Three Months of Liberty: Experiences in Cloud Computing with OpenStack
By Justin Wilson, OCI Software Engineer
February 2016
The OpenStack Foundation [1] released the 12th version of its cloud operating system named “Liberty” in October 2015. Wanting to gain a deeper understanding of cloud computing and DevOps principles, we set up an OpenStack cluster in November. This is what we learned.
The Cloud
Much of the computing industry is moving to the cloud, but what does this mean? What is a cloud and why would we want to move there?
One can engage the cloud at different levels.
- At the top is Software as a Service (SaaS), where software is used on a subscription basis.
- In the middle is Platform as a Service (PaaS), where the core abstractions are engines for running applications and supporting systems, like databases.
- At the bottom is Infrastructure as a Service (IaaS), where the core abstractions are instances and networks.
This article is primarily concerned with IaaS, the service provided by OpenStack.
|
Software as a Service (SaaS) Microsoft Office 365 |
|
Platform as a Service (PaaS) Cloud Foundry, Heroku |
|
Infrastructure as a Service (IaaS) AWS, Google Compute Engine, Open Stack |
Organizations are moving to the cloud for three main reasons:
- Scalability. New machines can be provisioned to handle increases in load in order to maintain a positive user experience. Similarly, a pool of machines may be scaled down to save money.
- Agility. Any project involving software requires infrastructure (computing, network, and storage). This infrastructure is used to develop, test and deploy software. Physical infrastructure is slow to deploy and rigid, and requires consideration of the long-term consequences around ownership and maintenance. Virtual infrastructure, on the other hand, may be deployed quickly, is quite flexible, and requires no long-term commitment.
- Cost. Moving to the cloud may reduce cost. It does this in two ways. First, many cloud providers offer pay-as-you go service plans. With appropriate attention to detail, users pay only for what they need. Second, the cost of owning and operating physical machines may be lower for a cloud provider, and these savings may be passed on to users.
IaaS
A metaphor we often used when working with OpenStack was to treat a cloud like a virtual server room. In a cloud, you build machines and networks, install software, etc. The main difference and key advantage of the cloud is that everything is virtual and may be set up programmatically. Thus, rather than physically acquiring and assembling a machine, one creates a virtual machine. Rather than installing and configuring physical networks, one creates virtual routers, switches, ports, etc.
Infrastructure
The basic capability offered by cloud providers like OpenStack is the ability to create infrastructure, namely, machines and networks.
Machines are typically virtual machines, but some cloud providers also offer bare metal machines, which are dedicated machines that avoid the overhead of virtualization.
To create a virtual machine, one specifies an image and a flavor.
- The machine boots from the image, which is typically a virtual disk that contains an operating system. The machine booted from the image is an instance of that image.
- The flavor specifies the attributes of the machine, such as the number of virtual CPUs, the amount of memory, the size of the disk, etc. Flavors are typically designed to reflect the physical machines that run the virtual machines. For example, a virtual machine with 8 CPUs must run on a physical machine with at least 8 CPUs.
Instances that wish to preserve data beyond the time that they are terminated must store it on a volume that is analogous to a physical disk. The primary disk of an instance may be a volume. Volumes can also be attached as secondary disks to provide persistent raw storage.
Networking
Networking cloud instances together is similar to networking physical machines.
The process begins by defining a network, which just names the group of communicating devices. Within that network, the user defines one or more IP subnets, which define the addresses available to attached instances.
Configuring a subnet is similar to configuring a DHCP server, in that one can specify ranges of addresses, a gateway, DNS servers, default routes, etc. When creating a new instance, one can bind the instance to different subnets. This creates a network interface in the virtual machine whose traffic will reach other instances on the same network.
Related to networking is the concept of a security group. A security group limits the network traffic coming into and out of an instance. Configuring a security group is similar to configuring a firewall, in that rules are specified that govern different kinds of network traffic. Security groups are applied outside of the instance.
