usage information. If done in this way, only one vehicle can be updated per-block. However, if each vehicle is stored as a separate row (key), each can be updated independently in a single batch. A suitable key can be generated by combining the company id with the vehicle id in a way that yields a unique value.
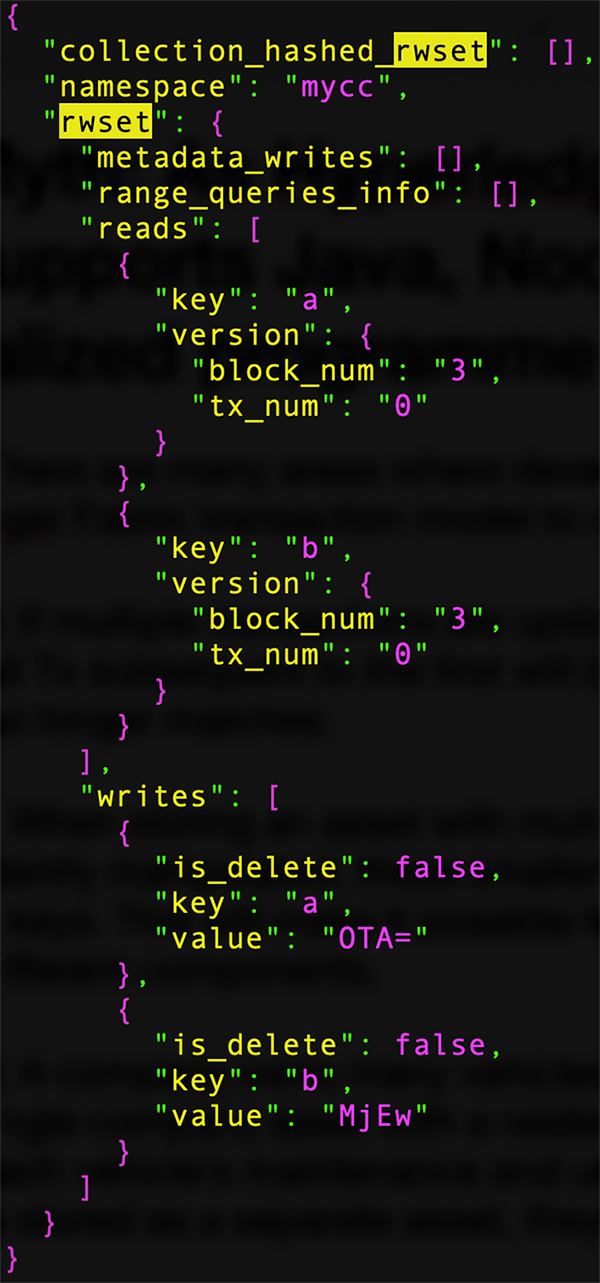
Figure 4. Fabric ReadWrite Set Example
Myth 3
"No ledger data can pass from one channel to another."
This myth above is a direct quote from the Fabric 1.4 channel documentation and is simply untrue. The reality is that while cross-channel transactions cannot write data to another channel, data can be read. Put simply, even if a cross-channel write is "performed" as part of simulation, it will not appear in the read-write set (RWSet), and therefore will not appear in the ledger as part of the commit process.
As proof that cross-channel reads can be done, let us briefly look at the development of the inter-bank payment system for the Monetary Authority of Singapore as part of Project Ubin; the cross-channel funds transfer process relied on this capability existing.
In figure 5 below, we have three channels: one for banks 1 and 2 talking, one for banks 1 and 3 talking, and one for anonymous fund transfers.
The reason we divide banks into bi-lateral channels is to avoid revealing total liquidity to other banks. This introduces the problem of not having enough liquidity in a bi-lateral channel to service a fund transfer request. To resolve this, we need to re-balance the liquidity of a bank by moving funds between bi-lateral channels. To avoid funds creation, we define the concept of anonymous funds transfer.
In the funds transfer process example shown in figure 5, bank 1 is moving funds from its channel to talk with bank 2 to instead talk with bank 3. At each step, either bank 2 or bank 3 acts as a “guard” to ensure no funds are created or destroyed by bank 1.
