Data Ingestion Strategies for Data Lakes
By Paul Scheibal, OCI Software Engineer
December 2021
Introduction
A data lake is a system or repository of data initially stored in its natural or raw format. It is usually a single store containing many types of data, such as operational transactions, file and sensor data, and image, audio, and video files from many sources.
Data lake projects are complex, consisting of data ingestion strategies and processes, data curation, pipeline orchestration, data governance, and security, and they require the right software to perform these tasks.
Data lakes typically go through a layering process called curation. Curation organizes, transforms, and structures the data to be consumed by analysts and data scientists.
Below is a diagram of the components of an example data lake. This diagram divides the contents into three zones: raw, curated, and refined. However, the number of zones a data lake contains is not limited to three; business requirements and data complexity, along with data lake architecture philosophies, define the number of zones in a data lake.
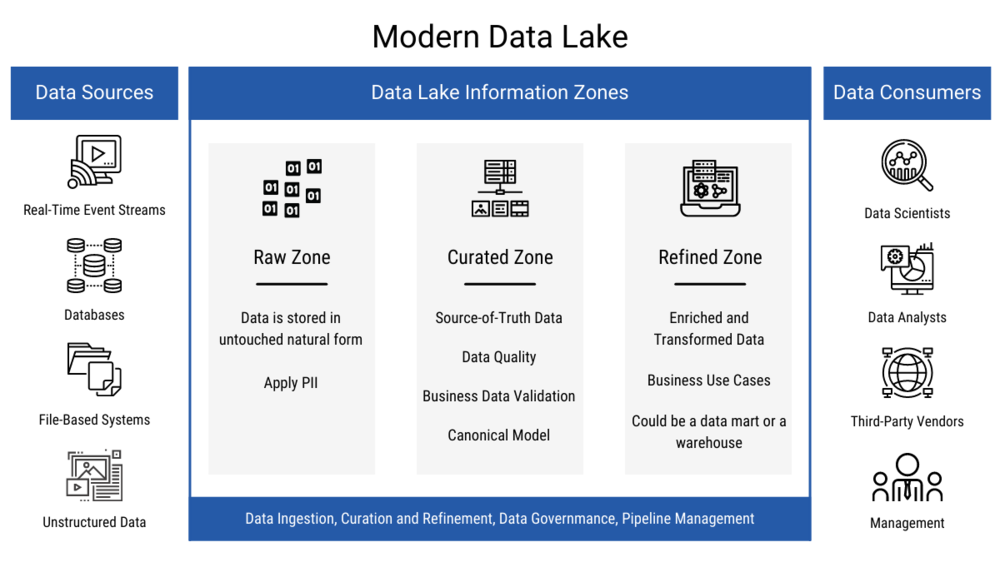
Figure 1. Modern data lake
Due to their complexity, data lakes require many skill sets in order to architect, build, support, and consume information. The following is a list of some of the roles required for a data lake implementation:
- Data and enterprise architects work together to design data ingestion and data lake patterns.
- Data engineers do the programming necessary to build data lakes.
- Cloud engineers build out the cloud infrastructure necessary to support the data lake.
- Operations manages the day-to-day operations of the data lake.
- System analysts understand the source information and model it appropriately in the data lake for business consumption.
- Business analysts visualize information in the data lake looking for data trends.
- Data scientists use machine learning to gain business insights and predictive behaviors.
- Business application owners consult business analysts to define business requirements.
Data Ingestion
One of the most important processes in data lake creation is the data ingestion process, which is a series of steps used to load data into the data lake in raw format, as shown in the figure below.
Data stored in its raw format in a data lake is often called the raw layer or raw zone. From this data, a set of processes will be defined to curate the raw data and make it usable by analysts and data scientists.