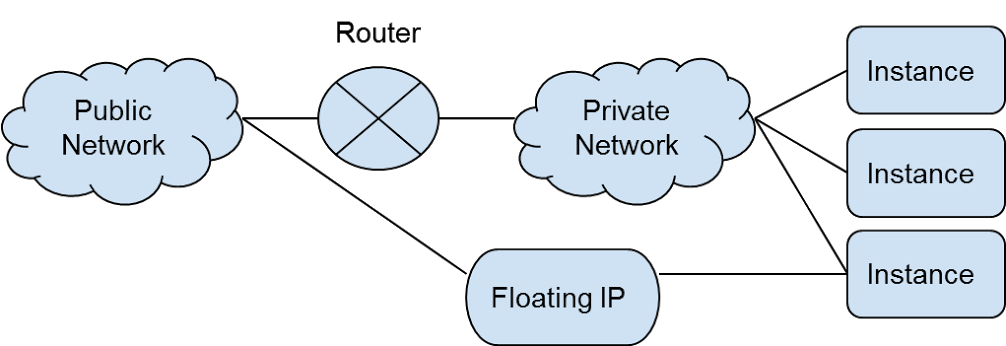
Cloud providers typically offer one or more external or public networks to their clients.
A connection to an external network allows an instance to communicate with machines on the Internet. There are three approaches to providing such a connection.
- First, the instance may use a gateway with a connection to an external network. The gateway is a virtual router that routes traffic between the external and internal network. This approach is used when the instance doesn't sit on the edge of the network.
- Second, the instance may be associated with an internal network and assigned a floating IP. A floating IP is an IP address taken from the external network that is translated to the internal address of the instance through network address translation (NAT). Typically, a cloud consumer will have a pool of floating IPs that he or she may use as he or she sees fit.
- The third option, which is rarely if ever used, configures the instance with an interface on the external network.
Instances running on a virtual network constitute a cloud – a virtual server room.
*aaS
IaaS should be sufficient for cloud clients. Instances can be created, configured, and networked to do almost everything that may be done with physical infrastructure. However, cloud providers offer value-added services that make building infrastructure easier.
On the networking side, many cloud providers offer Networking-as-a-Service (NaaS), which consists of common networking services like DHCP and DNS.
Similarly, Firewall-as-a-Service (Fwaas) provides the functionality of a traditional firewall, and Load-Balancer-as-a-Service (Lbaas) provides the functionality of a traditional load balancer. These services may be provided by instances, processes running in a host operating system, or with hardware.
Cloud providers and third-party vendors may also offer Platform-as-a-Service (PaaS).
Where IaaS deals with infrastructure, PaaS deals with the platforms and services needed to host applications. For example, Database-as-a-Service (Dbaas) eliminates the hassle of setting up a database by using one that’s preconfigured. Rather than create and manage a cluster for serving a Grails app [2], one may simply use a service that deploys the app to a managed cluster, without considering any aspect of the underlying infrastructure. Amazon has been particularly zealous in this area as indicated by the number of services available on AWS (see below).

OpenStack
OpenStack is a cloud provider suite. Some organizations, most notably Rackspace, run OpenStack to provide cloud services to others (i.e., a public cloud). However, OpenStack is a free and open source product that enables users to host clouds on their own physical infrastructures (i.e., private clouds). This may or may not be beneficial to an organization, depending on the particular situation.
An organization with a significant investment in infrastructure, or a legal requirement to maintain records on site, may find that deploying a local cloud is a cost-effective way to add flexibility to its infrastructure. Some applications, such as those that perform a lot of I/O or generate a lot of network traffic, may be cheaper to run in a local cluster. Your mileage will vary.
Core Service Groups
OpenStack consists of the following core service groups:
- Swift – storage system for blobs like virtual machine images
- Keystone – identity management
- Keystone manages users and credentials, projects, and domains (organizations). Quotas are enforced at the project level.
- Nova – instance lifecycle
- Nova is used to start, stop, migrate, etc. virtual machine instances.
- Neutron – networking services
- Neutron is used to provide NaaS.
- Cinder – block storage
- Cinder is used to create volumes that may be attached to instances for persistent storage.
- Glance – image storage
- To launch a virtual machine, an image should be uploaded to Glance. Glance, in turn, uses Swift to store the image.
Optional Service Groups
OpenStack contains a number of optional service groups. Some of these are for managing infrastructure, such as dashboards (Horizon) and telemetry (Ceilometer), while others are PaaS components, such as messaging (Zaqar) and database (Trove).
Nodes
A reference architecture for an OpenStack cluster contains the following types of nodes:
- Infrastructure – database and messaging service (AMQP)
- Controller – core services like registries and schedulers
- Compute – host virtual machine instances (Nova)
- Block Storage – hosts persistent storage volumes (Cinder)
- Object Storage – blob storage (Swift)
- Networking – hosts networking services including DHCP servers, load balancers, etc.