When the anonymous fund is created in the multi-lateral transfer channel, bank 2 performs a cross-channel read against the Bank1- Bank2 channel to verify creation. Similarly, when funds are imported into the Bank1-Bank3 channel, bank 3 performs a cross-channel read to the multi-lateral transfer channel to verify the fund amount.
To guard against misuse, additional “mutexes” lock the funds in the Bank1-Bank2 channel while the creation of the anonymous fund is taking place.
When initiating the transfer process, a pause is placed on the funds of bank 1. Then bank 1 creates the anonymous fund in the multilateral transfer channel. By pausing the bi-lateral channel activity, bank 2 can easily verify through a cross-channel read that bank 1 created the anonymous fund with the correct amount. After this step, the bi-lateral channel activity can be resumed.
If after creating the move-out anonymous fund (moveOutAF), bank 1 wishes to reverse the process, it can call the cancelMOAF method to credit back the money to its account. This might be done if sufficient funds become available in the Bank1-Bank3 channel to satisfy the transfer request.
Having created the anonymous fund, bank 1 now wants to move it in elsewhere. First it must “lock” the anonymous fund (lockAF) to the channel it is designated to move into. This prevents “double spend” by moving in to multiple channels. In the Bank1-Bank3 channel, the moveInAF method is called to credit bank 1’s account, with bank 3 verifying via cross-channel read that this was the channel designated for the receipt of funds.
Finally, to mark it as spent, the anonymous fund is cleared.
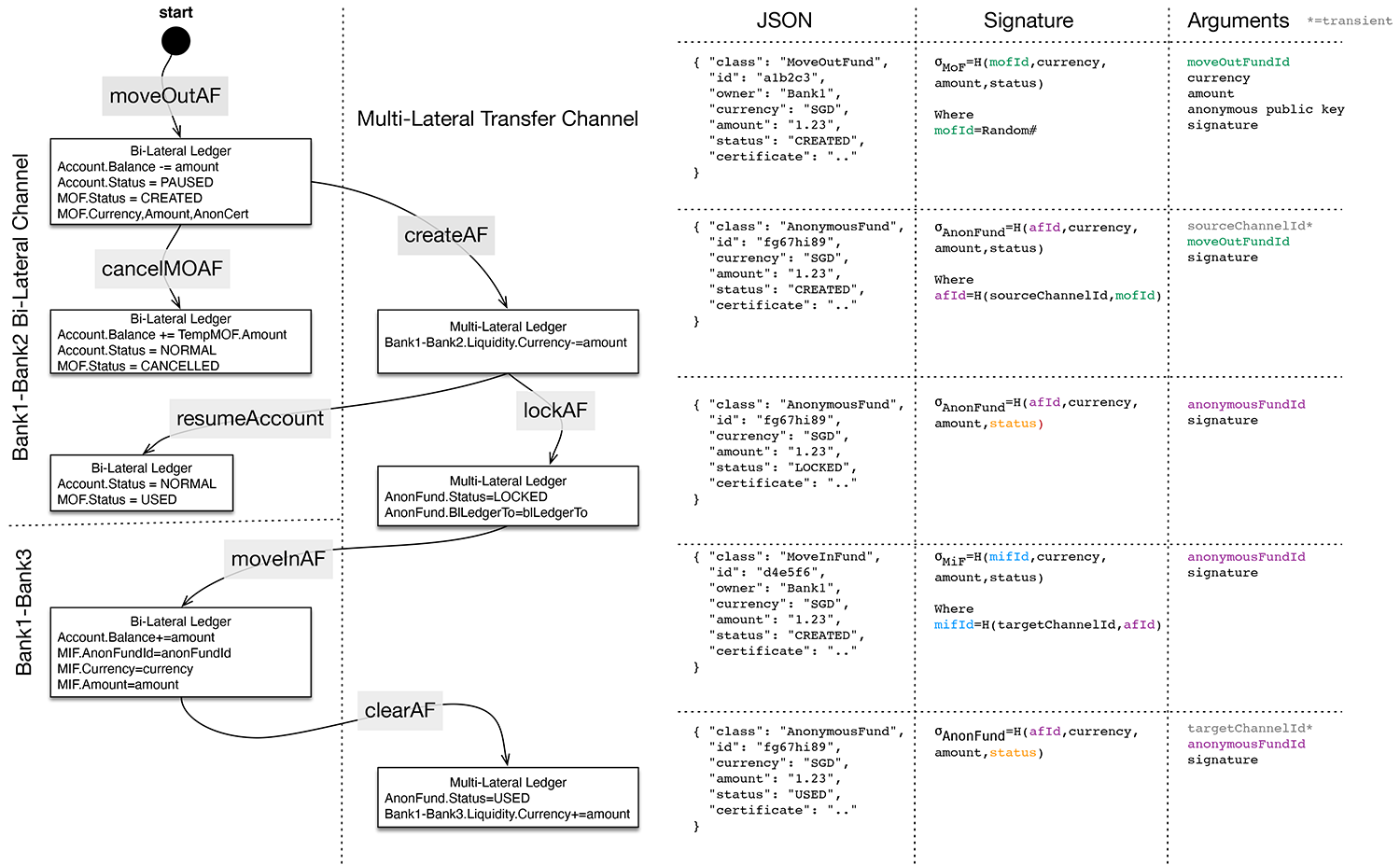
Figure 5. Anonymous Funds Transfer Process
Myth 4
Fabric’s support for heterogeneous databases via plugins means you don’t need to worry about what database you choose.
It is true that Fabric supports a pluggable database model with built-in support for LevelDB and CouchDB. However, if any smart contract uses the rich query feature of CouchDB as part of a smart contract, all peer organizations will likely also need to adopt CouchDB to successfully perform transaction simulation. In theory, a commit-only peer could still work because it does not need to run the smart contract.
Looking further into the future, as multiple networks merge, just as companies merge and subsequently seek to integrate and normalize IT systems, there will be a similar need for Fabric to support a migration path. Perhaps someday smart contracts will be written in a way to support multiple databases with chain code specific to the local flavor. This could come in the form of a layer, similar to Hibernate for relational databases, that performs object-relational mapping (ORM) and SQL query generation.
