
By Madison Koehler
Imagine having a conversation with your dataset as if you were talking to a colleague, gaining insights by simply asking questions. With generative AI, this is entirely possible. In the era of conversational chatbots, businesses are beginning to think about how these can be leveraged to harness the full potential of their data. Traditional methods for extracting insights from data often require special skills and are time-consuming. Using Gen AI models to “chat” directly with our data makes these data insights more accessible and actionable, revolutionizing the way data-driven decisions are made.
While many people tend to think of Gen AI models like ChatGPT as a sort of ‘search engine’, tech leaders recognize the potential to tap into their company’s own proprietary data. Large language models (LLMs) in isolation only know what they have been trained on. Proprietary data and documents published after the model’s training are unknown to out-of-the-box LLMs.
This article discusses the concept of “chatting with your data.” It is an approach to integrate proprietary, sensitive data with LLMs such that users securely engage in natural-language conversations with their datasets and unlock the data’s full potential with less manual effort. It specifically focuses on chatting with “messy” unstructured data such as PDF documents, raw text, CSV, or JSON files. Furthermore, it includes an overview of how LangChain, a popular open-source framework, easily jumpstarts your chats.
Why Chat with Your Data?
“Chatting with your data” presents valuable opportunities to automate workflows, democratize data access, and accelerate the monetization of data insights. Leveraging Gen AI in this way allows for Q&A sessions with a dataset, and also the ability to automate mundane tasks like summarizing or translating documents. There are numerous benefits associated with the ability to understand and transform data simply by having a natural language conversation.
- Automate and accelerate workflows: Chatting with data is an effective way to accelerate workflows and automate some of the more mundane processes that humans spend time doing manually. The focus is on acceleration with human oversight rather than replacing humans altogether. By taking away the boring and repetitive tasks, time is freed up for data professionals to focus on the more creative, innovative, and decision-making aspects of their roles. This is comparable to the role of spellcheck in word processors — it didn’t replace the need for humans to write the content, but it saved time and improved quality.
- Empower more people to interact with the data: Through conversational interfaces, this approach empowers a broader spectrum of users, including non-technical stakeholders, to interact with and derive insights from the data in real time. Making complex datasets more accessible and understandable will foster more collaboration across teams.
- Quick insights to unlock the value of data assets: Harnessing the time-save provided by this automation allows organizations to extract valuable data insights quickly, translating them into actionable strategies at an accelerated pace.
Unlock Conversational Data Interactions with RAG
Chatting with data has many benefits, but how can a model perform tasks and analysis on data it hasn’t seen during training? Enter Retrieval Augmented Generation (RAG), a technique for enhancing a model’s abilities by referencing an external knowledge base beyond the information it was trained on. This technique enables users to provide an LLM with a proprietary dataset and make queries about the data or assign tasks to the LLM, receiving informed responses in real time.
To most effectively utilize RAG, it is good practice to split unstructured data like text documents into semantically meaningful chunks. This allows the LLM to search for the most relevant chunk related to the user’s query and use only the most relevant information to generate a helpful response. Splitting a document involves steps of tokenization and vector storage that will be discussed later in the article.
Once a user makes a query, the RAG system retrieves the relevant information from the vector store and uses its natural language abilities to generate a helpful response. This is the power of RAG, bridging the gap between data exploration and response generation to facilitate more nuanced and insightful conversations between a user and their data.
Steps for Retrieval Augmented Generation (RAG) with LangChain
Preparing Your Data to Chat
While generative AI models require less polished and meticulously cleaned data than traditional machine learning models, effective data preparation is still an essential step to maximize the potential of RAG. To get the most out of RAG, there are some standard steps to prepare unstructured data such as text documents.
- Meaningful tokenization (splitting): LLMs have associated token limits. This is a number of tokens (usually characters but can also be parts of words or entire words) that can be entered into the model’s context window. For this reason, it is often infeasible to pass an entire large document into the LLM along with our prompt (question or task). To avoid hitting token limits and receiving an error following a query, a common practice is to split documents into smaller sub-documents, reducing the number of tokens per “document.” It is good practice to split documents into chunks that are semantically meaningful, keeping groups of relevant tokens (words, sentences, paragraphs, etc) together. This helps the RAG process return the data that is most relevant to the query at hand.
- Embedding: Embedding text data for RAG is the process of transforming the natural language text that humans use into numeric representations that the LLM can understand. These are high-dimensional vector representations of text that capture semantic meaning and contextual relationships between tokens. This enables similarity computations and the retrieval of the most relevant information by comparing the data’s embeddings to those of the user’s query.