Interaction
The various OpenStack services interact with each other through message queues and RESTful front-ends. The installation guide recommends using MariaDB for the backing database and RabitMQ for the messaging service.
Users can interact with OpenStack via:
- The RESTful interface exposed by each service
- Command-line utilities
- The web front-end, code-named Horizon
OpenStack is implemented in Python, but there seems to be a growing sentiment within the OpenStack community that a compiled language with static type checking is needed to cope with the current complexity of the codebase [3,4]. Developers at Rackspace have already re-implemented portions of the Swift service in Go [5,6].
Setting Up an OpenStack Cluster
The OpenStack documentation contains directions for setting up OpenStack on a number of Linux distributions [7]. For our cluster, we selected Ubuntu 14.04 (LTS).
The cluster consists of HP Compaq 6000 Pro Small Form Factor machines, with Core 2 Duo E8400 3.0GHz processors (2 cores), a 250 GB disk, and 6GB RAM. Half of the disk was available for the Ubuntu installation. The machines have an integrated gigabit Ethernet adapter and are connected via a gigabit Ethernet switch.
The initial plan was to have one controller node, one network node, and four compute nodes. There were no plans for object storage nodes (Swift) and block storage nodes (Cinder). The consequences of this decision are that Glance stores images on the disk of the controller node, and object services and block services are not available for projects. The QEMU hypervisor with KVM extensions was used on the compute nodes, as the machines have hardware acceleration for virtual machines.
Deploying OpenStack is a complex task with many different options. For example, one can make the OpenStack services highly available by setting up load balancers, quorums of servers, etc. for the various OpenStack services. Another idea is to deploy the services in Docker containers to enforce isolation and ease configuration. OpenStack services may be installed and configured using configuration management solutions like Chef, Puppet, and Ansible.
Multiple redundant physical networks are recommended for OpenStack clusters. The OpenStack documentation suggests a tenant network that contains instance traffic and a management network for OpenStack services. In this configuration, a compute node would contain four physical ports: redundant ports for the tenant network and redundant ports for the management network. Similarly, techniques like bonding may be used to increase the throughput for object storage and to block storage nodes.
There are three approaches to tenant networks:
- The first is to allocate a VLAN for each virtual network. This approach limits the number of virtual networks to 4096, as that is the limit imposed by the VLAN header.
- The second is to use a VXLAN that encapsulates Ethernet frames in UDP packets, which may then be re-encapsulated in an Ethernet frame and sent on the physical network. Support for jumbo frames is recommended when using a VXLAN; otherwise, the MTU of the virtual network interfaces must be reduced by 50 bytes to allow for the VXLAN header.
- The third approach is to use a dedicated physical network.
Our network was set up as one physical network (tenant and management traffic share the physical link), and the virtual networks are implemented using VXLANs by configuring the 50 byte overhead.
After our initial installation, we made three additions to the cluster to give it more capabilities for DevOps experiments and to make it easier to use.
- We decided to add Horizon, which is a web front-end for the various services. Horizon did make interacting with OpenStack easier.
- We decided to add LbaaS for DevOps experiments.
- We decided to add a block storage node. This node was configured with LVM, which is used to store the persistent volumes.
Using LVM was simple and appropriate for our installation but other installations may wish to take advantage of other storage options, like storage clusters, NAS, SAN, etc.
Adding LbaaS to OpenStack
We were very early adopters of the Liberty release, which lends itself to some of our challenges. This is best illustrated by our experiences adding LbaaS support.
The first problem with adding LbaaS support was that it was poorly documented. We pieced together fragments from three different documents and numerous bug reports to deploy LbaaS version 1. Given a number of early failures, we moved on to LbaaSv2, which suffered a similar lack of documentation. We eventually got LbaaSv2 to work but then realized that LbaaSv2 is not supported by Horizon or Terraform (a cloud provisioning utility). Thus, we reverted to LbaaSv1 and attempted to “make it work” using what we learned from LbaaSv2.
Debugging LbaaSv1 required an understanding of how OpenStack sets up virtual private networks and how the LbaaS service is provided. There are three pieces to a load balancing system:
- The client initiating the request
- The load balancer
- The server to which the load balancer is dispatched
The load balancer has two IP addresses:
- A virtual IP address (VIP) on the internal network
- A floating IP, assigned to make the service offering available publicly
We observed that the health check performed by the load balancer was successful. Thus, the load balancer could talk to the server. A tcpdump of the conversation between the client and load balancer indicated a failure to communicate. At this point, we reverse engineered the load balancer and network architecture of OpenStack.