One vision of a system that implements this idea is the Digital Asset Markup Language (DAML). DAML is a functional language, inspired by Haskell, where users describe assets and business processes. DAML is relatively new, and time will tell if it is the correct answer. Either it, or something very similar, will likely be the end-game for smart contract development because it avoids storage and execution dependencies.
Until the market coalesces around a specific technology solution to abstract these issues, the best bet is to go
with CouchDB or another document-oriented database. This form of database can be mapped to other database models and provides greater flexibility to define indexes and perform analytics and other queries via database rather than requiring complicated logic be written by the chaincode. This abstracts away complex details and improves reliability.
Myth 5
The chaincode (channel) endorsement policy mechanism can be used to enforce transaction-related party endorsement.
The built-in chaincode (channel) endorsement-verification policy mechanism, introduced in Fabric 1.1, claims to enable transaction-related party endorsement. Recall, briefly, that the endorsement policy is a textual specification using boolean operators (AND, OR) and grouping via parenthesis to specify the endorsement organizations and roles that must be present in a transaction to be considered properly endorsed.
Here are some simple examples:
AND('Org1.member', 'Org2.member', 'Org3.member')OR('Org1.member', 'Org2.member')OR('Org1.member', AND('Org2.member', 'Org3.member'))
This built-in VSCC policy mechanism has two significant short-comings:
- It cannot be specified on a per-method basis.
- It cannot refer to arguments of the method.
If the policy could be selected on the basis of the method being invoked, we could have a single chaincode deployed where simple methods, such as a transfer between two participants, required only two endorsers, and a configuration-related method required a majority or all to endorse. If the policy could refer to method arguments, such as the organizations involved in the transaction, it could be more narrowly tailored to close a critical security hole.
To demonstrate this more clearly, let us consider a scenario wherein a channel contains three participants: Alice, Bob, and Charles, and a single smart contract has been deployed to manage the ownership of assets.
The channel participants primarily make use of a transfer method that takes two arguments: the asset id and the new owner.
To be properly endorsed, a transfer should be signed by a member of each organization participating in the transaction.
