Capabilities of Google's Prediction API for Building Practical Machine-Learning Based Applications
By Srinivas Chakravarthi Thandu, OCI Software Engineer
FEBRUARY 2017
Introduction
Application development has come a long way since the days when programmers were limited to building applications on a single machine in a single location. Today, we build applications on remote infrastructures where we can leverage a variety of pre-built applications offered as services to help bolster our code and improve functionality.
For example, engineers can access many advanced machine-learning capabilities through fast, reliable, and cost-effective prediction API infrastructures.
Thus, as artificial intelligence (AI) and machine learning capabilities expand, those interested in building solutions enhanced by these powerful technologies can do so without worrying about the fault-tolerance and performance limitations of their own machines or developing the skills to tune machine learning algorithms.
Instead, we can invest our time building products that deliver results.
By incorporating the domain knowledge of an external machine-learning system and acting on the offerings (prediction results) from these APIs, we can create applications that provide extraordinary business value.
Prediction APIs
Several prediction APIs are currently available, including Amazon Machine Learning, Big ML, and Google Prediction API.
Because every prediction API differs in terms of services offered, no single standard metric can be used to evaluate and compare the performance of each one, although ProgrammableWeb’s Martin Brennan takes an admirable shot at doing so here.
An engineer with expert machine-learning knowledge and a thorough understanding of the specific context can identify which API, or combination of APIs, is most appropriate for a specific application; however this type of evaluation is beyond the scope of this article and will be addressed in a future one.
For the purposes of this article, we will describe the capabilities of the Google Prediction API and discuss the possibilities the Google's Prediction API offers with respect to a set of representative use cases.
Google Prediction API
Google’s Prediction API offers machine learning as a service. It learns from a user’s given training data and provides pattern-matching and machine-learning capabilities.
Google's black-box approach is intended to ease implementation for non-coders. The mathematical expertise required to build and analyze machine learning models is handled remotely by the API.
Traditionally, to implement a machine learning capability, you start by preprocessing your data. This involves dealing with missing data, input normalization, and splitting your dataset into training and validation sets.
Next comes model selection, in which you identify a model that fits your training data based on correlations in the features.
With the Google Prediction API, you don't need to worry about these steps because the API automatically trains and tests multiple complex models (tuned with different parameters) and chooses the best one for the final evaluation.
The model the Prediction API finally comes up with is the one you would have ended up with yourself, but only after multiple iterations tuning the model parameters. Even model evaluation is handled by the API.
What Does Google's Prediction API Do?
The Google Prediction API can predict a numeric or categorical value derived from the data provided in a training set. These capabilities open up a vast array of possibilities, ranging from spam detection to recommendation engines, all without building your own model.
The following is a representative set of use cases that can be built leveraging the capabilities of Google's Prediction API:
- Predict future trends from a given historical series of data
- Detect if a given email is a spam
- Recommend a product/movie to the user based on the interests of a similar user
- Identify whether a given user will default based on his or her credit history
- Detect activity from smartphones using labeled sensor datasets
On a given labeled dataset, given a new item, the Prediction API performs the following specific tasks:
- Predict a numeric value for that item, based on similarly valued examples in its training data (regression)
- Choose a category that describes it best, given a set of similarly categorized items in its training data (classification)
The bottom-line target for all the above-discussed applications is the ability to predict a world state parameter (target label value) for an unknown example based on past labeled data examples. The Prediction API will take care of building suitable models using Google’s fast and reliable computing resources.
Most prediction queries take less than 200ms.
How does the Prediction API work?
The implementation of the Google Prediction API is a black-box approach. In other words, there is no way to control the model-selection, model-tuning, and other training activities during training.
The model configuration is restricted to specifying the class of problem, whether it is "classification" or "regression" during the data preparation for the training process. At a very high level, the information flow in the Prediction API looks as shown in the following image.