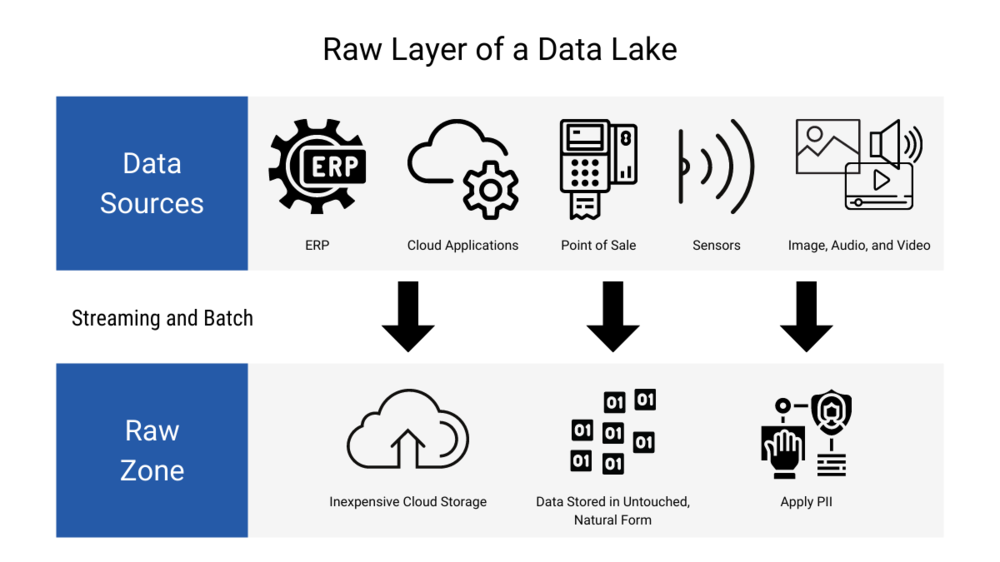
Figure 2. Raw layer of a data lake
First, data sources must be defined, along with information about each one. Here are some of the considerations:
- In what software system does the data reside?
- Is the data structured, semi-structured, or unstructured?
- What mechanisms does the software system allow for data extraction (APIs, SQL, …)?
- Does the data need to be accessed in real time or near real time, or daily, weekly, monthly, etc?
- What format is the data in (relational table, comma-separated values (CSV), image format, etc)?
- Is there sensitive information contained in the data?
- Are there any potential violations of legal requirements due to HIPAA regulations or geographical jurisdictions?
This information or metadata is important as a resource for consumers of the data lake. It establishes the meaning of data objects and their relationships to each other. Metadata is indispensable when assembling additional high-performance access layers in downstream zones.
Once the metadata is collected, the next step is to define where and how the data will be stored. Most modern data lakes use cloud storage to store data. Cloud vendors such as AWS, Azure, and Google Cloud Platform provide inexpensive cloud storage, which is highly available and well suited for data lake storage.
Once it is determined where the data will be stored, decisions must be made regarding what format the data should be stored in. In most situations, data will be stored in raw format or in the same format as its source. For example, if data is sourced from a CSV file, it will be initially stored as a CSV file. Data sourced from relational tables is often stored in Parquet format, which is a columnar-based tabular format. Image data will be stored as images, such as PNG format.
The final step in the ingestion architecture is defining how the data will be transported to the data lake raw layer. The overall ingestion architecture is often defined by data architects working with enterprise architects.
Because undoing or rearchitecting a data ingestion solution can be a lengthy and painful process, it is critical for architects to get the ingestion architectures right. For example, if the business requirement is real-time analytics, and data is ingested using a pattern that does not support real time, business needs will not be met, and stakeholders will be dissatisfied with the results. When business requirements are overlooked or changed later, a data lake becomes a data swamp.
Fortunately, architecture patterns already exist that provide the right ingestion solutions to meet a variety of business needs. The remainder of this paper discusses some common ingestion patterns in data lakes.
Ingestion Patterns
More than likely, more than one ingestion pattern will be used for data lake hydration. A recommendation is to keep the number of ingestion architecture patterns manageable. Too many patterns may result in an overly complex solution requiring too many personnel to manage it, and ultimately it will fail to meet business needs.
Typically, ingestion patterns can be categorized as either batch or real time (or near real time).
Batch Ingestion Patterns
Batch ingestion patterns process data in batches, just as the name suggests. Real time is not typically a requirement for batch ingestion; data is typically ingested into the data lake raw layer on a nightly, weekly, or monthly schedule.
For batch processing, extract-transform-load (ELT), extract-load-transform (ELT), and integration tools are typically used to ingest data into the data lake. Some examples of enterprise vendor integration tools are Informatica, Talend, Mulesoft, and Workato. These are typically expensive, but they provide capabilities to ingest large amounts of data using application APIs, drivers that access relational databases, and drivers that process flat structures, such as CSV files. They also provide ETL/ELT functionality to perform complex transformations on data.
Application Program Interface (API) Access
With the movement of many enterprise resource planning (ERP) solutions to the cloud, as well as other third-party applications, data can no longer be accessed by directly querying an application’s data model, as was typically done with on-premise applications. APIs are a way to access applications without needing to understand the underlying data models. They also provide upgrade protection; the application may change, but the API stays the same.