For example, if Alice is transferring an asset to Bob, it should be endorsed by (A & B).
Looking at all possible pairs, we can calculate the endorsement policy should be:
(A&B)||(B&C)||(A&C)
Written in Fabric’s Polish notation, we would have:
OR( AND(A.member, B.member),AND(B.member, C.member),AND(A.member, C.member))
While this policy clearly covers the transfer from Alice to Bob, it also must cover Bob to Charles and Alice to Charles, as they can also transfer assets. This means that potentially the transfer of an asset owned by Alice could be endorsed by Bob and Charles, forsaking Alice.
Thankfully, this clearly unacceptable situation has a solution—using golang to create a custom Verification System Chain Code (VSCC) policy that inspects the method and arguments to enforce meaningful business-level endorsement verification.
Myth 6
Channels address all of your data privacy challenges.
Fabric's channels, introduced with 1.0, were a first attempt at local data partitioning and physical isolation by providing a faculty that can ensure a set of data only traverses the networks of and is stored on the disks of a subset of the organizations that are members of the blockchain network.
The rationale was simple: banks and others with high-security transactions were uncomfortable with data, even when encrypted, being physically present on peers controlled by other organizations, unless necessary.
As shown in figure 6, below, after gathering the required transaction proposal endorsements, a client application submits the simulated and endorsed transaction for ordering, such as to a Kafka cluster. After ordering the transactions within a time window into a batch, the ordering service broadcasts the batch to all organizations committing peers to be verified and transformed into a block of valid transactions.
While the local data partitioning goal was achieved, the ordering service represents a single point of trust, as all transactions for channels it manages flow through it. The issue isn’t what is possible theoretically; it is what is practical when scaling a solution.
For a small, test network, having distinct ordering services for each channel is plausible and would provide the requisite data partitioning and isolation at both the peer and network level. At a practical level, for many scenarios, the overhead and multiplicity of ordering services that would be required is often impractical. The next myth fills us in on the details.
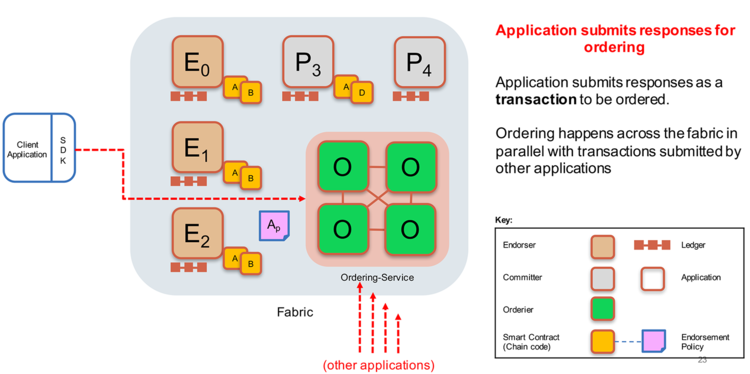
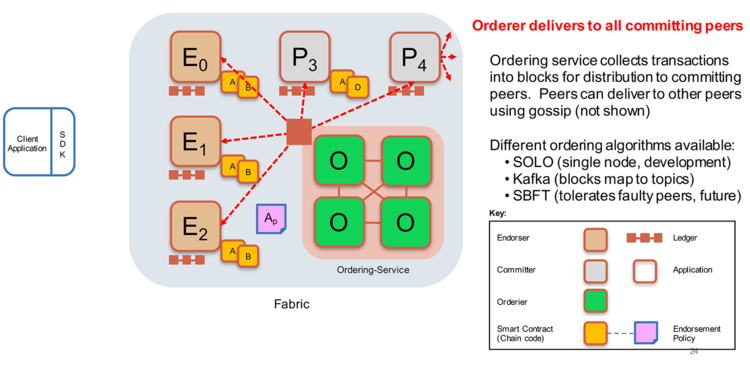
Figure 6. Ordering Service Process
Myth 7
Channels are free.
Continuing from myth 6, in many real-world scenarios, channels can multiply quadratically.