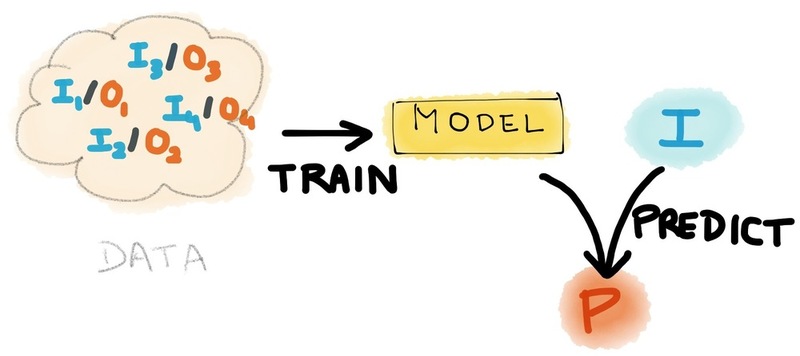
Information Flow of Prediction API
Input features can contain any type of data. The API does not impose any constraints on input-data types or any configuration process. The API takes care of value normalization, feature selection, and even missing values in the dataset.
The important step is data preparation; you must use the specified format the Prediction API accepts for training.
The training data looks as shown in the following figure. The data simply looks like a big table in which each record is an input data example. The label (target value) is specified in the first column in the training set; the only difference between a training set and a testing set is that the first column is not present in the testing set.
The biggest disadvantage with this type of implementation is that you cannot predict more than one world-state parameter (label) at the same time, which could otherwise be done with your own model implementation.
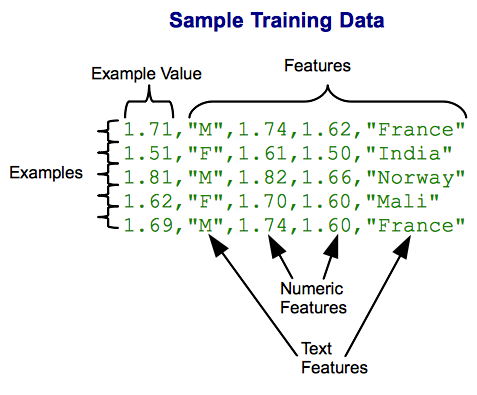
Sample Training Data
Getting Started with the Google Prediction API
For the Google Cloud Platform project, you will need to enable the Prediction API to build the model.
To use the Prediction API, the only cloud service required is “Cloud Storage,” which is enabled by default in your Google Cloud Platform project.
You are required to create a bucket in the location where your training set is uploaded. The Prediction API offers a simple way to train machine learning models through a RESTful interface.
To authorize the requests, your application must use “OAuth 2.0” protocol; the API does not support any other types of authorization protocol.
The application wrapping this model could use Google Sign-In for some aspects of authorization to the API. The detailed information on the authorization is given in Google OAuth documentation.
The mobile or web client implemented in order to make predictions with user-generated test data will call the methods specified in the RESTful API. The training phase is initialized by calling the trainedmodels.insert method.
The training phase is asynchronous, allowing you to poll the API using prediction.trainedmodels.get method to check the status of the training. In the response, when the trainingStatus property changes to "Done" from "Running," the model training is completed.
Only after this can you start making predictions for new data examples.
The API provides a trainedmodels.analyze method which specifies the modelDescription that contains the Confusion Matrix in the JSON format. It will not directly provide any additional statistics like precision, recall, or F-score, which you would have to calculate manually.
For the resulting model that the API builds, you can make predictions for new example datasets by calling trainedmodels.predict method. This returns the parameters outputLabel (numeric or String) and outputMulti which provide probability measures for each prediction class.
The API assigns final predicted labels based on a voting mechanism in which a class with the highest probability score is predicted as outputLabel.
The outputMulti is useful in making multiple predictions, for example: “top three predicted labels.”
The trained model remains until it is explicitly deleted. Apart from the training session, it does not continue to learn from the Predict queries.