As an example, a cloud-based marketing vendor collects valuable daily information about a company’s customers. This information is crucial for data scientists, who plan to use machine learning techniques to drive new customers and new revenue-generating opportunities.
The vendor publishes a set of APIs to access the marketing information. On a nightly schedule, Mulesoft, which is a good tool choice because it provides full-lifecycle API management and is well known for this functionality, invokes the marketing company's APIs to extract the information. Mulesoft then ingests the data in raw form into the data lake raw layer as shown below.

Figure 3. Batch API call to extract data from cloud vendor and transfer to raw layer
On-Premise Database Extracts
In a batch scenario where an on-premise database exists, a company may not allow any cloud-based tools to access on-premise databases nor allow an ETL/ELT tool to reach into its cloud environment from the on-premise environment.
If there is a requirement to extract data, including a timestamp column, from an ERP system (such as Oracle or SAP) on a daily basis and ingest it into the company’s data lake, an ETL or ELT tool might be used to extract the data, create a flat file, and place the data into an on-premise staging directory. Then a high-performing storage transfer service provided by the company's cloud vendor could pick up the data files in that staging directory and automatically transfer the data to cloud storage in a secure manner.
This same process could be used for vendor-supplied files used by the business. Instead of using APIs to access data, the vendor could push a file on a specified interval to either on-premise facilities or directly to cloud storage.

Figure 4. Batch ETL/ELT extract from database to storage transfer service to raw layer
Real-Time Ingestion Patterns
Many business stakeholders demand access to more current information. They want access to real-time information, which is necessary for making decisions in a timely manner.
What does real time mean? Is it within seconds, minutes, or hours?
The answer is, it depends on the use case. Sometimes data is required within a few seconds in order to make decisions, and sometimes it is only feasible to provide information every minute or even every 15 minutes due to limitations in when the data is actually available. This is still considered real time because the information is provided for consumption as soon as the data is available.
For example, an electric and gas utility might set up real-time feeds from its smart meters that update every 15 minutes in order to provide real-time services like power consumption alerts or up-to-date energy costs to customers, as shown below
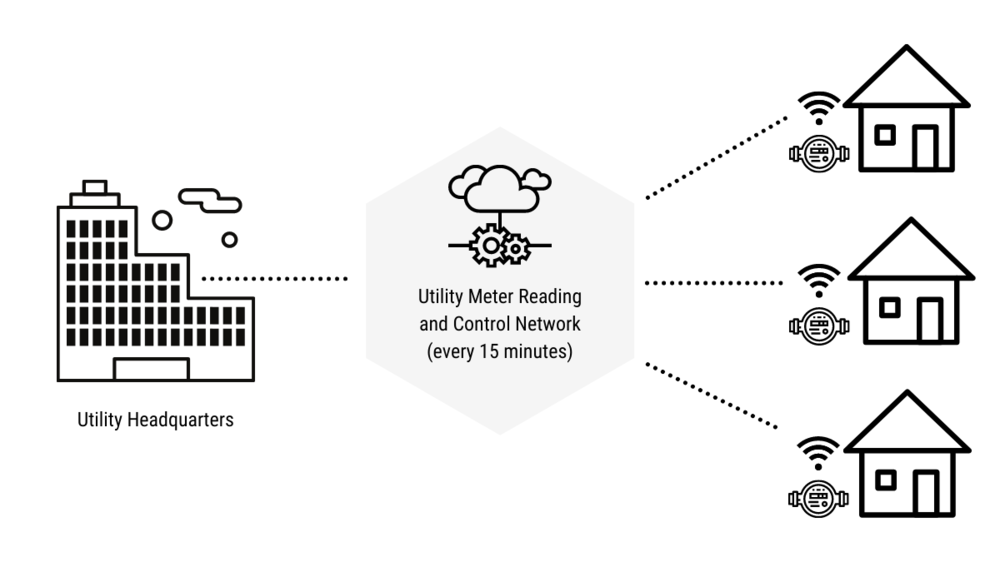
Figure 5. Electric utility with smart meters
Many manufacturing companies have sensors installed on their equipment that provide real-time alerts when equipment is in need of maintenance. Such real-time feedback allows maintenance work orders to be created automatically as soon as sensors detect a problem with the equipment. Preventative maintenance is much cheaper than recovering from an unplanned outage due to equipment failure.