When creating the Inter-Bank Payment System (IBPS) for Singapore’s central bank, the Monetary Authority of Singapore, our network needed to support a little over 200 banks privately communicating with each other through bi-lateral transfer channels to ensure no information would appear in other organization’s ledgers. This meant that each bank had approximately 200 channels to "talk" with other banks, and each of those banks similarly had ~200 connections.
In graph theory, this is called a complete graph; in networking, it is a fully connected mesh topology. The number of connections is proportional to n2, and thus even in little Singapore, this results in over 20,000 channels.
In the United States, with nearly 7,000 banks, you would need over 20 million channels! The ordering service wasn’t designed to handle so many channels and becomes quite slow. For example, in a test network with 10
banks, you would have 45 bi-lateral channels. Creating these 45 channels takes 90 seconds—2 seconds per channel. For 20k channels, a rough time estimate would be 11 hours. For the USA with 20M channels, a rough estimate would be 1.5 years!
If you want to ensure complete channel isolation, you would need to operate 20k Kafka clusters! This just isn’t practical, and a better solution is required—private collections.
Myth 8
Private collection solves the channel explosion problem.
Given the shortcomings of channels, it should come as no surprise that the Fabric team started searching for a better solution shortly after the release of 1.0. The idea we settled on was originally called side channels, but became productized as private collections. This enables organizations to establish private databases that a subset of organizations are allowed to see. The transaction data from these is never sent through an external ordering service. So, although the ordering service is no longer a trust or performance problem, instead a peer-to-peer (P2P) network must be established between all organizations’ peers. These P2P private collections are defined in a JSON file, specifying the organization(s) that can see the contents.
This file will need to specify 20k pair-wise combinations of banks in the Singapore IBPS example. This change places more burden on the network administrators to appropriately define the routes and private networks, perhaps VPNs, to create a secure foundation for communication. So, although burdensome, this all sounds good.
Figure 7, below, shows an example of this JSON document. As new banks are added, removed, or merge, this document would need to be updated to match the new configuration.
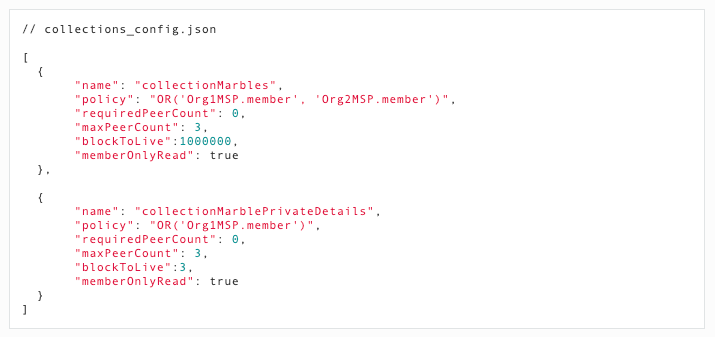
Figure 7. Fabric Private Collection Policy Definition
Myth 9
Data privacy is easy.
Continuing with the theme of data privacy, even with channels or private collections, the act of slicing up your overall asset pool into hundreds of bi-lateral partitions introduces its own challenges.
Returning to the IBPS example, if you divide your bank’s overall liquidity one-hundred fold to avoid other network participants having a total view of your liquidity, it is now more difficult for you to access it all at any one time. Simple acts like computing your total liquidity require cross-channel or collection queries. When performing a transfer, it is now much more likely that insufficient liquidity will be available in a given channel or collection.
To resolve this, money must be transferred from another private collection in a way that ensures no funds are created/destroyed in the process while preserving privacy. And, unfortunately, there are other caveats. To deal with ordering and read-write set MVCC consistency, the public transaction used to record the private transaction occurring must include the read-set keys. Therefore, if you are in a situation where even revealing that there has been activity on a particular key is unacceptable, you will need to salt+hash the key to avoid revealing this to others. The salt used for a particular key will either need to be stored off chain or as a value in another row that enables lookups. Only by blinding the key can we prevent other organizations from becoming aware of activity. To deal with all of this requires that you hire smart programmers familiar with cryptography and distributed systems, specifically multi-party algorithms or homomorphic encryption, to develop custom solutions.
Myth 10
Fabric is easy to administer.