A network interface (A) inside a virtual machine is mapped to a network interface on the host (B). This interface is plugged into a bridge with another interface (C) that performs the VXLAN encapsulation. The VXLAN interface is implicitly connected to another interface (D) that has been configured for IP traffic. Instead of using a virtual machine, OpenStack provides LbaaS by running haproxy in a network namespace. Thus, we looked at the network interfaces on the network node and found the network namespace for the load balancer process.
Upon examining the firewall rules in this namespace, we found that there were no rules for passing the TCP port 80 HTTP traffic that we desired. This led to the discovery that the VIP, i.e., the internal IP address of the load balancer, was being created with the default security group, which does not permit port 80. Thus, we changed the security group, and the system passed a small smoke test.
Upon scaling up, a tcpdump on the client now showed traffic, but there was always one packet missing. We examined the traffic leaving the server and haproxy process and found that nothing was amiss.
Then, we observed that the missing packet was always the first packet in the HTTP response, and the size of the packet was close to 1,500 bytes after adding the TCP/IP header. Therein lay the problem; the response generated by the haproxy process assumed an MTU of 1,500 bytes, instead of the 1,450 required by the VXLAN. These packets were being dropped by the VXLAN interface.
OpenStack, when setting up the network interface for the haproxy process, was ignoring the VXLAN configuration and using the default MTU of 1,500 bytes. Our temporary workaround was to alter the LbaaS code to create these interfaces with an MTU of 1,450 bytes, as we found no configuration options to solve this problem.
We believe this anecdote highlights three warnings for prospective users of OpenStack:
- Always suspect the security group settings. There is no security group setting for the VIP in our deployed version of Horizon. Rather, we assumed that the ports configured to forward traffic on the load balancer would be open. We were wrong.
- Expect different parts of OpenStack to (by default) not work with each other. Older core features, being the most stable, will have the best integration. New and more peripheral features, like LbaaS and VXLAN, will suffer from integration problems.
- Be prepared to get your hands dirty. OpenStack has an archive of bug reports and a StackOverflow channel, etc. However, finding the exact document you need is often difficult. Thus, when problems arise, be prepared to poke around the internals of OpenStack.
Utilizing the Cloud
With OpenStack deployed, we began to create clouds to explore ideas in continuous delivery and DevOps.
Pull Request Builder
OpenDDS [8] is an open source publish/subscribe system based on the DDS standard. The source code for OpenDDS is hosted on GitHub, and the developers of OpenDDS use TravisCI and AppVeyor to perform smoke tests for pull requests. However, due to the time limitations for the free tier services of TravisCI and AppVeyor, the automated builds can perform only one test. Thus, one idea was to create a system that could build pull-requests and perform the complete suite of automated tests.
The integration consists of a single Ubuntu 14 LTS instance running Jenkins. Jenkins was configured with the GitHub Pull Request Builder plugin. GitHub was configured to push notifications to the Jenkins instance, and firewalls were adjusted to allow traffic from GitHub. The Jenkins instance has credentials that allow it to post the build and test results on GitHub.
The Jenkins server is provisioned using Terraform [8]. When using Terraform, the desired infrastructure is defined in a set of configuration files. The Terraform tool then interacts with the designated cloud provider to create the desired infrastructure.
Herein is a powerful idea, namely, that infrastructure may be described in files and reproduced on demand. The configuration files can be checked into version control to create a record of how the infrastructure and its configuration evolved. The Terraform script not only recreates the server, but also loads the Jenkins configuration from files stored in the version control repository. The goal is repeatability; that is, given the content of the version control repository, we are able to recreate the Jenkins instance.
Dev→UAT→Prod
Another use case for our cloud is to host development, testing, and production environments for a Grails application.
The approach for this project used many of the techniques for the Pull Request Builder. The development environment consists of a Jenkins instance that is configured to poll the source code repository and then build and test the application. The result of the build is a war file.
The user acceptance test (UAT) environment consists of a single Ubuntu 14 LTS instance running Tomcat 7. A simple script may be used to download the war file from the Jenkins server and deploy it to the Tomcat container. The production environment consists of a load balancer and two instances serving the application.