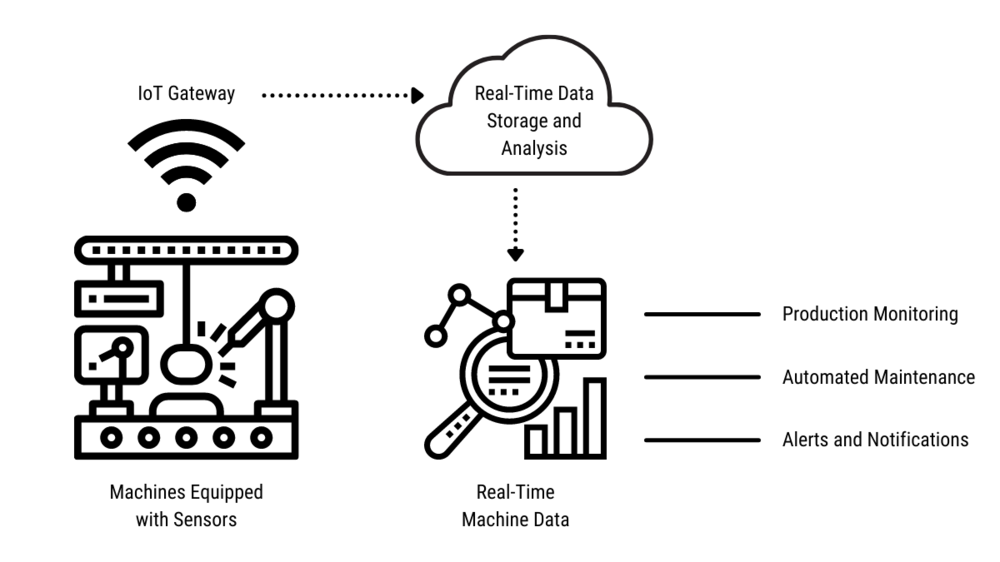
Figure 6. Real-time sensors in manufacturing
Restaurants might provide real-time (within seconds) suggestions to a customer who is ordering lunch by using a real-time recommendation AI engine, as shown below.
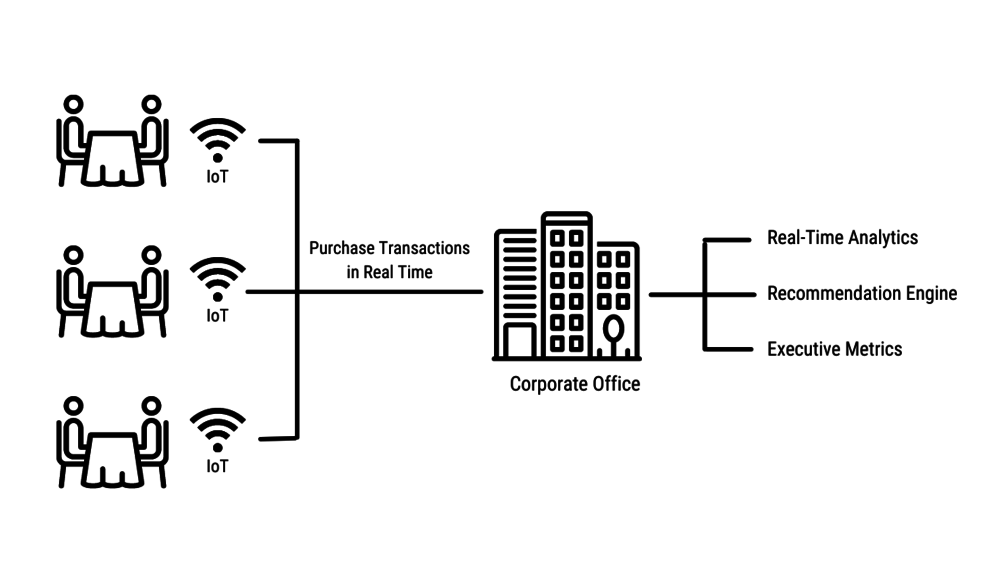
Figure 7. Real-time product recommendations
To keep players engaged, a video gaming company may track player interaction in real time. As a player struggles, the game makes it easier for the player to win. If the game is too easy, the game adjusts to make it harder to win.
Streaming
The most common way to get real-time information is a process called streaming. Streaming is a method of transmitting or receiving data over a computer network as a steady, continuous flow, allowing playback to start while the rest of the data is still being received.
The most common streaming solution is Apache Kafka. Kafka is an open source distributed event streaming solution under licensing from the Apache Software Foundation, and it's free. According to Apache’s website, Kafka is "used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications." Support contracts can be purchased for Kafka from Confluent.
Other open source streaming platforms are Apache Flink, Apache Spark, Apache Storm, and Apache Samza. Cloud vendors provide managed-service streaming platforms like AWS Kinesis and Google Cloud Platform Pub/Sub. Enterprise vendors like IBM, Microsoft, and Informatica also provide real-time streaming solutions.
