Serverless Solutions on AWS Part 1
By OCI Software Development Team
-
Tino Nwamba, Principal Software Engineer
Wallace Zhang, Senior Software Engineer
Jeremy Plack, Software Engineer
Patrick Wilson, Project Manager
August 2018
Introduction
“Serverless computing” is an interesting phrase. After all, if computing is to occur, there must be a place where it happens.
No small amount of ink has been spilled about this subject, but we feel that Mike Roberts provided an excellent description of serverless architecture when he wrote that “the difference [with serverless architecture] compared to normal approaches is that the organization building and supporting a 'Serverless' application is not looking after that hardware or those processes. They are outsourcing this responsibility to someone else.”
Within the broader context of serverless architecture, there are a couple different approaches one might take.
One approach is a hybrid serverless model that calls some specific serverless functions, while maintaining other persistent services, either on-premise or on dedicated cloud compute resources. This strategy is often adopted to work around certain limitations inherent in AWS Lambdas or Google Cloud Functions.
In many cases, companies enter this hybrid state as they incrementally transition to a pure serverless architecture over time.
A pure, serverless cloud infrastructure is a solution that provides compute resources on an on-demand basis without the costs of persistent infrastructure and the monitoring and management of "operations" personnel.
The advantages of this architecture are clear, but keep in mind that the serverless approach we describe below is not the right fit for every workflow. As a company moves into the cloud, a number of factors go into determining the best approach, and cloud solutions are best developed on a case-by-case basis.
We recently completed a project for a client using a serverless architecture to maximize scalability and value.
Our design was guided by the Amazon Web Services (AWS) Well-Architected Framework, a framework of five pillars that helps businesses create a cloud strategy that is stable, scalable, secure, and efficient.
The AWS Well-Architected Framework
The five pillars of the AWS Well-Architected Framework are as follows.
1. Operational Excellence
The operational excellence pillar includes the ability to run and monitor systems to deliver business value and to continually improve supporting processes and procedures.
2. Security
The security pillar includes the ability to protect information, systems, and assets while delivering business value through risk assessments and mitigation strategies.
3. Reliability
The reliability pillar includes the ability of a system to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues.
4. Performance Efficiency
The performance efficiency pillar focuses on the efficient use of computing resources to meet requirements and ways to maintain that efficiency as demand changes and technologies evolve.
5. Cost Optimization
The cost optimization pillar includes the ability to avoid or eliminate unneeded cost or suboptimal resources.
The Project
Our client approached us with a desire to build an application that would grant easy access to data compiled by various business units to all parties throughout the organization, as well as select external partners.
Development of such an application presents a number of technical challenges:
- Data must be exposed to external partners in a way that grants access solely to the data they are authorized to view.
- The service needs to be reliable and fault tolerant, able to recover from interruptions.
- Data coming from different business units may be in different formats, but must be consolidated and standardized into a consistent and highly available data catalog for querying.
- The ideal solution should have minimal operational overhead.
- The components that comprise this solution should be loosely coupled and cloud agnostic to prevent vendor lock-in.
In addition to addressing the above challenges, our goal was to architect an open-data framework that met or exceeded the client's needs, driven by the following objectives:
- Follow AWS best practices
- Follow security best practices
- Follow AWS caching best practices
- Use
- A REST API design pattern
- Serverless technology
- Loose coupling, high cohesion design practice
- Reusable components
- Open source technology
- Perform data analysis using AWS services and best practices
- Document APIs using Swagger open source software
Here is an overview of the architectural diagram used for the project.
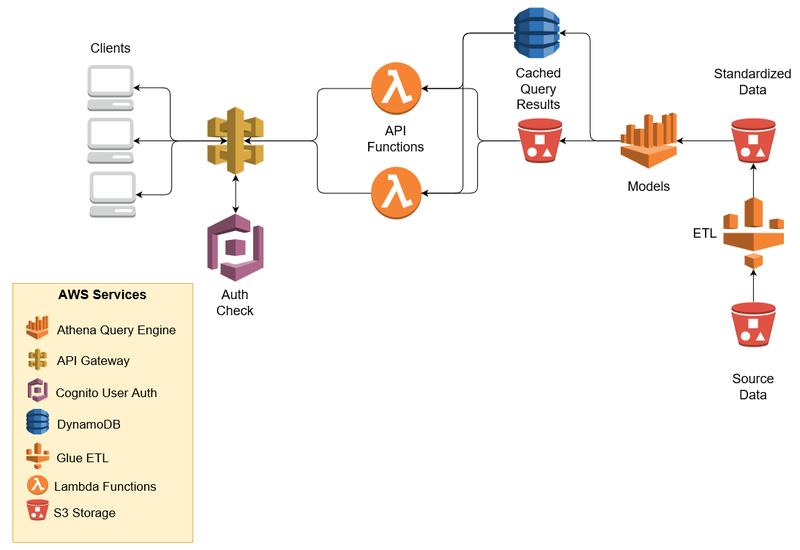
We composed our deployment using AWS CloudFormation.