- Vector store: Storing embeddings in a vector store facilitates the retrieval of documents or document chunks that are the most semantically similar to the user’s query. This ensures that only the most relevant information is considered when the LLM generates its response.
These are the essential steps to preparing data for RAG systems, leading to the most accurate responses and most accessible insights.
Crafting Data Dialogues: The Art of Effective Prompt Design with RAG
A prompt is a request sent to an LLM to receive a response back, and prompt design is the process of creating prompts that elicit the desired response. Effective prompt design is essential to ensuring helpful, accurate, and well-structured responses from language models. It is important to make sure the model understands what is being requested of it and has clear guidelines to respond in a way that is most helpful to the user and meets their expectations. Beyond the short query that the user submits to the model (like in interactions with ChatGPT), PromptTemplates are often used to provide the model with the most information possible about the expectations for the generated response.
PromptTemplates integrate nicely with RAG because they can be used to instruct the model to only make use of the designated data store when generating answers. While prompts can contain questions, they can also be constructed to instruct the model to take on an assignment. Examples of such tasks include summarizing, editing, switching text to a different tense or tone, or generating new text. Prompt templates are excellent ways to designate between question-answer and task-based instructions for the model.
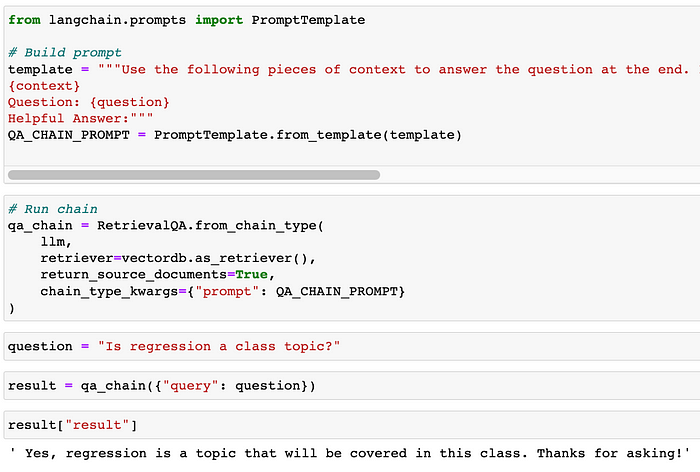
The following shows the creation of a PromptTemplate for a question/answer interaction with a dataset consisting of transcripts from lectures in a machine learning course. Note how the template provides placeholders for not only the query, but the useful context to inform the response.
Demonstration of a PromptTemplate being used in a RetrievalQAChain to answer queries.
Prompt design is an essential part of creating a RAG system. The following are some tips for ensuring more effective prompt design:
- Give clear and specific instructions to the model. Define the task and any constraints, or even the format the response should be given in (e.g. a bulleted list, a five-sentence paragraph, or a JSON file)
- Include few-shot examples. Give the model a few examples of similar prompts and expected responses, so it can learn how to respond in the desired format. “Few-shot” prompting is a common technique that provides the model with the expectations for how similar queries should be responded to.
- Break down complex prompts into individual steps. A prompt could contain a list of steps for the model to take in a particular order to best complete the request.
- Experiment with wording and tone. Altering prompts to guide the model toward the expected behavior can be helpful.
Putting it All Together with LangChain
LangChain is an open-source framework for developing applications using LLMs. LangChain comes equipped with modules and end-to-end templates that make it easy to quickly implement each step of the “chat with your data” approach.
To make data preparation simple with unstructured data, LangChain provides a variety of document loaders, configurable document splitters, embedding strategies (including those assisted by an LLM), and supported vector stores.
For data retrieval during the RAG process, LangChain provides several Retrievers — a class of objects that can be used to configure a RAG strategy dependent on use case. For example, if hitting token limits is an issue, the ContextualCompresionRetriever can be used to retrieve only the most relevant portions of a document chunk to further reduce the number of context tokens being passed into the LLM.
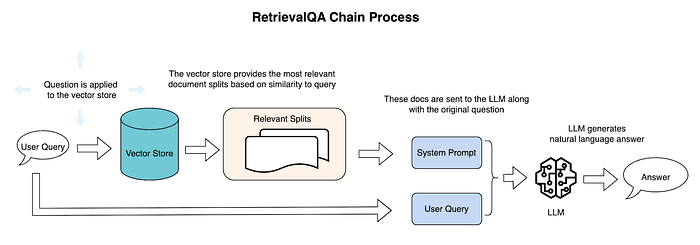
Chains are a valuable feature of LangChain that encapsulate sequences of interconnected components that execute in a specific order. There are several use-case-specific options for chains to use, and custom chains can be created as well. For example, the RetrievalQAChain is designed to facilitate RAG for question/answer-based exchanges with an LLM. Chains can easily be integrated with a preferred retriever, LLM, and vector database. Chains can also be joined together in sequences for more complex workflows, and Router Chains can be leveraged as a tool to decide which of multiple chains is best suited to handle a given query. Ultimately, chains provide a framework to implement a chat-with-your-data workflow with minimal lines of code.