Streaming solutions operate using producers and consumers. Producers capture real-time events and publish the messages to streaming platforms like Kafka. Consumers read the events published by producers and take action based on business requirements.
The following two use cases explore real-time streaming of data using the Internet of Things (IoT), sensors, and change data capture (CDC).
IoT Sensor Data Streaming
IoT sensors attached to a piece of equipment capture and measure certain physical properties and stream the measurements to a streaming platform for downstream processing.
For example, at designated intervals, a streaming producer collects sensor data from an automobile and sends it to a streaming platform in the cloud. This data is then ingested into a data lake by a consumer in real time for downstream analysis. Once the data is ingested to the raw layer, information is provided back to the automobile owner for maintenance purposes. In addition, curated data is used by the automotive manufacturer in support of various business processes.
Toyota streams sensor data every minute from its automobiles to AWS Kinesis for data lake ingestion, as shown below. This data is used for customer consumption and analytical analysis.
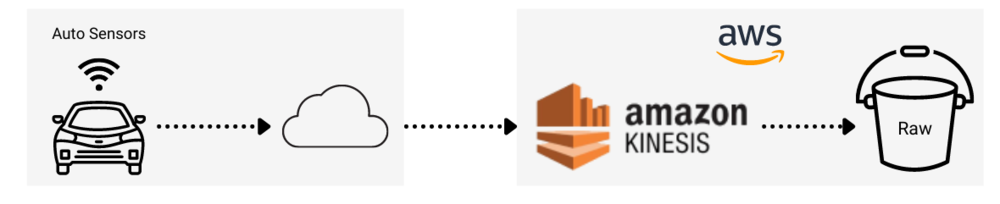
Figure 8. Real-time auto sensor data streaming to raw layer
CDC Database Event Streaming
CDC is a database-related solution that has been around since the 1990’s. CDC tracks all changes to a database in real time and maintains the original sequence of change events.
The original purpose of CDC was for database replication. Modern CDC software does much more than just replication. Producers take database change events and publish them to a streaming platform such as Kafka. Consumers can then read the data and ingest it into a data lake where real-time analytics can be performed.
Examples of CDC vendors are Informatica, Qlik, Oracle, and Striim. Kafka also provides CDC via its Open Connect offering and uses open source Debezium for CDC.
The following figure shows an example of CDC being used to stream on-premise database transactions to a data lake using Kafka.
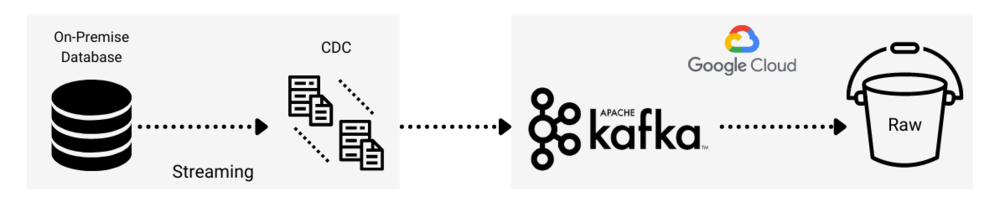
Figure 9. Real-time database transactions to raw layer
Summary
Building a data lake is a difficult journey, and having a well-designed data ingestion strategy is critical for a successful outcome. Sometimes customers do not have the expertise to define these strategies and implement them in house. That’s where Object Computing, Inc. (OCI) can help. OCI has extensive experience with data lakes and data ingestion strategies; we understand the key decisions that need to be made and can provide answers to questions like:
- What additional skill sets do I need when implementing a data lake ingestion strategy?
- When should I use batch data ingestion approaches?
- When should I use streaming data ingestion approaches?
- What software tools are right for my needs?
- What processes do I need to have in place?
- What do I need to have in place for my data scientists to become productive?
Choosing the right ingestion patterns and keeping them at a supportable level is key for architecting a well-designed ingestion solution and ultimately building a data lake that serves as a valuable asset to the organization.
References
- “Data lake”, Wikipedia, 2021, Data lake - Wikipedia.
- “Apache Kafka”, Apache Software Foundation, Apache Kafka
- Sandeep Kilkarni and Shravanthi Denthumas, “Enhancing customer safety leveraging the scalable, secure and cost-optimized Toyota Connected Data Lake”, AWS Big Data Blog, August 17, 2020, Automotive | AWS Big Data Blog (amazon.com)
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