As shown in the architecture diagram, our source data comes from an S3 bucket in CSV format.
Once new files arrive in the bucket, our AWS Glue script runs the extract, transform, and load (ETL) job to convert the files from CSV to Parquet format and drop the converted files into another S3 bucket.
We use Amazon Athena to query the Parquet data. The query results are dropped to a result bucket by Athena.
At this point, all the backend data processing is done.
On the client-facing side, Amazon CloudFront hosts several independent SPA (Single Page Application) web apps that use Amazon Cognito for authentication and authorization.
The web apps make secure calls to the REST endpoints of Amazon API Gateway to get the data.
Amazon DynamoDB stores a hash of a query string and a result id from Athena.
The API checks the DynamoDB first to get the Athena result id. If present, it gets the query result from the S3 bucket using the result id; otherwise, it makes the query to Athena and puts the result id to DynamoDB.
The remainder of this article provides an overview of the AWS system used for the project.
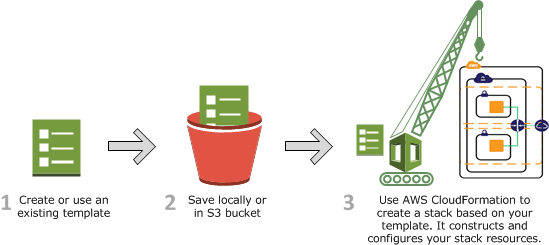
Infrastructure as Code: CloudFormation
AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources so you can spend less time managing those resources and more time focusing on your applications that run in AWS.
The workflow for CloudFormation is depicted in the following diagram.
Data Storage: AWS S3
AWS S3 is a simple storage service that can be used to store and retrieve any amount of data.
S3 is object-store and very reliable. It offers the most flexible set of storage management and administration capabilities of all AWS storage services.
An S3 bucket is a logical unit of storage in S3. Buckets are used to store objects that consist of data, as well as metadata that describes the data.
We used S3 in our solution to host static websites, ferry unstructured data through our ETL pipeline, and store query results.
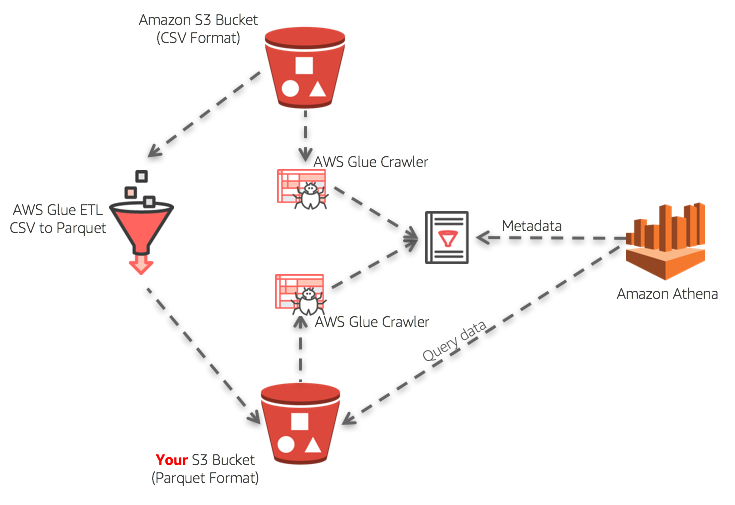
Serverless ETL: AWS Glue
AWS Glue is a managed ETL service that enables the easy cataloging and cleaning of data from various sources.
With Glue you can focus on automatically discovering data schema and data transformation, leaving all of the heavy infrastructure setup to AWS.
It was easy to incorporate Glue into our architecture because Glue is already serverless and does not require the provisioning of persistent infrastructure.
The ETL flow is depicted in the following diagram
Data Retrieval: Amazon API Gateway and AWS Lambda
Amazon API Gateway is a service that acts as a bridge between AWS services and external apps. It enables developers to create, publish, maintain, monitor, and secure APIs. It authenticates, manages, and monitors API calls from external apps and passes them to AWS services, such as AWS Lambda or DynamoDB.
The API Gateway also creates publicly accessible HTTP(S) endpoints.
AWS Lambda provides Functions as a Service (FaaS).
With AWS Lambda, Amazon manages the servers, which allows a developer to focus more on writing application code in languages such as Node.js, Python, Java, and C#.
Microservice architectures require an application to be broken into smaller pieces (services) to enable scalability and more agile development. Lambda embraces this philosophy and allows developers to deploy a single function at a time.
Generating APIs: Serverless Framework
Serverless framework is a set of APIs that can be used to define your service endpoints and corresponding cloud function handlers with YAML or JSON documents.