Fabric, in contrast with other blockchain systems, has many components that an administrator must become familiar with to operate—peer, CouchDB, ordering service (Kafka, zookeeper, raft), memberships services provider, docker. It also requires specialized routing and firewall rules to establish secure communication links between organization peers, MSPs, and the ordering service. Additional administrators will need to be involved with management of a multi-organization certificate authority (CA).
To resolve this, IT network engineers must work as part of a consortium to determine the appropriate way to expose their peers to other organizations to receive transaction endorsement proposal/simulation requests while minimizing an attacker's ability to gain access to sensitive information stored in the simulating peer’s database.
One way to simplify this effort is to co-locate all organization’s peers within a single data center or provider, such as AWS, Azure, or IBM. Of course, being in a single availability zone (AZ) is a risk unto itself. When dealing with mission-critical systems accessing core records, you need a team of highly-skilled network engineers and systems administrators onboard to plan appropriately.
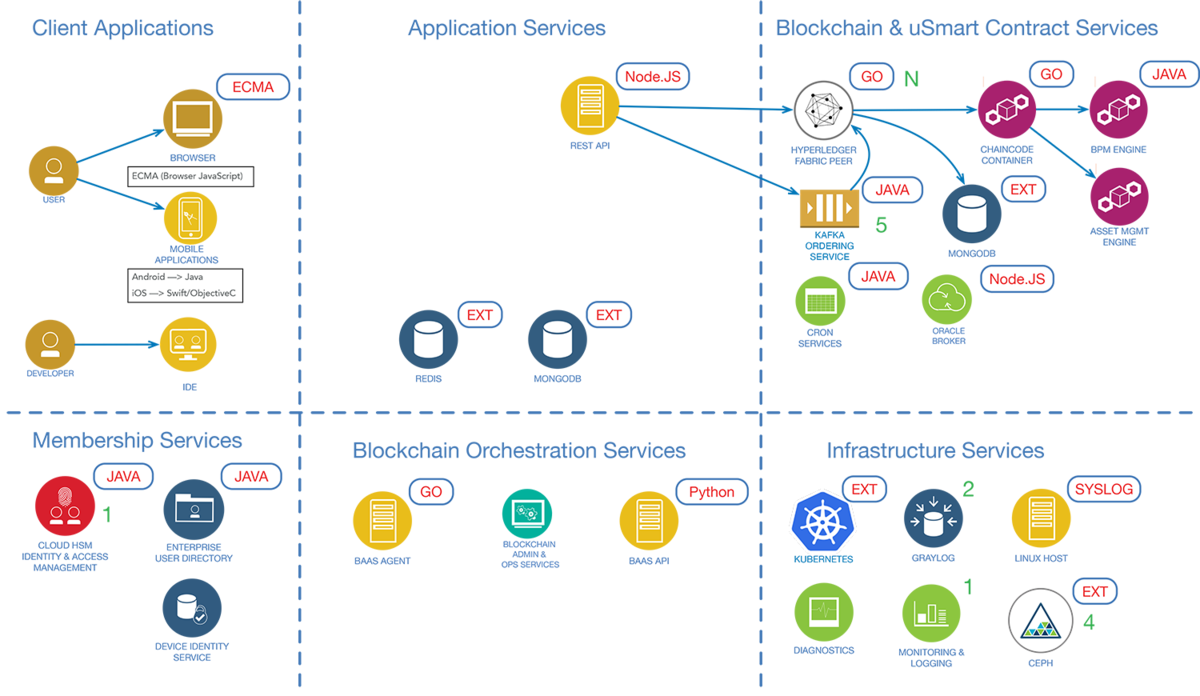
Figure 8. Typical Fabric Components
Myth 11
Clusters don’t need backups.
Fires. Earthquakes. Tornados. Lightning. Floods. Hurricanes. Disasters happen. If all Fabric peers are in the same data center/locale and suffer a direct hit, only a remote backup will be sufficient for recovery.
Crypto ransomware is ever present and a blockchain system is a prime target. If all online volumes are encrypted, having an offline backup prior to the attack provides the option to reject paying the attacker’s ransom demands without complete data loss.