The API provides a trainedmodels.update method which can be used to make update calls with additional examples. Applications that constantly fetch user data can take advantage of this method to achieve better performance by improving the models on a continuous basis.
Using a Hosted Model
The Prediction API enables customers to expose their models for paid use by other API users. If you have a specific problem and do not have time, resources, or expertise to build a model, you can draw from the gallery of user-submitted models, which are hosted here.
At the time of this article's publication, the gallery contains only models built by the Prediction API team itself; however future models may be a paid service or free to use, depending on the hosted owner.
As described in the documentation, the only method call supported on a hosted model is “predict.” The gallery will list the URL required for a prediction call to a specific model.
Note that hosted models are versioned; this means that when a model is retrained, it will get a new path that includes a new version number. You will need to periodically check the gallery to ensure that you're using the latest version of a hosted model. The model version number appears in the access URL. Different versions might return different scores for the same input.
Use case 1: Regression – Predicting the product rating from a review
To illustrate the use of the Prediction API for regression, a problem involving prediction of product rating (real-valued) for a given product review is demonstrated.
The traditional review problem aims at recommending products to a user based on that user's ratings and preferences. Here, the problem is approached in a kind of reverse format, which involves predicting a reasonable rating for a given user product review using the model trained from Amazon food product review data which can be found here.
For working with a machine learning problem, one of the most important and time-consuming aspects is defining the problem appropriately and preparing the dataset accordingly.
Before all that, the problem should be analyzed and assessed to ensure that it is appropriate for a machine learning approach in the first place. After all, not every problem is solvable using machine learning.
There are two main things you need to clarify before starting the problem:
- Determine if the problem requires regression or classification, and clearly identify what you are going to predict/classify.
- Identify all necessary assumptions, ensuring they do not affect the scope of the problem.
For the current situation, since we are going to predict a rating which is a real value, this is clearly a regression problem.
The second point above is important, as you can have redundant data which will, in turn, affect model accuracy.
A detailed description of the scope of machine learning algorithms was described in our February 2015 SETT article, which can be found here.
Typically, if the features are too specific to the current dataset, you may end up with a large generalization error resulting in overfitting.
This is the piece you need to handle yourself to better assist the Prediction API in predicting accurate labels for your test inputs. Although this preprocessing step is not mandatory for using Prediction API, you need it to build a good model corresponding to your training set.
The dataset chosen for the current problem contains 568,454 product reviews collected from 256,059 users for 74,258 products.
Each row represents a product review, and each column represents a meta-data corresponding to the review.
Often, columns that are not of interest to a specific problem may be included, so filtering those and including only relevant features will lead to a better model.
Accordingly, we prepare our data and make sure to include the label in the first column as mentioned in the API documentation.
At this point, each row consists of a rating, a review-summary, and review-text.
We now set up the project, which involves three steps:
- Create a Google Cloud Platform project (you can also build on top of an existing one).
- Enable billing.
- Enable the Prediction API for the project.
Note: A globally unique project id is chosen for the project name, and a number is assigned when the Google Cloud Platform project is created. Detailed descriptions of these steps are provided here.
Next, you must create a bucket with a globally unique name and add the training set file as a 'CSV' file to the bucket.
For training the model, the prediction.trainedmodels.insert method is called, passing a unique name for this predictive model and the bucket location of the training data, which is shown below.
A full list of the methods is available here.
- POST https://www.googleapis.com/prediction/v1.6/projects/oci-analytics/
- trainedmodels?key={YOUR_API_KEY}
- {
- "id": "rating-predictor",
- "storageDataLocation": "oci-prediction_api-demo/product_reviews_amazon.csv"
- }
A successful response looks like:
- {
- "kind": "prediction#training",
- "id": "rating-predictor",
- "selfLink": "https://www.googleapis.com/prediction/v1.6/projects/
- oci-analytics/trainedmodels/rating-predictor",
- "storageDataLocation": "oci-prediction_api-demo/product_reviews_amazon.csv"
- }
Response to the training request
To check the status of Training, use the prediction.trainedmodels.get method by passing the ID of the predictive model as shown below.