Steps executed in LangChain’s RetrievalQAChain Class

Ultimately, LangChain’s modularization of useful components that can be strung together into chains makes the framework an effective tool for implementing RAG systems to chat with a dataset.
Going from Q/A to ChatBot
Asking questions or making requests to the LLM in a one-at-a-time manner is sufficient for several use cases. When a more conversational structure would be beneficial, such as for a customer-service chatbot that needs to remember conversation history, LangChain provides tools for these use cases as well. This structure looks similar to the chains explored previously but will involve the addition of a “memory” of sorts for the LLM to reference context from previous chats in future responses. This allows for follow-up questions or requesting refinements or edits to a previously completed task.
The following example shows an application of this when having a conversation with lecture transcripts from a machine learning course. The ChatBot uses these transcripts to answer a question, then uses the transcripts plus the conversation history to answer a follow-up question. Note that in the second question, TAs are not mentioned, but the ChatBot uses the context of the previous question to understand that those are the people whose majors are being referred to.
Example of ChatBot using conversational history to answer a follow-up question
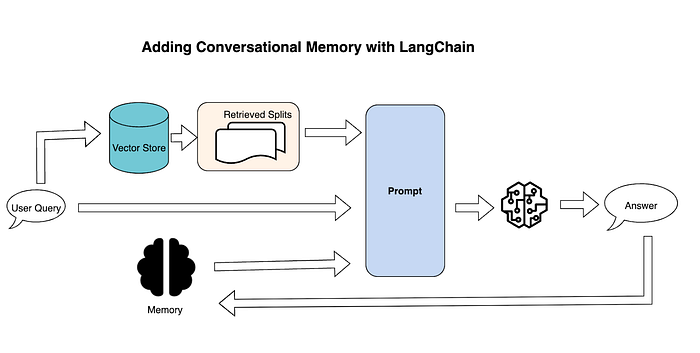
LangChain provides a variety of options for conversation memory. One example is “conversation buffer memory,” which simply keeps a list of chat messages in history and passes those along with the question to the chatbot each time. Using this, a new chain (i.e. ConversationalRetrievalChain) can be created from building upon the initial RetrievalQAChain with the addition of the memory component.
LangChain’s implementation of conversational memory
Data Security Considerations
RAG is a powerful technique, but it is important to ensure that applications that utilize RAG are used safely, without compromising data integrity. The following are key best practices to consider when implementing a RAG system to chat with data.
- Encryption of data in transit and at rest: Utilizing industry-standard data encryption protocols is a good way to ensure sensitive information is protected both in transmission and while being stored.
- Access controls and authentication: Implementing different levels and scope of access to the RAG system is a good way to ensure that only authorized users can interact with the system and access sensitive data.
- Data anonymization: Employing anonymization is an effective way to protect sensitive information within the data. Anonymization includes actions like removing personally identifiable information (PII) from the data and using anonymized identifiers to prevent the identification of individuals. Masking data in this way will also help protect this sensitive information from being stored by an LLM from a third party API, like OpenAI.
Takeaways & Next Steps for the Future
Turning proprietary, unstructured data into a conversational agent that empowers users to accelerate workflows and increase the accessibility of quick, actionable data insights.
Some considerations for future improvements include:
- Fine-tuning: Continuously fine-tuning the parameters of the RAG model can help improve response quality and relevance. Fine-tuning can be helpful at the data prep strategy, with prompt design, or with other LLM parameters.
- User interface: Integrating this process with a user interface can make having data interactions more convenient, leading to more accessibility for RAG systems to enable more people to chat with their datasets.
- Experiment with more retrieval techniques: Experimenting with additional retrieval techniques such as re-ranking could help the model construct more helpful responses that make the most effective use of the provided data.
If you’re intrigued by the concept of ‘chatting with your data’, our team can help you turn this concept into reality. Learn about our AI and data insights expertise, check out our recent webinars, and be sure to follow us on Medium for upcoming content.
Additional Resources:
Madison Koehler, Data Scientist at Object Computing, obtained her MS in Artificial Intelligence in 2022 and has spent the last two years kicking off her career as a data scientist. She utilizes a strong background in mathematics, statistics, and computer science to create data-driven insights in the machine learning and deep learning space, and has utilized cloud service providers such as Amazon Web Services (AWS) to build and optimize large-scale pipelines spanning the entire machine learning lifecycle.