The development of these environments was straightforward using Terraform. However, we did run into a problem with the startup of Tomcat, as it requires a certain amount of entropy for secure operation. Low entropy is a known problem for cloud instances, and there are various workarounds.
Spinnaker
Spinnaker [9] is an open source DevOps tool developed and used by Netflix. Spinnaker consists of a number of Groovy applications that provide the tooling needed to build application-specific cloud infrastructure and then manage the deployment of that infrastructure. Currently, Spinnaker cannot deploy to an OpenStack cloud. However, we can use OpenStack to host Spinnaker.
Our Spinnaker cloud consists of an instance for hosting Spinnaker and another Jenkins instance. The Jenkins instance is responsible for building, testing, and serving artifacts.
The Spinnaker documentation recommends a machine with 8 cores and 50GB of RAM. Obviously, the 2 core 6GB machines available in our cluster fall short of this. One approach would be to install the various pieces of Spinnaker, including the back-end Cassandra and Redis databases, on different machines. However, we managed to use only one instance by reducing the Java heap sizes associated with the various processes.
Observations and Conclusions
General Observations
The cloud is an enabling technology for DevOps practices.
First, the cloud enables self-service, meaning that developers have the power to create infrastructure without contacting a system administrator. For example, a developer can provision a new development machine or replicate a test environment that exposes a certain kind of bug.
Self-service is powerful but may also lead to wasted effort if a developer spends more time developing infrastructure than code. Thus, part of adopting DevOps practices is defining how much liberty developers have with respect to infrastructure.
Second, the cloud facilitates reproducible infrastructure. Change management software may be used to achieve a high degree of reproducibility in physical infrastructure, but there is always a manual component to configuring physical hardware. The cloud takes this further, since every artifact can be versioned and every configuration decision automated.
Cloud environments are complex and require the ability to reason about subtle interactions. Developers participating in DevOps and cloud computing must have a basic understanding of technologies like DNS, load balancers, NAT, external persistent storage, etc., because they will inevitably have to deal with such things when debugging applications. The ecosystem and tools for cloud computing and DevOps are currently immature and volatile. Do not be surprised if a tool doesn’t have support for a certain cloud provider or DevOps practice.
New applications should be developed with the cloud in mind, as illustrated by our experience deploying a Jenkins server. Using OpenStack in concert with Terraform to provision a Jenkins server was not as straightforward as might be expected, through no fault of OpenStack or Terraform. Rather, Jenkins stores configuration, plugins, job descriptions, and workspaces in the same directory structure. To deal with this, we wrote a script to prune out files that were not part of the configuration, so that the remaining configuration files could be checked into version control.
Jenkins could be more “cloud friendly” if it stored its configuration data differently. Thus, when developing a new application, consideration should be given to how it might be deployed and used in the cloud. As demonstrated by the Jenkins example, applications should separate configuration, persistent data, and ephemeral data. The configuration and persistent data may then be loaded from persistent volumes or some other store.
OpenStack Observations
OpenStack is a large, rapidly changing open source project. The OpenStack community seems to be a community of corporations (as opposed to a community of individual developers), which has led to a certain amount of feature creep, bloat, and dilution of concepts.
OpenStack has a number of moving parts with a number of configuration options. When developing support for a cloud provider, OpenStack is typically last.
However, despite these criticisms, the main IaaS capabilities of creating networks and launching instances are functional and stable, making OpenStack a viable cloud provider platform. Furthermore, OpenStack is free, it may be run locally, and its full source is available.
Working with OpenStack over the past three months has been a liberating (pun intended) experience, as it has given me an understanding of the potential power of cloud computing and the DevOps movement.
References
- [1] https://www.openstack.org
- [2] https://grails.org
- [3] https://www.openstack.org/summit/vancouver-2015/summit-videos/presentation/war-stories-5-years-in-the-openstack-trenches
- [4] https://www.openstack.org/summit/vancouver-2015/summit-videos/presentation/openstack-is-doomed-and-it-is-your-fault
- [5] http://lists.openstack.org/pipermail/openstack-dev/2015-April/063019.html
- [6] https://www.openstack.org/summit/tokyo-2015/videos/presentation/omg-objects-the-unscaly-underbelly-of-openstack-swift
- [7] http://docs.openstack.org
- [8] http://www.opendds.org
- [9] https://terraform.io
- [10] http://spinnaker.io
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