- GET https://www.googleapis.com/prediction/v1.6/projects/oci-analytics/
- trainedmodels/rating-predictor?key={YOUR_API_KEY}
Querying about the status of training
After the training is complete, you can send queries to the service to be evaluated against the predictive model.
To do so, call the prediction.trainedmodels.predict method, passing the name of the model and the query.
In the below query "product seems ok" corresponds to review-summary attribute and "it should have looked as expected.. packing was not firm.. overall it tastes just ok" corresponds to review-text attribute.
- POST https://www.googleapis.com/prediction/v1.6/projects/oci-analytics/
- trainedmodels/rating-predictor/predict?key={YOUR_API_KEY}
- {
- "input": {
- "csvInstance": [
- "product seems ok, it should have looked as expected.. packing was not
- firm.. overall it tastes just ok"
- ]
- }
- }
Sending a prediction query to the Prediction API
- {
- "kind": "prediction#output",
- "id": "rating-predictor",
- "selfLink": "https://www.googleapis.com/prediction/v1.6/projects/
- oci-analytics/trainedmodels/rating-predictor/predict",
- "outputValue": "3.756272"
- }
Prediction response containing the prediction label and probability scores
Use case 2: Classification – Sentiment analysis
To illustrate the use of the Prediction API for classification, a simple binary classification problem is shown to classify positive or negative sentiment based on the Twitter sentiment analysis corpus dataset found here.
For the current problem, since we are going to identify a predefined label Negative or Positive, this is a classification problem.
The dataset chosen for the current problem contains about 1.5 million rows and 4 columns. A classification model is built and the following demonstrates the classification scenario on the resultant model:
- POST https://www.googleapis.com/prediction/v1.6/projects/oci-analytics/
- trainedmodels/sentiment-identifier_12500/predict?key={YOUR_API_KEY}
- {
- "input": {
- "csvInstance": [
- "I am worried about today's game..."
- ]
- }
- }
Sending a prediction query to the Prediction API
- {
- "kind": "prediction#output",
- "id": "sentiment-identifier_12500",
- "selfLink": "https://www.googleapis.com/prediction/v1.6/projects/
- oci-analytics/trainedmodels/sentiment-identifier_12500/predict",
- "outputLabel": "NEGATIVE",
- "outputMulti": [
- {
- "label": "NEGATIVE",
- "score": "0.696235"
- },
- {
- "label": "POSITIVE",
- "score": "0.303765"
- }
- ]
- }
Prediction response containing the prediction label and probability scores
Conclusions
As of now, the Google Prediction API provides a machine learning capability that is abstracted and simplified substantially for developers.
The control is only in data preparation and adding additional datasets to update the model. These activities represent the start- and end-points in the machine learning pipeline.
Key advantages of this approach are that it saves a lot of time in building models, and it provides flexibility for adding additional datasets, even after the training is completed, enabling simple model updates on the fly.
If you have any questions, please feel free to call Kevin Stanley, OCI's Analytics and Data Engineering practice leader, at 314-590-0258.
Acknowledgements
I want to thank my colleagues Yong Fu, Huang-Ming Huang, Kevin Stanley, Mike Martinez, and Carl Turza from OCI for very useful and professional comments that greatly improved the quality of this article.
References & Further Reading
- Watson API - Developer Kit
- Amazon Machine Learning Using Amazon Redshift as a Data Source
- Microsoft Azure Machine Learning Studie (Azure ML)
- Overview of Google Cloud Machine Learning.
- Welcome to Machine (Learning), SETT Article, February 2015.
Software Engineering Tech Trends (SETT) is a regular publication featuring emerging trends in software engineering.