The Serverless CLI is a NodeJS CLI application that can be used to parse your Serverless configuration files, generate the infrastructure as code for multiple cloud vendors (CloudFormation in the case of AWS), and package and deploy your API Gateway and Lambda functions to the cloud.
You can extend Serverless framework with plugins and custom configuration for a number of uses, such as enabling local testing, AWS Cognito integration, and generating API documentation.
Serverless Query Caching: DynamoDB
AWS DynamoDB is a fast, fully managed, NoSQL database service that makes it simple and cost-effective to store and retrieve any amount of data and serve any level of request traffic.
DynamoDB offers encryption at rest, which help in protecting sensitive data.
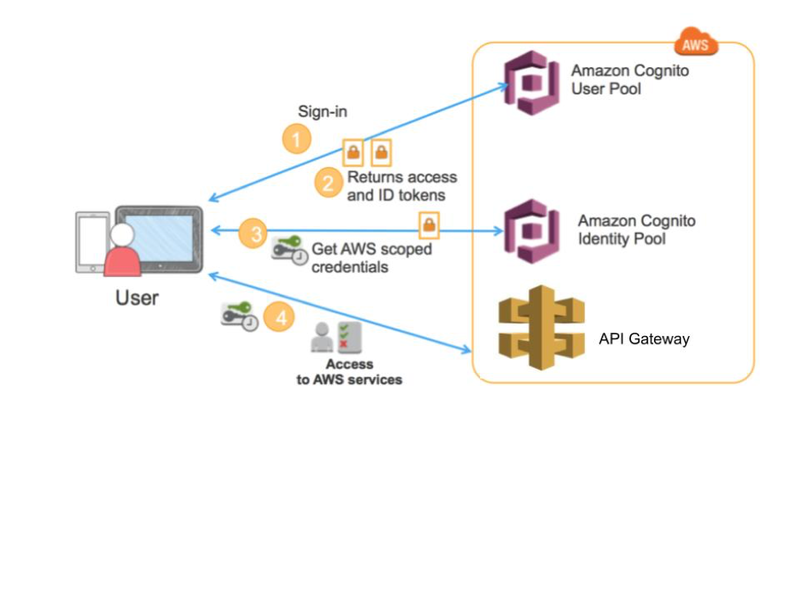
Serverless Authentication and Authorization: Amazon Cognito
As shown in the architecture diagram, we will need a guard in our system to protect all our resources.
Amazon Cognito is the serverless solution for authenticating and authorizing requests.
Cognito not only provides common user-management flows, such as sign in and sign up, but also handles identity provider federation, such as Google, Facebook and corporate identity integration, using SAML and OpenID Connect.
This means all B2C, B2B, and corporate internal applications can use Cognito as the auth component in the system. It supports both AWS SigV4 and OAuth 2.0 security standards.
The two components in Cognito are User Pools and Identity Pools.
User Pools is for creating users and groups, setting up your app clients, and configuring your identity federation.
User Pools issues JWT tokens (id, access, refresh). Those tokens are used to get temporary AWS credentials from Identity Pools. Based on those credentials you can access all the AWS resources, such as API Gateway, S3, DynamoDB, etc with appropriate IAM roles and permissions.
The general authentication flow is depicted in the following diagram (slightly modified from this article).
UI Client Libraries: AWS Amplify
AWS Amplify is an open-source declarative JavaScript library for web- and mobile-application development using cloud services.
AWS Amplify is basically a utility belt for building hybrid mobile applications and progressive web applications with an AWS backend.
Amplify makes it easy to integrate AWS Cognito login and send credentials to make authorized requests to API Gateway. You can also use Amplify to implement service workers, track user activity, securely store user files, enable caching, push notifications, utilize publish/subscribe (pub/sub) design patterns, and more.
The default implementation works with AWS resources, but it's designed to be open and pluggable for usage with other cloud services that wish to provide the same AWS default implementation.
AWS Amplify can be implemented with any JavaScript-based front-end library, such as React, React Native, Angular, or Vue.js.
Building the UI with React and AWS Amplify
To create our serverless UIs, we deployed React.js SPAs to AWS S3 and leveraged the AWS CloudFront content delivery network (CDN) for global distribution, edge-location caching, and DDoS protection.
We used AWS Amplify React’s “withAuthenticator” higher-order component (HOC) to integrate the hosted Cognito login experience with our apps. This saved us a great deal of time because we did not need to implement our own authentication and authorization solution.
Conclusion
This article walked you through one example of a serverless architecture, but this by no means represents the only possible solution. By loosely coupling the tools used to build cloud solutions, a developer has great flexibility in terms of how to arrive at the best approach.
Cloud providers like AWS offer myriad services, which with diligence can be combined to build an application that is scalable, highly available, fault-tolerant, and secure.
Cloud architecture is not a one-design-fits-all area, and while a future article will go more in depth about how to implement and deploy the architecture described above on AWS, remember that the best approach is one tailored to the exact business need.
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