Even in less disastrous scenarios, recovery by replaying the block log from the genesis block can be painfully slow. Private collections complicate this further, as it is insufficient to perform a backup at a single peer. Each organization may have a unique set of private data not fully available at any other peer. For example, if private collections exist A+B, B+C, and A+C, then each organization should be performing independent backups, although not necessarily at the same time.
Sadly, the Fabric team does not agree that backups are a necessity.
There are two strategies for backup: offline and online. If you can take a peer offline temporarily, this is the easiest option. If you are using private collections, remember that all organizations with unique access to a private collection will need to perform a backup.
To perform an online backup, we must have a consistent version of all blocks, indexes, and logs. A no-code solution is to use LVM and volume snapshots. A better solution is to pause Fabric processing commits and to use a native backup tool for the database to ensure a consistent restore point.
Further Details: http://www.bchainledger.com/2019/02/hyperledger-fabric-ledger-backupand.html
Myth 12
Fabric needs few network and hardware resources to operate.
All blockchain systems are, in essence, unbounded, append-only logical logs. Storing all data from the genesis block onward and maintaining it has a non-trivial cost.
One way to mitigate this cost in a production deployment is to use hierarchical storage to reduce the cost of storing old blocks. To increase the value of storing old blocks, the history API should be enabled so that users can access records that aid in fraud detection, KYC, AML, and similar efforts.
The ordering service is a significant source of network congestion. All transactions must flow into it one time and are replicated out to "N" organizations. This problem grows quadratically with the number of organizations. If N is the number of organizations and T is the number of transactions per second per organization, the total transactions per second being handled by the ordering service is given by the formula:
This problem is somewhat mitigated by organizations using gossip to replicate between peers within an organization.
The long term solution to this problem is to have a gossip-based transaction-distribution mechanism to eliminate the need for the ordering service to directly talk with all organizations.
Conclusion & Final Thoughts
Many of the issues discussed herein have analogs in other blockchain systems. As enterprises look to blockchain, they need to think as deeply about organizational issues as they do technical ones. Adopting blockchain is not simply about running a parallel database mirroring existing OLTP systems—it is about developing new models for business made possible through enhanced trust and information sharing. Technologically, blockchain makes this
possible through a common view of information, non-repudiation of transactions, and access
to immutable historical information.
Leaders are encouraged to consider issues such as:
- Will users transact as themselves, or will transactions be signed by the organization they are acting on behalf of?
- Will you organically grow, hire, or contract expertise in Fabric to deploy smart contracts that are performant and secure?
- How are you going to design effective smart contracts that create true counter-parties that have a vested interest in holding others responsible?
- Looking to the future of the business, how should systems be architected to deal with the possibility of systems integration due to mergers and divestment?
- When acting as part of a consortium, what is the governance model that will be used for smart contract development?
- How will core systems be exposed to other organizations as required for peer endorsement?
In answering these questions, leaders should recognize that experience matters, both with blockchain and with the domain they operate in. The journey to blockchain adoption is a marathon, and they should start to build in-house experience today, especially for DevOps and networking.
Adopting Fabric or any blockchain system as an integral part of a business requires thoughtful analysis to maximize the ROI. Existing efforts at digitalization and a concrete understanding of existing business processes are critical to success.
When Fabric 1.0 was being designed, it was not clear what the emerging business model requirements would be. The hope was to be sufficiently flexible to provide a good starting platform given broad configurability and modularity. As the most enterprise-ready of the first wave of blockchain products, there are few situations for which Fabric cannot be adapted. Successful adoption requires significant expertise in network security and routing, cryptography, game theory, databases, containerization, and distributed computation. Just as Rome was not built in a day, nor will the future of business in blockchain.
How to eat an elephant? Grab an ear and get chewing!
References
- 1. Forbes Blockchain 50
https://www.forbes.com/sites/michaeldelcastillo/2020/02/19/blockchain-50/ - 2. Forbes Blockchain 50 Data Deep Dive
https://medium.com/blockdata/forbes-blockchain-50-data-deep-dive-117fc230822f - 3. Fabric 1.4 Architecture Reference: Channels
https://hyperledger-fabric.readthedocs.io/en/release-1.4/channels.html
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
